

대형 모델이 출시되고 가속 버튼을 누르면서 빈첸시오 다이어그램은 의심할 여지 없이 가장 뜨거운 적용 방향 중 하나입니다.
Stable Diffusion이 탄생한 이후 국내외에 Wen Shengtu의 대형 모델이 끝없이 쏟아져 나와 한동안 "신들 사이의 싸움"처럼 느껴졌습니다. 불과 몇 달 사이에 '최강 AI 아티스트'라는 타이틀이 여러 번 바뀌었습니다. 모든 기술 반복은 AI 이미지 생성 품질과 속도의 상한선을 계속해서 확장하고 있습니다.
이제 몇 단어만 입력하면 원하는 사진을 얻을 수 있습니다. 전문가 수준의 광고 포스터든 초현실적인 사진이든 AI 매핑의 충실도는 우리를 놀라게 했습니다. 심지어 AI도 2023년 소니 월드 사진상을 수상했습니다. 대상 발표 전 이 '사진'은 런던 서머셋 하우스에 전시된 바 있다. 만약 작가가 이를 공개적으로 공개하지 않는다면 그 사진이 실제로 AI가 만든 사진인지 누구도 알 수 없을 것이다. E Eldagse와 그의 AI 세대 작품 "Electrician"
 AI가 그린 그림을 더 아름답게 만드는 방법은 AI 기술자의 인내와 불가분의 관계입니다.
AI가 그린 그림을 더 아름답게 만드는 방법은 AI 기술자의 인내와 불가분의 관계입니다. 라이브 방송이 시작되었습니다. Li Liang은 먼저 최신 '최고급' 국내 대형 모델, 즉 ByteDance Doubao 대형 모델의 Vincent 다이어그램 모델의 기술 업그레이드를 자세히 분석했습니다.
