소라 출시 이후 AI 영상 세대 분야는 더욱 '바빠졌다'. 지난 몇 달 동안 우리는 Jimeng, Runway Gen-3, Luma AI 및 Kuaishou Keling이 차례로 폭발하는 것을 목격했습니다. 한눈에 AI가 생성한 것으로 식별할 수 있는 이전 모델과 달리, 이번 대규모 비디오 모델 배치는 우리가 본 것 중 "최고"일 수 있습니다. 그러나 비디오 대형 언어 모델(LLM)의 놀라운 성능 뒤에는 매우 높은 비용이 필요한 거대하고 세밀하게 주석이 달린 비디오 데이터 세트가 있습니다. 최근 연구 분야에서는 추가 훈련이 필요하지 않은 혁신적인 방법이 많이 등장했습니다. 훈련된 이미지 대형 언어 모델을 사용하여 비디오 작업을 직접 처리함으로써 "비용이 많이 드는" 훈련 과정을 우회하는 것입니다. 또한 대부분의 기존 비디오 LLM에는 두 가지 주요 단점이 있습니다. (1) 제한된 수의 프레임으로 비디오 입력만 처리할 수 있으므로 모델이 미묘한 공간적, 시간적 콘텐츠를 캡처하기 어렵습니다. (2) 시간 모델링 설계가 부족하지만 LLM의 모션 모델링 기능에 전적으로 의존하여 비디오 기능을 LLM에 입력합니다. 위 문제에 대응하여 Apple 연구진은 SlowFast-LLaVA(약칭 SF-LLaVA)를 제안했습니다. 이 모델은 Byte 팀이 개발한 LLaVA-NeXT 아키텍처를 기반으로 하며 추가적인 미세 조정이 필요하지 않으며 바로 사용할 수 있습니다. 동작 인식 분야의 성공적인 2스트림 네트워크에서 영감을 받아 연구팀은 비디오 LLM을 위한 새로운 SlowFast 입력 메커니즘을 설계했습니다. 간단히 말하면 SF-LLaVA는 두 가지 관찰 속도(느림 및 빠름)를 통해 영상의 세부 사항과 움직임을 이해합니다.
- 느린 경로: 가능한 한 많은 공간 세부 정보를 유지하면서 낮은 프레임 속도에서 특징을 추출합니다(예: 8프레임마다 24×24 토큰 유지)
- 빠른 경로: 높은 프레임 속도로 실행하지만 사용 더 큰 시간적 맥락을 시뮬레이션하고 행동의 일관성을 이해하는 데 더 집중하기 위해 비디오의 해상도를 줄이기 위한 더 큰 공간 풀링 단계 크기
이것은 두 개의 "눈"을 가진 모델과 동일합니다: 하나 그냥 보세요 천천히 그리고 세부 사항에 주의를 기울이십시오. 다른 하나는 빠르게 살펴보고 움직임에 주의를 기울이는 것입니다. 이는 대부분의 기존 비디오 LLM의 문제점을 해결하고 상세한 공간 의미와 더 긴 시간적 맥락을 모두 캡처할 수 있습니다. 
논문 링크: https://arxiv.org/pdf/2407.15841실험 결과에 따르면 SF-LLaVA는 모든 벤치마크 테스트에서 상당한 이점을 통해 기존 훈련 없는 방법을 능가하는 것으로 나타났습니다. 신중하게 미세 조정된 SFT 모델과 비교하여 SF-LLaVA는 동일하거나 더 나은 성능을 달성합니다.
아래 그림과 같이 SF-LLaVA는 교육이 필요 없는 표준 비디오 LLM 프로세스를 따릅니다. 비디오 V와 질문 Q를 입력으로 받아 해당 답변 A를 출력합니다.
Pour l'entrée, N images sont uniformément échantillonnées à partir de chaque vidéo de n'importe quelle taille et longueur, I = {I_1, I_2, ..., I_N}, et aucune combinaison ou disposition particulière des images vidéo sélectionnées n'est requise. La caractéristique de fréquence extraite indépendamment dans l'unité de trame est F_v ∈ R^N×H×W, où H et W sont respectivement la hauteur et la largeur de la caractéristique de trame. La prochaine étape consiste à traiter davantage F_v selon des chemins lents et rapides et à les combiner pour former une représentation vidéo efficace. Le chemin lent échantillonne uniformément les caractéristiques du cadre de à partir de F_v, où . Des recherches antérieures ont montré qu'une mise en commun appropriée dans la dimension spatiale peut améliorer l'efficacité et la robustesse de la génération vidéo. Par conséquent, l’équipe de recherche a appliqué un processus de pooling avec un pas de σ_h×σ_w sur F_v pour obtenir la caractéristique finale : , où , . L’ensemble du processus du chemin lent est illustré dans l’équation 2.
