

1 우수, 5 구강! 올해 ByteDance의 ACL이 그렇게 치열했나요? 생방송실에 오셔서 채팅해보세요!

이번 주 학계의 초점은 단연 태국 방콕에서 열리는 ACL 2024 Summit입니다. 이번 행사에는 전 세계의 많은 뛰어난 연구자들이 모여 최신 학술 성과를 토론하고 공유했습니다.
공식 데이터에 따르면 올해 ACL에는 약 5,000편의 논문이 접수되었으며 그 중 940개가 본회의에서 승인되었으며 168개의 작품이 회의의 구두 보고서(구두)에 선정되었습니다. 승인률은 3.4% 미만입니다. 그 중 ByteDance에는 총 5개의 결과가 있으며 Oral이 선택되었습니다.
8월 14일 오후 논문상 세션에서 ByteDance의 성과 "G-DIG: Towards Gradient-based DIverse and high-quality Instruction Data Selection for Machine Translation"이 주최측에서 우수논문(Outstanding Paper)으로 공식 발표되었습니다. 1/35).现 ACL 2024 현장 사진
 ACL 2021로 돌아와서 바이트비팅이 유일하게 월계관으로 최우수 논문을 차지했습니다. ACL 창설 이후 두 번째로 중국 과학자팀이 선정된 것입니다. 최우수상!
ACL 2021로 돌아와서 바이트비팅이 유일하게 월계관으로 최우수 논문을 차지했습니다. ACL 창설 이후 두 번째로 중국 과학자팀이 선정된 것입니다. 최우수상!
올해 최첨단 연구 결과에 대한 심도 있는 논의를 위해 특별히 ByteDance 논문의 핵심 작업자를 초대하여 해석하고 공유했습니다. 다음주 8월 20일 화요일 19:00~21:00에 "ByteDance ACL 2024 최첨단 종이 공유 세션"이 온라인으로 방송됩니다!
Doubao 언어 모델 연구 팀의 리더인 Wang Mingxuan은 많은 ByteDance 연구자
Huang Zhichao, Zheng Zaixiang, Li Chaowei, Zhang Xinbo 및 Outstanding Paper의 신비한 손님과 손을 잡고 흥미로운 결과를 공유할 예정입니다. 및 ACL의 연구 방향 자연어 처리, 음성 처리, 다중 모드 학습, 대형 모델 추론 및 기타 분야가 포함됩니다. 예약을 환영합니다!
이벤트 안건
선정 논문의 해석



최근 대규모 언어 모델(LLM)의 급속한 발전으로 인해 이산 음성 토큰화는 음성을 LLM에 주입하는 데 중요한 역할을 합니다. 그러나 이러한 분할은 정보의 손실로 이어져 전반적인 성능에 해를 끼칩니다. 이러한 이산 음성 토큰의 성능을 향상시키기 위해 의미론적 음성 이산화를 위한 새로운 음성 표현 코덱인 RepCodec을 제안합니다. RepCodec의 프레임워크
원본 오디오를 재구성하는 오디오 코덱과 달리 RepCodec은 음성 인코더에서 음성 표현을 재구성하여 VQ 코드북을 학습합니다. HuBERT나 data2vec 같은 거죠. 음성 인코더, 코덱 인코더 및 VQ 코드북은 함께 음성 파형을 의미 토큰으로 변환하는 프로세스를 구성합니다. 광범위한 실험에 따르면 RepCodec은 향상된 정보 보존 기능으로 인해 음성 이해 및 생성에서 널리 사용되는 k-평균 클러스터링 방법보다 성능이 훨씬 뛰어난 것으로 나타났습니다. 또한 이러한 장점은 다양한 음성 코더 및 언어 전반에 걸쳐 지속되어 RepCodec의 견고성을 확인합니다. 이 접근 방식은 음성 처리에서 대규모 언어 모델 연구를 촉진할 수 있습니다. DINOISER: 노이즈 조작으로 강화된 확산 조건부 시퀀스 생성 모델 논문 주소: https://arxiv.org/pdf/2302.10025 확산 모델 생성 중 이미지, 오디오 등 연속적인 신호로 큰 성공을 거두었지만, 자연어와 같은 개별 시퀀스 데이터를 학습하는 데는 어려움이 남아 있습니다. 최근 일련의 텍스트 확산 모델은 이산 상태를 연속 상태 잠재 공간에 삽입하여 이산 문제를 회피하지만 생성 품질은 여전히 만족스럽지 않습니다.