Li Liang은 Doubao 팀이 해결하고 싶은 문제는 주로 세 가지 측면을 포함한다고 말했습니다. 첫째, 사용자의 아이디어 디자인에 맞게 보다 강력한 이미지와 텍스트 매칭을 달성하는 방법, 둘째, 보다 궁극적인 제공을 위해 보다 아름다운 이미지를 생성하는 방법; 세 번째는 초대형 서비스 요청에 맞게 사진을 더 빠르게 생성하는 방법입니다. 이미지와 텍스트 매칭 측면에서 Doubao 팀은 데이터로 시작하여 방대한 이미지와 텍스트 데이터를 정제하고 필터링한 후 마침내 수천억 개의 고품질 이미지를 데이터베이스에 저장했습니다. 또한 팀은 요약 작업을 위해 다중 모드 대형 언어 모델도 특별히 훈련했습니다. 이 모델은 사진 속 이미지의 물리적 관계를 보다 포괄적이고 객관적으로 설명합니다.
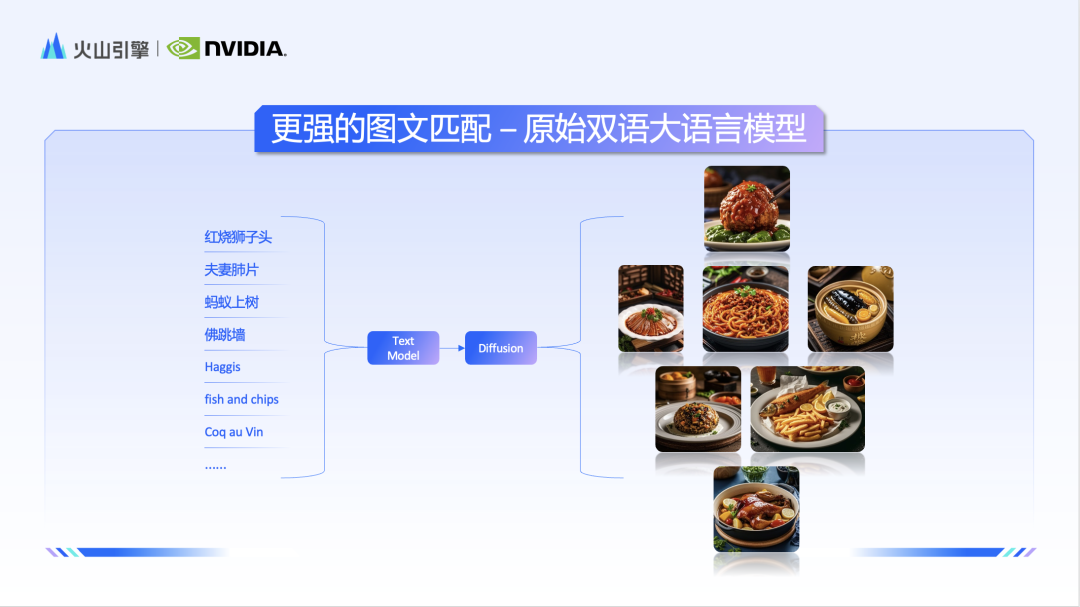
고품질, 고해상도의 이미지와 텍스트 데이터를 확보한 후, 모델의 강점을 더욱 잘 활용하려면 텍스트 이해 모듈의 능력을 향상시켜야 합니다. 팀은 네이티브 이중 언어 대형 언어 모델을 텍스트 인코더로 사용하여 모델의 중국어 이해 능력을 크게 향상시켰습니다. 따라서 "당나라" 및 "등불 축제"와 같은 국가적 요소에 직면하여 Doubao 및 Vincent 다이어그램 모델을 사용했습니다. 또한 더 깊은 이해를 보여줍니다.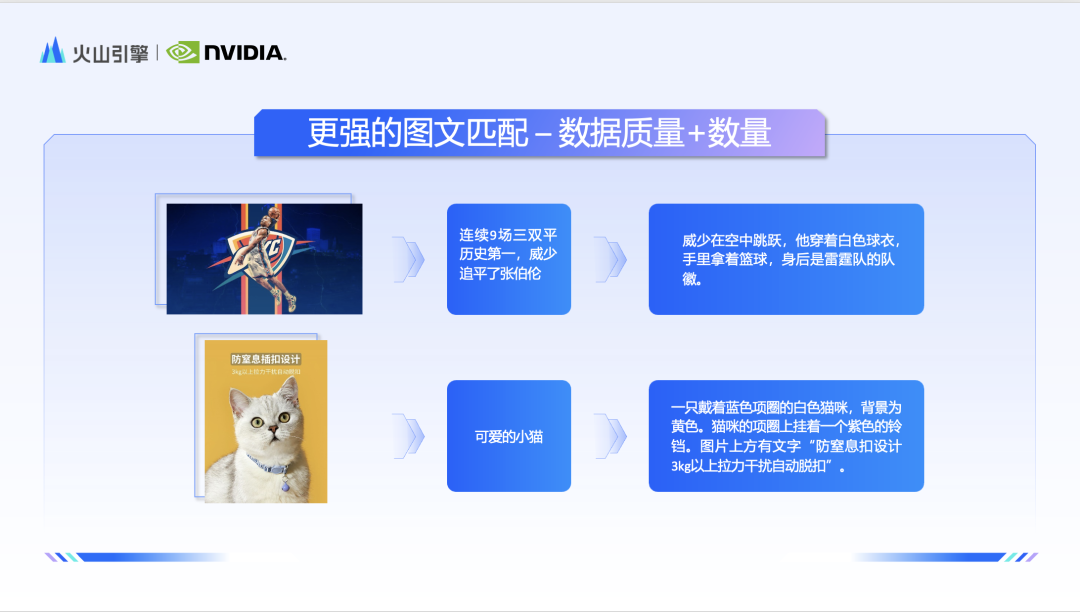