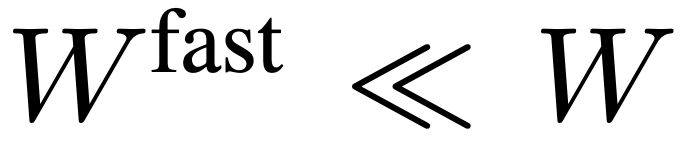
Le chemin rapide préserve toutes les fonctionnalités d'image dans F_v pour capturer autant que possible le contexte temporel à longue portée de la vidéo. Plus précisément, l’équipe de recherche utilise un pas de regroupement spatial pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale . L'équipe de recherche a mis en place , afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3.
Enfin, les caractéristiques vidéo agrégées sont obtenues : , où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression, ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de jetons vidéo. Les caractéristiques visuelles de la vidéo seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement. Le processus SlowFast est illustré dans l'équation 4.
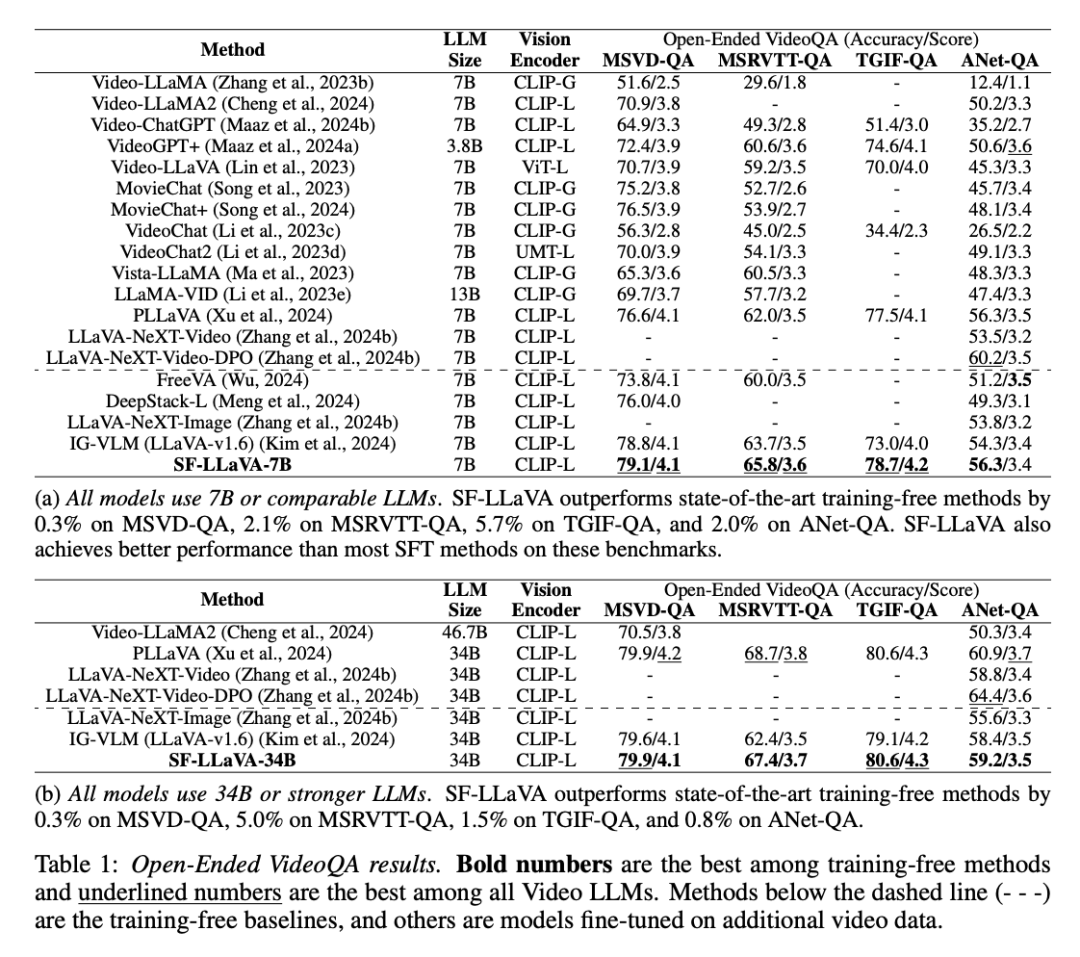
L'équipe de recherche a mené une évaluation complète des performances de SF-LLaVA, en le comparant aux modèles SOTA actuels sans formation (tels que IG-VLM et LLoVi) dans plusieurs tâches de réponse à des questions vidéo. En outre, ils l’ont comparé à des LLM vidéo tels que VideoLLaVA et PLLaVA qui ont été supervisés et affinés (SFT) sur des ensembles de données vidéo. Réponse aux questions vidéo ouvertesComme le montre le tableau ci-dessous, dans la tâche de réponse aux questions vidéo ouvertes, SF-LLaVA fonctionne mieux que les méthodes sans formation