맘바 아키텍처의 대형 모델이 다시 한 번 트랜스포머에 도전했습니다.
이번에는 드디어 Mamba 아키텍처 모델이 "일어설" 것인가? Mamba는 2023년 12월 처음 출시된 이후 Transformer의 심각한 경쟁자로 등장했습니다. 이후 Mistral에서 출시한 Mamba 아키텍처 기반 최초의 오픈소스 대형 모델인 Codestral 7B 등 Mamba 아키텍처를 사용하는 모델이 계속해서 등장했습니다. 오늘 아부다비 기술 혁신 연구소(TII)는 새로운 오픈 소스 Mamba 모델인 Falcon Mamba 7B를 출시했습니다. 
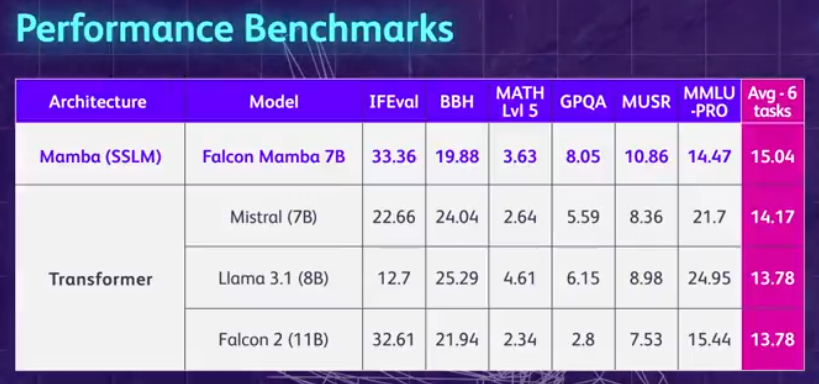
먼저 Falcon Mamba 7B의 주요 특징을 요약해 보겠습니다. 메모리 저장 용량을 늘리지 않고도 모든 길이의 시퀀스를 처리할 수 있으며 단일 24GB A10 GPU에서 실행할 수 있습니다. 현재 Hugging Face에서 Falcon Mamba 7B를 보고 사용할 수 있습니다. 이 인과 디코더 전용 모델은 새로운 Mamba State Space Language Model(SSLM) 아키텍처를 사용하여 다양한 텍스트 생성 작업을 처리합니다. 결과에 따르면 Falcon Mamba 7B는 Meta의 Llama 3 8B, Llama 3.1 8B 및 Mistral 7B를 포함한 여러 벤치마크에서 동급 크기의 주요 모델을 능가합니다.
Falcon Mamba 7B는 기본 버전, 명령 미세 조정 버전, 4비트 버전 및 명령 미세 조정 4비트 버전의 네 가지 변형 모델로 나뉩니다.
Falcon Mamba 7B는 오픈 소스 모델로서 Apache 2.0 기반 라이선스 "Falcon License 2.0"을 채택하여 연구 및 응용 목적을 지원합니다.
Hugging Face 주소: https://huggingface.co/tiiuae/falcon-mamba-7bFalcon Mamba 7B는 Falcon 180B, Falcon 40B 및 Falcon 2 Four에 이어 세 번째 TII 오픈 소스가 되었습니다. 모델이며 최초의 Mamba SSLM 아키텍처 모델입니다.