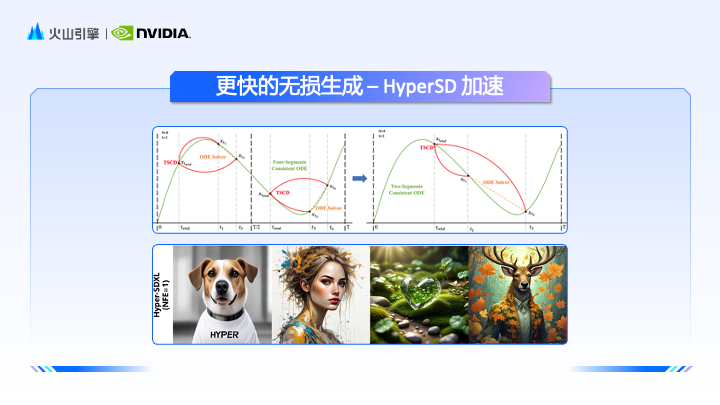
接下來,英偉達解決方案架構師趙一嘉從底層技術出發,講解了文生圖最主流的基於Unet的SD和DIT兩種模型架構及其相應的特性,並介紹了英偉達的Tensorrt, Tensorrt- LLM, Triton, Nemo Megatron 等工具如何為部署模型提供支持,助力大模型更有效率地推理。
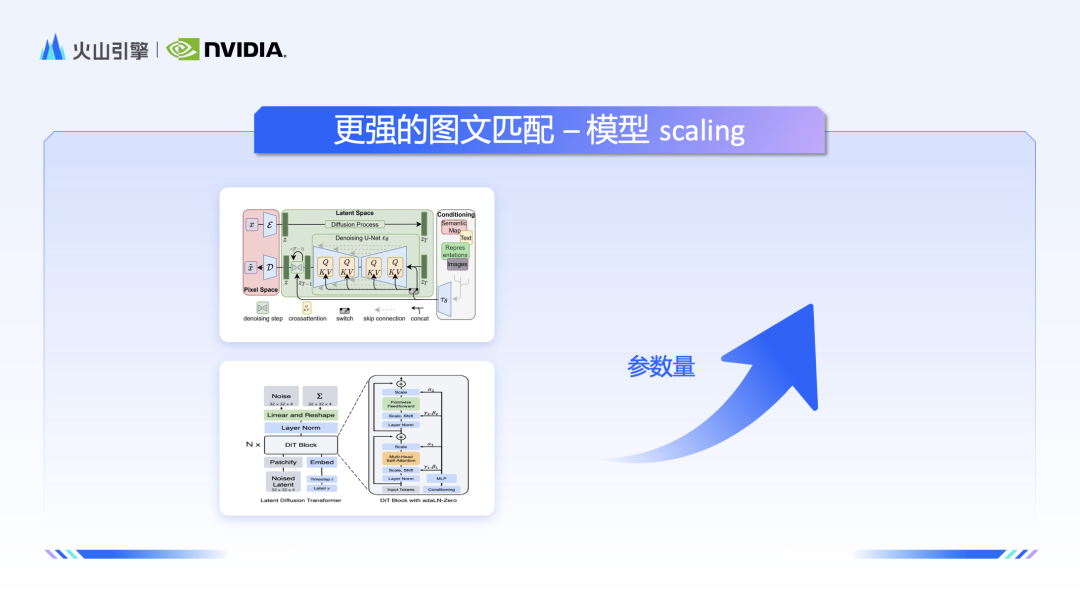
趙一嘉首先分享了 Stable Diffusion 背後模型的原理詳解,細緻地闡述了 Clip、VAE 和 Unet 等關鍵組件的工作原理。隨著 Sora 爆火,也帶火了背後的 DiT(擴散 Transformer)架構。趙一嘉進一步從模型結構、特性和算力消耗三方面,從模型結構、特性和資源消耗三個方面,對 SD 和 DiT 的優勢進行了全面的比較。
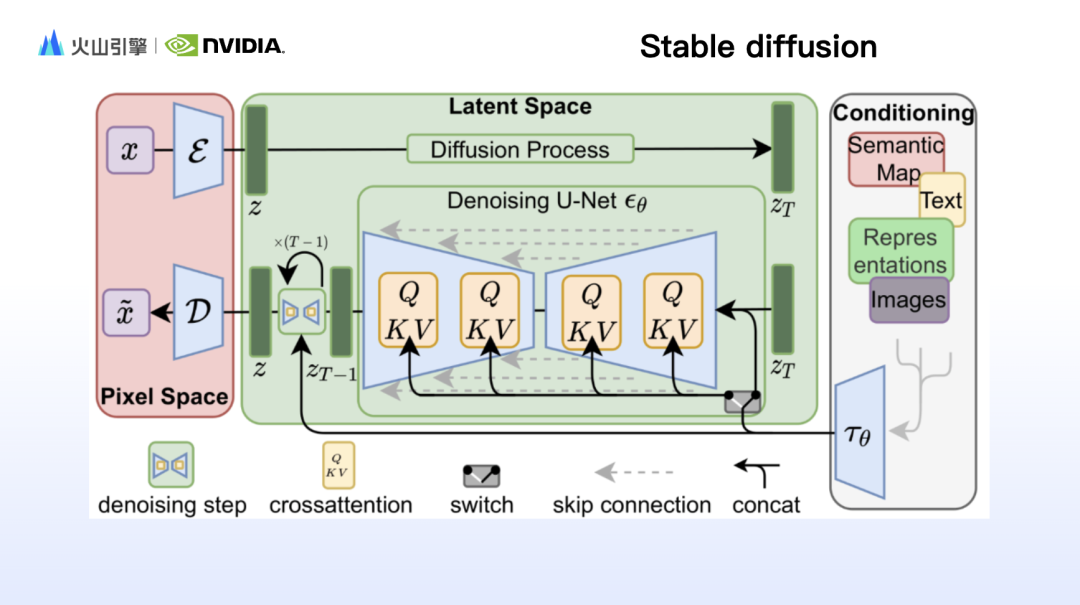
使用Stable diffusion 生成圖像時,往往會感覺提示詞內容在生成結果中都得到了呈現,但圖不是自己想要的,這是因為基於文字出圖的Stable diffusion 並不擅長控制圖像的細節,例如構圖、動作、臉部特徵、空間關係等。