existantes dans tous les benchmarks. Plus précisément, lorsqu'il est équipé de LLM de tailles de paramètres respectivement 7B et 34B, SF-LLaVA est 2,1 % et 5,0 % plus élevé que IGVLM sur MSRVTT-QA, 5,7 % et 1,5 % plus élevé sur TGIF-QA et 5,7 % et 1,5 % plus élevé sur ActivityNet -2,0% et 0,8% plus élevé sur le QA. Même par rapport à la méthode SFT affinée, SF-LLaVA affiche des performances comparables dans la plupart des benchmarks, uniquement sur le benchmark ActivityNet-QA, PLLaVA et LLaVA-NeXT-VideoDPO surpassent légèrement One chip.
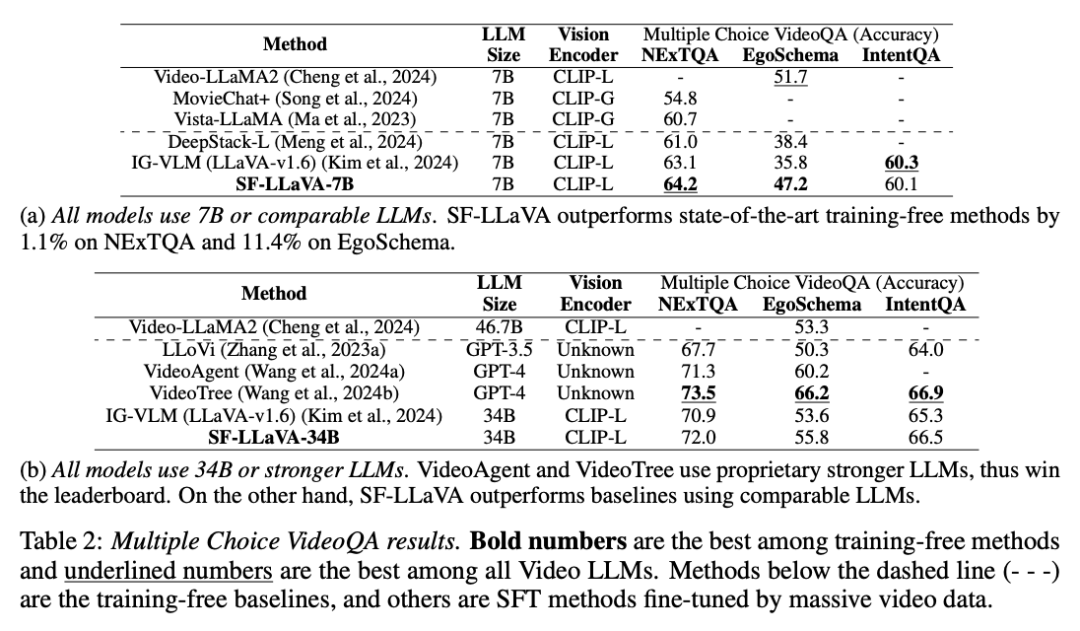
Questions et réponses vidéo à choix multiplesComme le montre le tableau ci-dessous, SF-LLaVA surpasse les autres méthodes sans formation en matière de questions et réponses vidéo à choix multiples dans tous les benchmarks. Dans l'ensemble de données EgoSchema, qui nécessite un raisonnement complexe à long terme, les versions SF-LLaVA7B et 34B ont obtenu des scores supérieurs de 11,4 % et 2,2 % à ceux du modèle IG-VLM, respectivement. Bien que VideoTree soit en tête des benchmarks car il s'agit d'un modèle propriétaire basé sur GPT-4, les performances sont bien supérieures à celles du LLM open source. Le modèle SF-LLaVA 34B obtient également de meilleurs résultats sur EgoSchema par rapport à la méthode SFT, ce qui confirme la puissance de la conception SlowFast dans la gestion de vidéos longues.