오랜 기간 동안 Transformer 기반 모델이 생성 AI를 지배해 왔습니다. 그러나 연구자들은 Transformer 아키텍처가 긴 텍스트 정보를 처리하는 데 어려움이 있음을 발견했습니다. 접할 수 있습니다. 기본적으로 Transformer의 어텐션 메커니즘은 각 단어(또는 토큰)를 텍스트의 각 단어와 비교하여 컨텍스트를 이해합니다. 이를 위해서는 증가하는 컨텍스트 창을 처리하기 위해 더 많은 컴퓨팅 성능과 메모리 요구 사항이 필요합니다. 그러나 그에 맞춰 컴퓨팅 리소스를 확장하지 않으면 모델 추론 속도가 느려지고 일정 길이를 초과하는 텍스트는 처리할 수 없습니다. 이러한 장애물을 극복하기 위해 단어를 처리하면서 상태를 지속적으로 업데이트하는 SSLM(State Space Language Model) 아키텍처가 유망한 대안으로 떠오르며 TII를 비롯한 많은 기관에서 배포하고 있습니다. Falcon Mamba 7B는 원래 카네기 멜론 대학교와 프린스턴 대학교의 연구원들이 2023년 12월 논문에서 제안한 Mamba SSM 아키텍처를 사용합니다. 아키텍처는 모델이 입력에 따라 매개변수를 동적으로 조정할 수 있는 선택 메커니즘을 사용합니다. 이러한 방식으로 모델은 Transformer에서 어텐션 메커니즘이 작동하는 방식과 유사하게 특정 입력에 집중하거나 무시할 수 있으며, 추가 메모리나 컴퓨팅 리소스 없이도 긴 텍스트 시퀀스(예: 책 전체)를 처리할 수 있는 기능을 제공합니다. TII는 이러한 접근 방식을 통해 모델이 엔터프라이즈 수준의 기계 번역, 텍스트 요약, 컴퓨터 비전 및 오디오 처리 작업, 추정 및 예측과 같은 작업에 적합하다고 언급했습니다. Falcon Mamba 7B Training 데이터는 최대 5500GT이며 주로 RefinedWeb 데이터 세트로 구성되며 공개 소스의 고품질 기술 데이터, 코드 데이터 및 수학 데이터가 추가됩니다. . 모든 데이터는 Falcon-7B/11B 토크나이저를 사용하여 토큰화됩니다. 다른 Falcon 시리즈 모델과 유사하게 Falcon Mamba 7B는 다단계 훈련 전략을 사용하여 훈련됩니다. 컨텍스트 길이가 2048에서 8192로 늘어납니다. 또한 TII는 코스 학습 개념에서 영감을 받아 데이터의 다양성과 복잡성을 충분히 고려하여 교육 단계 전반에 걸쳐 혼합 데이터를 신중하게 선택합니다. 