이를 이해하기 위해 먼저 확산 모델을 기반으로 한 시퀀스 생성 모델의 학습 과정을 심층적으로 분석하고 이에 대한 세 가지 심각한 문제를 식별합니다. (1) 학습 실패(2) 확장성 부족; 우리는 이러한 문제가 노이즈의 규모가 결정적인 역할을 하는 임베딩 공간의 불연속성의 불완전성에 기인할 수 있다고 믿습니다.
이번 연구에서는 노이즈를 조작하여 시퀀스 생성을 위한 확산 모델을 향상시키는 DINOISER를 제안합니다. 우리는 최적의 전송에서 영감을 얻은 방식으로 훈련 단계 동안 샘플링된 노이즈 스케일의 범위를 적응적으로 결정하고, 추론 단계 동안 모델이 노이즈 스케일을 증폭하여 조건부 신호를 더 잘 활용하도록 장려합니다. 실험에 따르면 제안된 효과적인 훈련 및 추론 전략을 기반으로 DINOISER는 여러 조건부 시퀀스 모델링 벤치마크에서 이전 확산 시퀀스 생성 모델의 기준을 능가하는 것으로 나타났습니다. 추가 분석에서는 DINOISER가 생성 프로세스를 제어하기 위해 조건부 신호를 더 잘 활용할 수 있음도 확인했습니다.
중복성을 줄여 시각적 조건부 언어 생성 훈련을 가속화합니다. 문서 주소: https://arxiv.org/pdf/2310.03291 A 단순화를 위한 도구인 EVLGen을 소개합니다. 고정된 사전 훈련된 LLM(대형 언어 모델)을 활용하여 계산 요구 사항이 높은 시각적 조건부 언어 생성 모델의 사전 훈련을 위해 설계된 프레임워크입니다. EVLGen 개요 시각적 언어 사전 훈련(VLP)의 기존 접근 방식은 일반적으로 2단계 최적화 프로세스를 포함합니다. 즉, 일반 시각적 언어 전용의 초기 리소스 집약적 단계입니다. 표현 학습에 중점을 둡니다. 관련 시각적 특징을 추출하고 통합하는 방법. 그 다음에는 시각적 양식과 언어 양식 간의 엔드투엔드 정렬을 강조하는 후속 단계가 이어집니다. 우리의 새로운 단일 단계 단일 손실 프레임워크는 훈련 중에 유사한 시각적 랜드마크를 점진적으로 병합함으로써 계산량이 많은 첫 번째 훈련 단계를 우회하는 동시에 BLIP-2 유형 모델의 단일 단계 훈련으로 인한 모델 불편을 피합니다. 점진적인 병합 프로세스는 의미적 풍부함을 유지하면서 시각적 정보를 효과적으로 압축하여 성능에 영향을 주지 않고 빠른 수렴을 달성합니다. 실험 결과에 따르면 우리의 방법은 전체 성능에 큰 영향을 주지 않고 시각적 언어 모델의 학습 속도를 5배 향상시키는 것으로 나타났습니다. 또한 우리 모델은 데이터의 1/10만 사용하여 현재 시각적 언어 모델과의 성능 격차를 크게 줄였습니다. 마지막으로, 새로운 소프트 주의 시간적 레이블이 지정된 컨텍스트 모듈을 통해 이미지-텍스트 모델이 비디오 조건 언어 생성 작업에 원활하게 적응할 수 있는 방법을 보여줍니다.