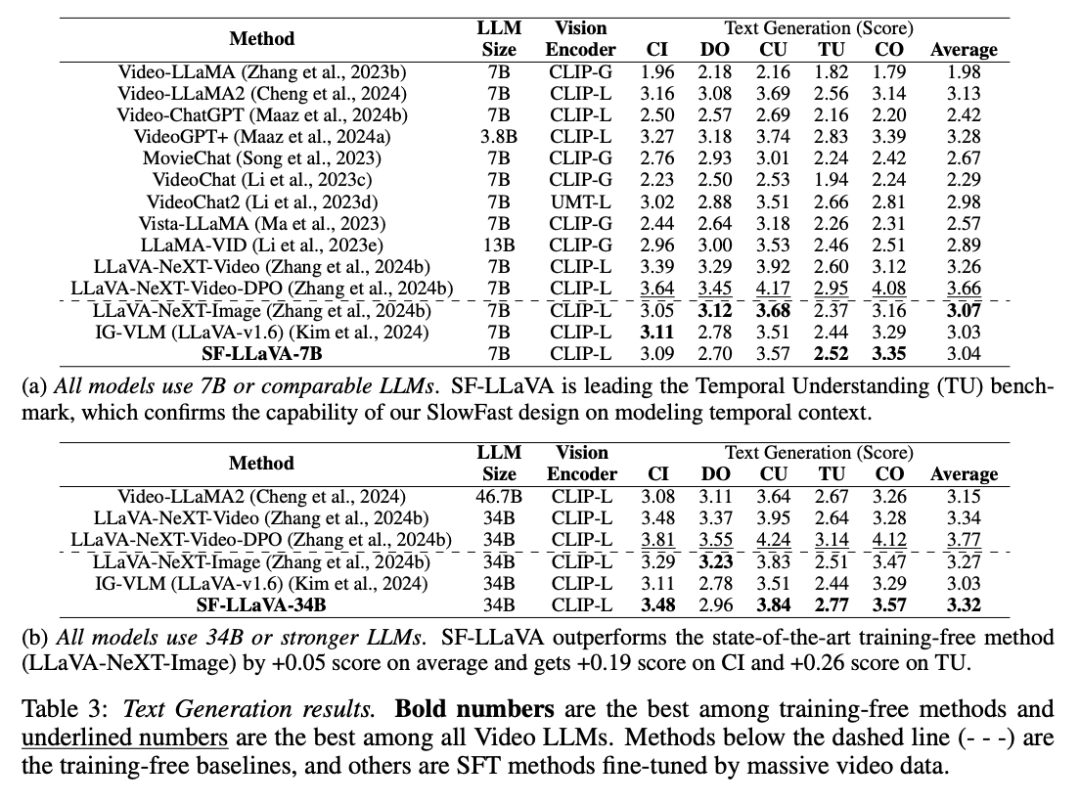
Comme le montre le tableau 3, pour la tâche de génération de texte vidéo, SF-LLaVA présente également certains avantages. Le SF-LLaVA-34B a dépassé toutes les références sans formation en termes de performances globales. Bien qu'en termes d'orientation des détails, SF-LLaVA soit légèrement inférieur à LLaVA-NeXT-Image. Basé sur la conception SlowFast, SF-LLaVA peut couvrir un contexte temporel plus long avec moins de jetons visuels et est donc particulièrement performant dans les tâches de compréhension temporelle. De plus, SF-LLaVA-34B surpasse également la plupart des méthodes SFT en termes de performances vidéo Vincent.