因此,基於Stable diffusion 的工作原理,研究人員設計了許多控制模組,彌補 Stable diffusion 的短板。趙一嘉補充了其中代表性的 IP-adapter 和 ControlNet。 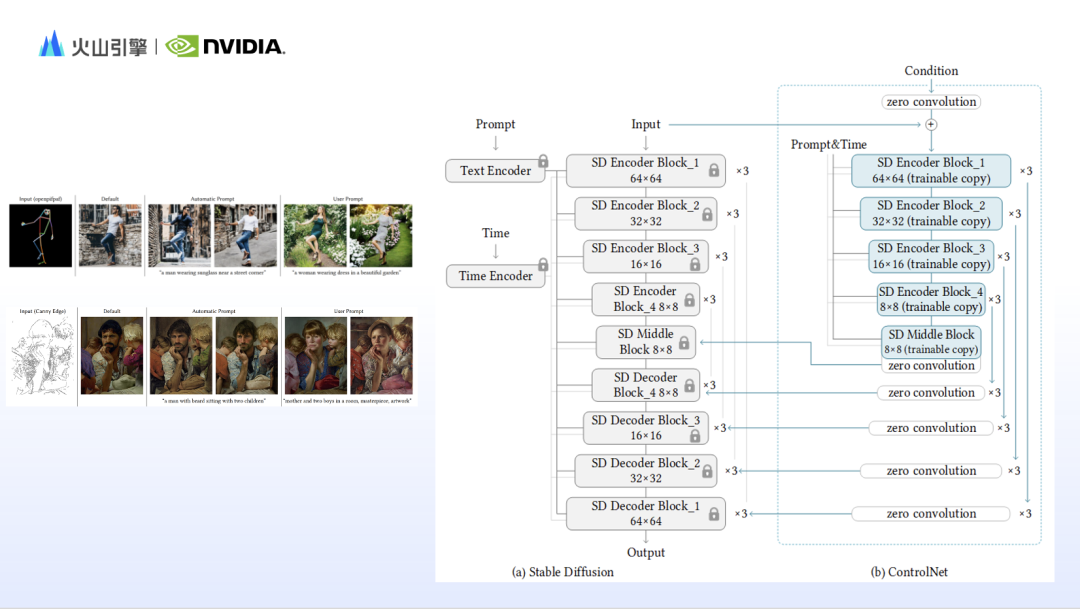
想要加快吃算力的文生圖模型的推理速度,英偉達的技術支援發揮了關鍵作用。趙一嘉介紹了 Nvidia TensorRT 和 TensorRT-LLM 工具,這些工具透過高性能卷積、高效調度和分散式部署等技術,優化了圖文生成模型的推理過程。同時,英偉達的 Ada、Hopper 以及即將推出的 BlackWell 硬體架構,都已支援 FP8 訓練和推理,將為模型訓練帶來更絲滑的體驗。

經歷了六場精彩的直播,由火山引擎、NVIDIA 聯手本站和 CMO CLUB 共同推出的《AIGC體驗派》迎來了圓滿收官。透過這六期節目,相信大家對 AIGC 如何從「有趣」變成「有用」有了更深的理解。我們也期待《AIGC 體驗派》不只停留在節目的討論中,並更能在實際中加速行銷領域智慧化升級的進程。
《AIGC 體驗派》全六期回顧網址:https://vtizr.xetlk.com/s/7CjTy
위 내용은 AI는 사진을 더 빠르고 아름답게 만들고, 당신의 생각을 더 잘 이해합니다. 미모가 뛰어난 빈센트 사진 모델은 어떤 기술적 비밀을 쌓아왔나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