StreamVoice: 실시간 제로샷 음성 변환을 위한 스트리밍 가능한 상황 인식 언어 모델링
문서 주소: https://arxiv.org/pdf/2401.11053
스트리밍 스트리밍 제로샷 음성 변환은 입력 음성을 실시간으로 모든 화자의 음성으로 변환하는 기능을 말하며 화자의 음성 중 한 문장만 참조로 필요하며 추가적인 모델 업데이트가 필요하지 않습니다. 기존의 제로 샘플 음성 변환 방법은 일반적으로 오프라인 시스템용으로 설계되었으며 실시간 음성 변환 애플리케이션의 스트리밍 기능 요구 사항을 충족하기 어렵습니다. 최근 LM(언어 모델) 기반 방법은 제로샷 음성 생성(변환 포함)에서 뛰어난 성능을 보여 주었지만 전체 문장 처리가 필요하고 오프라인 시나리오로 제한됩니다. > StreamVoice G-DIG:致力于基于梯度的机器翻译多样化和高质量指令数据选择 论文地址:https://arxiv.org/pdf/2405.12915 大型语言模型(LLMs)在一般场景中展现出了非凡的能力。指令微调使它们能够在各种任务中与人类保持一致。然而,指令数据的多样性和质量仍然是指令微调的两个主要挑战。对此,我们提出了一种新颖的基于梯度的方法,为机器翻译自动选择高质量和多样化的指令微调数据。我们的关键创新在于分析单个训练示例在训练过程中如何影响模型。
Overview of G-DIG
具体来说,我们借助影响函数和一个小型高质量种子数据集,选择对模型产生有益影响的训练示例作为高质量示例。此外,为了增强训练数据的多样性,我们通过对它们的梯度进行聚类和重新采样,最大程度地增加它们对模型影响的多样性。在 WMT22 和 FLORES 翻译任务上的大量实验证明了我们方法的优越性,深入的分析进一步验证了其有效性和通用性。
GroundingGPT:语言增强的多模态 Grounding 模型 论文地址:https://arxiv.org/pdf/2401.06071 多模态大语言模型在不同模态的各种任务中都展示出了出色的性能。然而此前的模型主要强调捕获多模态输入的全局信息,因此这些模型缺乏有效理解输入数据中细节的能力,在需要对输入细致理解的任务中表现不佳,同时这些模型大多存在严重的幻觉问题,限制了其广泛使用。
为了解决这一问题,增强多模态大模型在更广泛任务中的通用性,我们提出了 GroundingGPT,一种能够实现对图片、视频、音频不同粒度理解的多模态模型。我们提出的模型除了捕获全局信息外,还擅长处理需要更精细理解的任务,例如模型能够精确定位图像中的特定区域或视频中的特定时刻。为了实现这一目标,我们设计了多样化的数据集构建流程,从而构造了一个多模态、多粒度的训练数据集。在多个公开 benchmark 上的实验证明了我们模型的通用性和有效性。
ReFT:基于强化微调的推理 论文地址:https://arxiv.org/pdf/2401.08967 一种常见的增强大型语言模型(LLMs)推理能力的方法是使用思维链(CoT)标注数据进行有监督微调(SFT)。然而,这种方法并没有表现出足够强的泛化能力,因为训练仅依赖于给定的 CoT 数据。具体地,在数学问题的相关数据集中,训练数据中每个问题通常只有一条标注的推理路径。对于算法来说,如果能针对一个问题学习到多种标注的推理路径,会有更强的泛化能力。
이 과제를 해결하기 위해 수학적 문제를 예로 들어 추론 중 LLM의 일반화 능력을 향상시키는 ReFT(Reinforced Fine-Tuning)라는 간단하고 효과적인 방법을 제안합니다. ReFT는 먼저 SFT를 사용하여 모델을 워밍업한 다음 최적화를 위해 온라인 강화 학습(특히 이 작업의 PPO 알고리즘)을 사용합니다. 이는 주어진 문제에 대한 많은 추론 경로를 자동으로 샘플링하고 실제 답변을 기반으로 보상을 얻습니다. 추가 미세 조정 모델. GSM8K, MathQA 및 SVAMP 데이터 세트에 대한 광범위한 실험을 통해 ReFT가 SFT보다 성능이 크게 뛰어나며 다수 투표 및 재정렬과 같은 전략을 결합하면 모델 성능이 더욱 향상될 수 있음을 보여줍니다. 여기서 ReFT는 SFT와 동일한 훈련 문제에만 의존하고 추가 또는 향상된 훈련 문제에는 의존하지 않는다는 점은 주목할 가치가 있습니다. 이는 ReFT가 일반화 능력이 우수하다는 것을 보여줍니다. 여러분의 인터랙티브 질문을 기다립니다
생방송 시간 : 2024년 8월 20일(화) 19:00-21:00 생방송 플랫폼 : WeChat 영상 계정 [두바오 빅모델팀], Xiao Red Book Number [Doubao 연구원] ACL 2024 논문에 대해 관심 있는 질문을 설문지에 작성하고, 온라인에서 여러 연구원과 채팅하실 수 있습니다! 빈바오 모델팀은 계속해서 뜨거운 모집을 받고 있습니다. 팀 모집 관련 정보는 이 링크를 눌러주세요.