Pour plus de détails, veuillez vous référer au document original. 위 내용은 비디오 모델에 빠르고 느린 눈을 추가하면 훈련이 필요 없는 Apple의 새로운 방법이 모든 SOTA를 몇 초 만에 능가합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




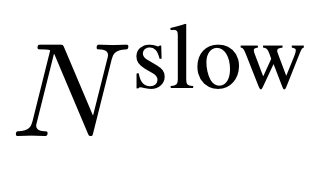 à partir de F_v, où
à partir de F_v, où 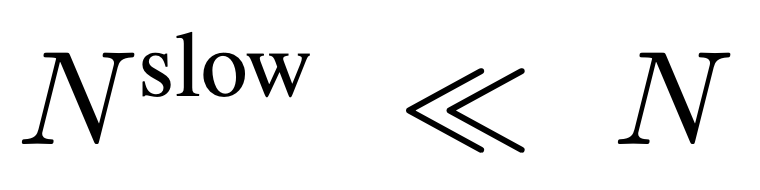 .
. 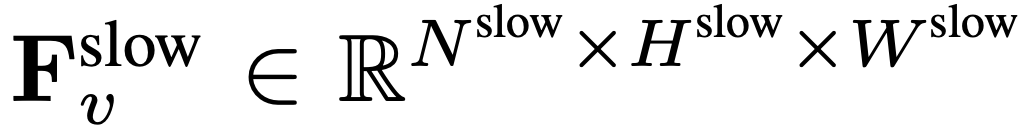 , où
, où 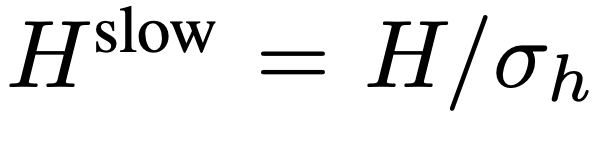 ,
, 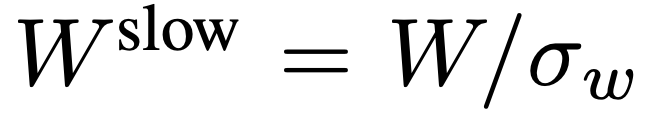 . L’ensemble du processus du chemin lent est illustré dans l’équation 2.
. L’ensemble du processus du chemin lent est illustré dans l’équation 2. 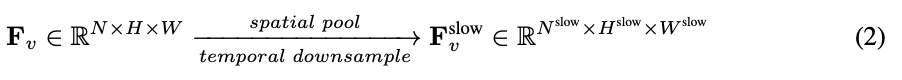
 pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale
pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale 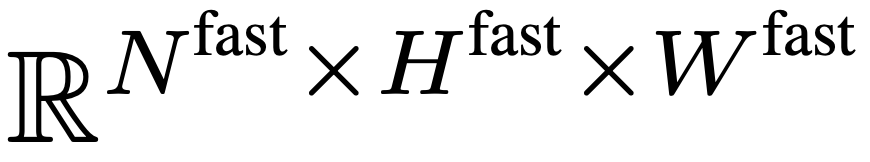 . L'équipe de recherche a mis en place
. L'équipe de recherche a mis en place  ,
,  afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3.
afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3. 
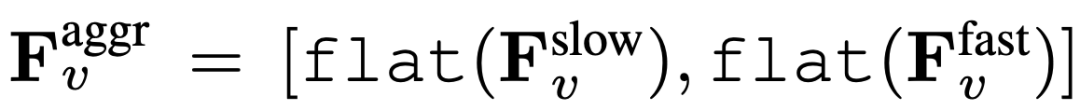 , où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression,
, où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression, 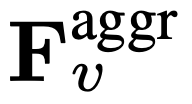 ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de
ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de 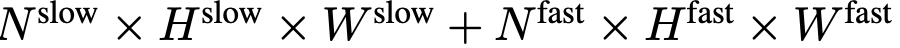 jetons vidéo. Les caractéristiques visuelles de la vidéo
jetons vidéo. Les caractéristiques visuelles de la vidéo 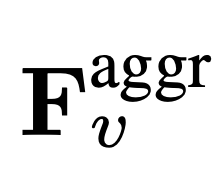 seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement.
seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement. 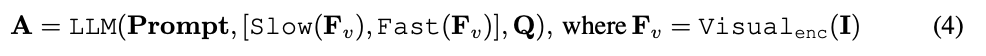

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