최종 교육 단계에서 TII는 소규모의 고품질 큐레이트 데이터 세트(예: Fineweb-edu의 샘플)를 사용하여 성능을 더욱 향상시킵니다. Falcon Mamba 7B의 대부분의 훈련은 3D 병렬 처리(TP=1, PP=1, DP=256)를 사용하여 256 H100 80GB GPU에서 완료되었습니다. ZeRO와 결합된 전략. 아래 그림은 정확도, 최적화 도구, 최대 학습 속도, 가중치 감소 및 배치 크기를 포함한 모델 하이퍼파라미터 세부 정보를 보여줍니다.
具体的には、Falcon Mamba 7B は AdamW オプティマイザー、WSD (warm-stabilize-decay) 学習レート プランでトレーニングされ、最初の 50 GT のトレーニング プロセス中にバッチ サイズが b_min=128 から b_max=2048 に増加しました。 安定期では、TIIは最大学習率η_max=6.4×10^−4を使用し、その後、500GTを超える指数計画を使用して最小値まで減衰させます。同時に、TII は加速フェーズで BatchScaling を使用して学習率 η を再調整し、アダム ノイズ温度 が一定に保たれるようにします。 モデル全体のトレーニングには約 2 か月かかりました。 Falcon Mamba 7B がそのサイズクラスの主要な Transformer モデルとどのように比較されるかを理解するために、研究では、単一の 24GB A10 GPU 最大コンテキストを使用してモデルが何を処理できるかを判断するテストを実施しました。長さ。 結果は、Falcon Mamba が現在の Transformer モデルよりも大きなシーケンスに適応できると同時に、理論的には無制限のコンテキスト長にも適応できることを示しています。
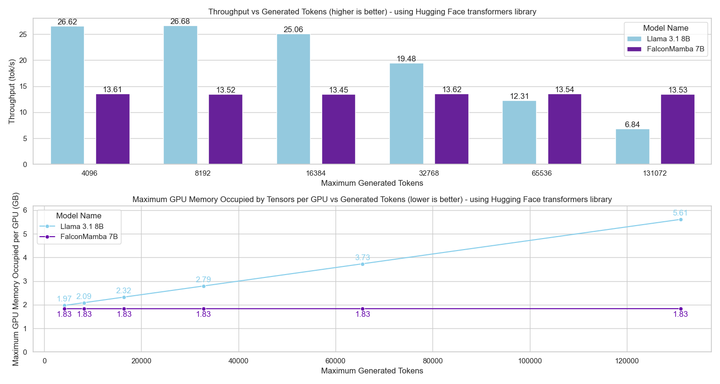
次に、研究者は、バッチ サイズ 1 および H100 GPU のハードウェア設定を使用して、モデル生成のスループットを測定しました。結果は以下の図に示されています。Falcon Mamba は、CUDA ピーク メモリを増加させることなく、一定のスループットですべてのトークンを生成します。 Transformer モデルの場合、生成されるトークンの数が増えると、ピーク メモリが増加し、生成速度が遅くなります。
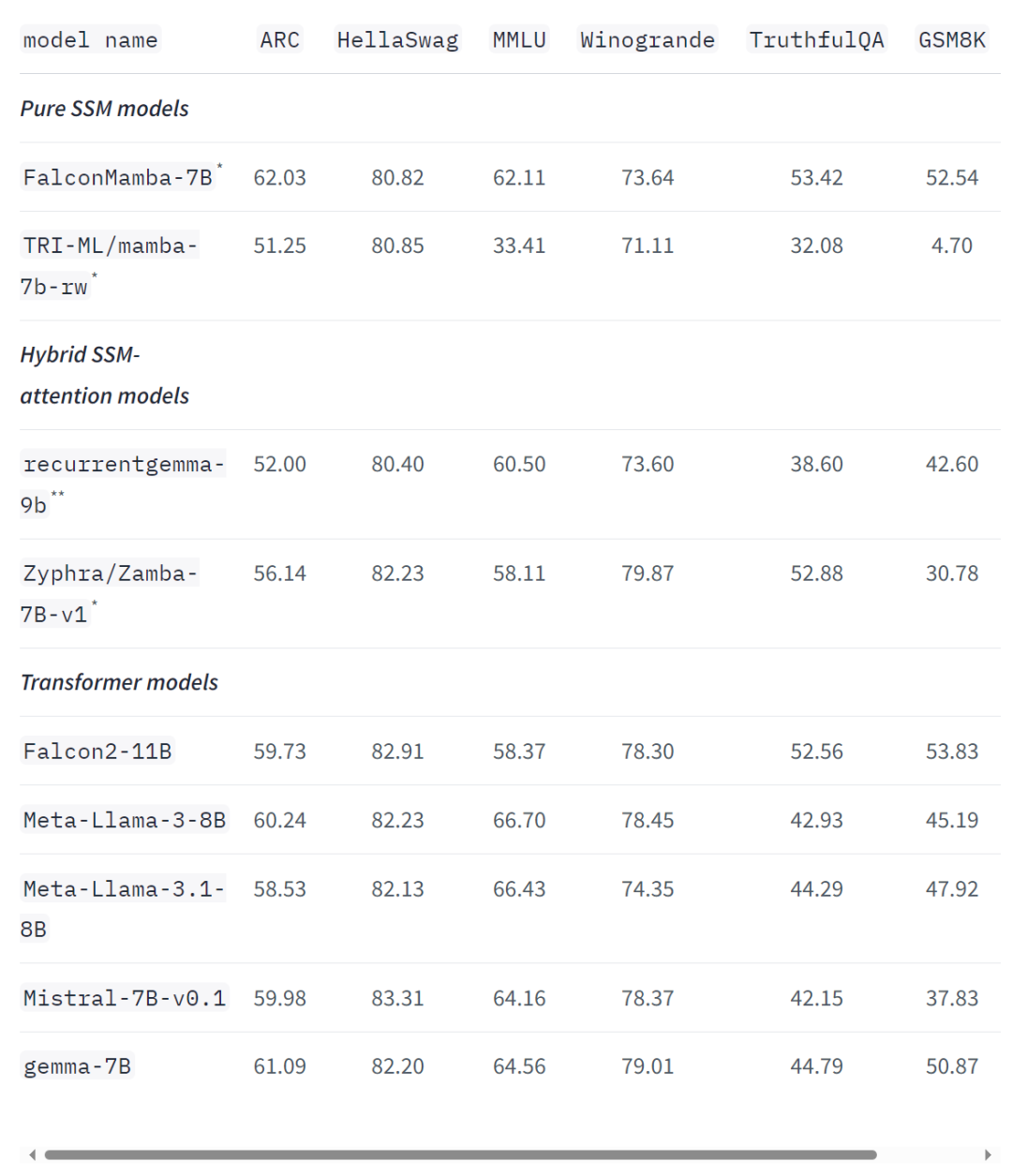