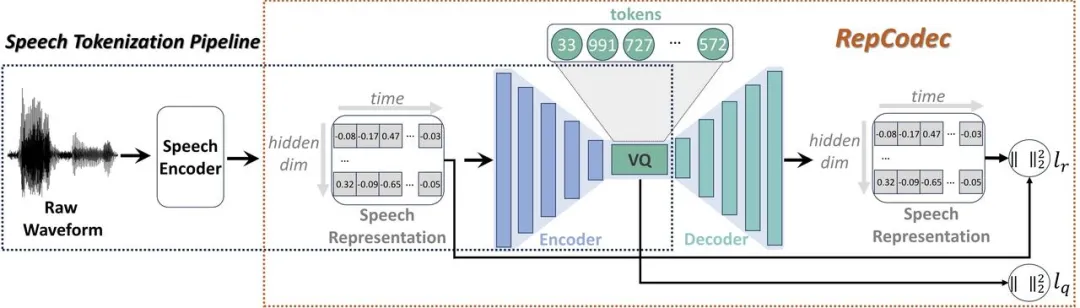 RepCodec의 프레임워크
RepCodec의 프레임워크 


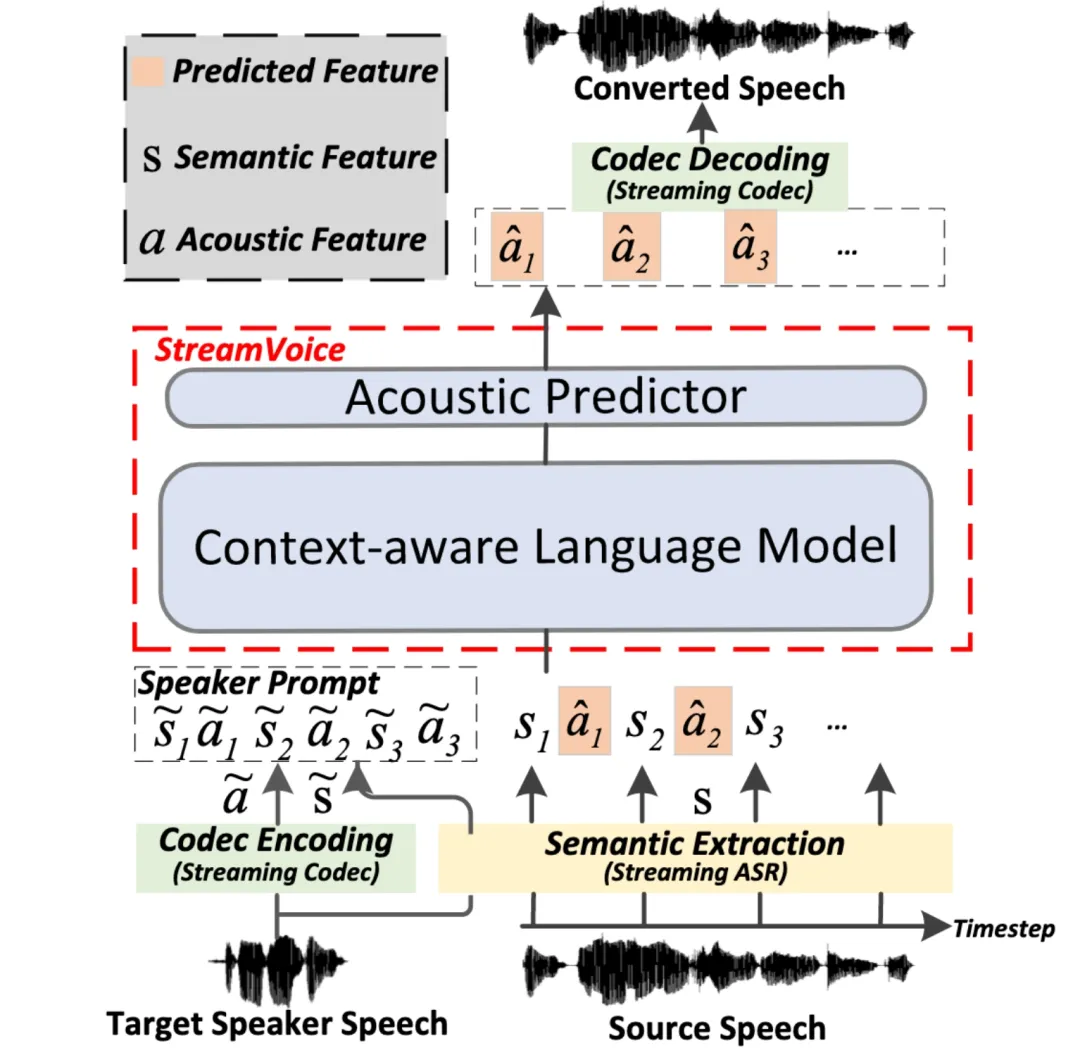 본 연구에서는 임의의 화자와 입력 음성에 대한 실시간 변환을 달성하기 위해 스트리밍 LM 기반의 새로운 제로샷 음성 변환 모델인 StreamVoice를 제안합니다. 특히 스트리밍 기능을 달성하기 위해 StreamVoice는 상황 인식 완전 인과 LM과 타이밍 독립적 음향 예측기를 사용하는 동시에 자동 회귀 프로세스에서 의미론적 특징과 음향 특징을 교대로 처리하여 전체 소스 음성에 대한 의존성을 제거합니다. 스트리밍 시나리오에서 불완전한 맥락으로 인한 성능 저하를 해결하기 위해 LM의 미래와 역사에 대한 맥락 인식을 향상시키기 위해 두 가지 전략이 사용됩니다. 1) 교사 주도 맥락 예측을 통해 모델은 누락된 맥락을 예측할 때 모델을 안내하는 현재 및 미래의 정확한 의미론 2) 의미론적 마스킹 전략은 모델이 이전에 손상된 의미론적 입력으로부터 음향 예측을 달성하고 역사적 맥락의 학습 능력을 향상하도록 장려합니다. 실험에 따르면 StreamVoice에는 스트리밍 변환 기능이 있으면서도 비스트리밍 VC 시스템에 가까운 제로샷 성능을 달성하는 것으로 나타났습니다.
본 연구에서는 임의의 화자와 입력 음성에 대한 실시간 변환을 달성하기 위해 스트리밍 LM 기반의 새로운 제로샷 음성 변환 모델인 StreamVoice를 제안합니다. 특히 스트리밍 기능을 달성하기 위해 StreamVoice는 상황 인식 완전 인과 LM과 타이밍 독립적 음향 예측기를 사용하는 동시에 자동 회귀 프로세스에서 의미론적 특징과 음향 특징을 교대로 처리하여 전체 소스 음성에 대한 의존성을 제거합니다. 스트리밍 시나리오에서 불완전한 맥락으로 인한 성능 저하를 해결하기 위해 LM의 미래와 역사에 대한 맥락 인식을 향상시키기 위해 두 가지 전략이 사용됩니다. 1) 교사 주도 맥락 예측을 통해 모델은 누락된 맥락을 예측할 때 모델을 안내하는 현재 및 미래의 정확한 의미론 2) 의미론적 마스킹 전략은 모델이 이전에 손상된 의미론적 입력으로부터 음향 예측을 달성하고 역사적 맥락의 학습 능력을 향상하도록 장려합니다. 실험에 따르면 StreamVoice에는 스트리밍 변환 기능이 있으면서도 비스트리밍 VC 시스템에 가까운 제로샷 성능을 달성하는 것으로 나타났습니다. 



 Comparison between SFT and ReFT on the presence of CoT alternatives
Comparison between SFT and ReFT on the presence of CoT alternatives
위 내용은 1 우수, 5 구강! 올해 ByteDance의 ACL이 그렇게 치열했나요? 생방송실에 오셔서 채팅해보세요!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 딥마인드 로봇이 탁구를 치는데 포핸드와 백핸드가 공중으로 미끄러져 인간 초보자를 완전히 제압했다.
Aug 09, 2024 pm 04:01 PM
딥마인드 로봇이 탁구를 치는데 포핸드와 백핸드가 공중으로 미끄러져 인간 초보자를 완전히 제압했다.
Aug 09, 2024 pm 04:01 PM
하지만 공원에 있는 노인을 이길 수는 없을까요? 파리올림픽이 본격화되면서 탁구가 많은 주목을 받고 있다. 동시에 로봇은 탁구 경기에서도 새로운 돌파구를 마련했습니다. 방금 DeepMind는 탁구 경기에서 인간 아마추어 선수 수준에 도달할 수 있는 최초의 학습 로봇 에이전트를 제안했습니다. 논문 주소: https://arxiv.org/pdf/2408.03906 DeepMind 로봇은 탁구를 얼마나 잘 치나요? 아마도 인간 아마추어 선수들과 동등할 것입니다: 포핸드와 백핸드 모두: 상대는 다양한 플레이 스타일을 사용하고 로봇도 견딜 수 있습니다: 다양한 스핀으로 서브를 받습니다. 그러나 게임의 강도는 그만큼 강렬하지 않은 것 같습니다. 공원에 있는 노인. 로봇용, 탁구용
 최초의 기계식 발톱! Yuanluobao는 2024년 세계 로봇 회의에 등장하여 집에 들어갈 수 있는 최초의 체스 로봇을 출시했습니다.