標準的な業界ベンチマークでも、新しいモデルは、一般的な変圧器モデルや純粋な状態空間モデルやハイブリッド状態空間モデルよりも優れているか、それに近いパフォーマンスを示しています。 たとえば、Arc、TruthfulQA、GSM8K ベンチマークでは、Falcon Mamba 7B のスコアはそれぞれ 62.03%、53.42%、52.54% で、Llama 3 8B、Llama 3.1 8B、Gemma 7B、Mistral 7B を上回りました。ただし、Falcon Mamba 7B は、MMLU および Hellaswag ベンチマークではこれらのモデルに大きく遅れをとっています。
TII主任研究員ハキム・ハシッド氏は声明で次のように述べた:ファルコン・マンバ7Bの打ち上げは同局にとって大きな前進であり、新たな視点を刺激し、情報の体系的な探査を推進するものである。 TII では、生成 AI のさらなる革新を促すために、SSLM とトランスフォーマー モデルの限界を押し広げています。 現在、TII の Falcon ファミリ言語モデルは 4,500 万回以上ダウンロードされており、UAE で最も成功した LLM バージョンの 1 つとなっています。 Falcon Mamba 7B の紙は間もなくリリースされます。少しお待ちください。 https://huggingface.co/blog/falconmambahttps://venturebeat.com/ai/falcon-mamba-7bs-powerful -new-ai-architecture-offers-alternative-to-transformer-models/위 내용은 Non-Transformer 아키텍처가 돋보입니다! 오픈소스 거대 기업 Llama 3.1을 능가하는 최초의 순수 주목없는 대형 모델의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!





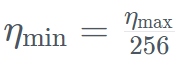 を超える指数計画を使用して最小値まで減衰させます。同時に、TII は加速フェーズで BatchScaling を使用して学習率 η を再調整し、アダム ノイズ温度
を超える指数計画を使用して最小値まで減衰させます。同時に、TII は加速フェーズで BatchScaling を使用して学習率 η を再調整し、アダム ノイズ温度 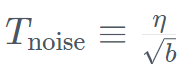 が一定に保たれるようにします。
が一定に保たれるようにします。 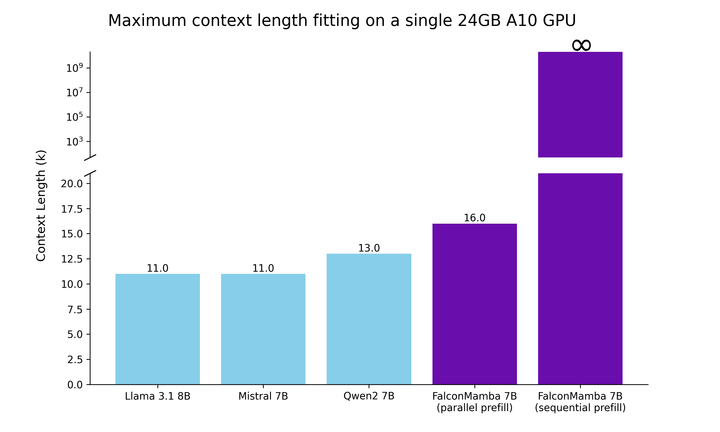


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