Aug 21, 2024 pm 07:33 PM
최초의 기계식 발톱! Yuanluobao는 2024년 세계 로봇 회의에 등장하여 집에 들어갈 수 있는 최초의 체스 로봇을 출시했습니다.
Aug 21, 2024 pm 07:33 PM
8월 21일, 2024년 세계로봇대회가 베이징에서 성대하게 개최되었습니다. SenseTime의 홈 로봇 브랜드 "Yuanluobot SenseRobot"은 전체 제품군을 공개했으며, 최근에는 Yuanluobot AI 체스 두는 로봇인 체스 프로페셔널 에디션(이하 "Yuanluobot SenseRobot")을 출시하여 세계 최초의 A 체스 로봇이 되었습니다. 집. Yuanluobo의 세 번째 체스 게임 로봇 제품인 새로운 Guoxiang 로봇은 AI 및 엔지니어링 기계 분야에서 수많은 특별한 기술 업그레이드와 혁신을 거쳤으며 처음으로 3차원 체스 말을 집는 능력을 실현했습니다. 가정용 로봇의 기계 발톱을 통해 체스 게임, 모두 체스 게임, 기보 복습 등과 같은 인간-기계 기능을 수행합니다.
 클로드도 게으르게 됐어요! 네티즌 : 휴가를 보내는 법을 배우십시오
Sep 02, 2024 pm 01:56 PM
클로드도 게으르게 됐어요! 네티즌 : 휴가를 보내는 법을 배우십시오
Sep 02, 2024 pm 01:56 PM
개학이 코앞으로 다가왔습니다. 새 학기를 앞둔 학생들뿐만 아니라 대형 AI 모델도 스스로 관리해야 합니다. 얼마 전 레딧에는 클로드가 게으르다고 불평하는 네티즌들이 붐볐습니다. "레벨이 많이 떨어졌고, 자주 멈췄고, 심지어 출력도 매우 짧아졌습니다. 출시 첫 주에는 4페이지 전체 문서를 한 번에 번역할 수 있었지만 지금은 반 페이지도 출력하지 못합니다. !" https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ "클로드에게 완전히 실망했습니다"라는 제목의 게시물에
 세계로봇컨퍼런스에서 '미래 노인돌봄의 희망'을 담은 국산 로봇이 포위됐다.
Aug 22, 2024 pm 10:35 PM
세계로봇컨퍼런스에서 '미래 노인돌봄의 희망'을 담은 국산 로봇이 포위됐다.
Aug 22, 2024 pm 10:35 PM
베이징에서 열린 세계로봇컨퍼런스에서는 휴머노이드 로봇의 전시가 현장의 절대 화두가 됐다. 스타더스트 인텔리전트 부스에서는 AI 로봇 어시스턴트 S1이 덜시머, 무술, 서예 3대 퍼포먼스를 선보였다. 문학과 무술을 모두 갖춘 하나의 전시 공간은 수많은 전문 관객과 미디어를 끌어 모았습니다. 탄력 있는 현의 우아한 연주를 통해 S1은 정밀한 작동과 속도, 힘, 정밀성을 갖춘 절대적인 제어력을 보여줍니다. CCTV 뉴스는 '서예'의 모방 학습 및 지능형 제어에 대한 특별 보도를 진행했습니다. 회사 설립자 Lai Jie는 부드러운 움직임 뒤에 하드웨어 측면이 최고의 힘 제어와 가장 인간과 유사한 신체 지표(속도, 하중)를 추구한다고 설명했습니다. 등)이지만 AI측에서는 사람의 실제 움직임 데이터를 수집해 로봇이 강한 상황에 직면했을 때 더욱 강해지고 빠르게 진화하는 방법을 학습할 수 있다. 그리고 민첩하다
 ACL 2024 시상식 발표: HuaTech의 Oracle 해독에 관한 최고의 논문 중 하나, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 시상식 발표: HuaTech의 Oracle 해독에 관한 최고의 논문 중 하나, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
참가자들은 이번 ACL 컨퍼런스에서 많은 것을 얻었습니다. ACL2024는 6일간 태국 방콕에서 개최됩니다. ACL은 전산언어학 및 자연어 처리 분야 최고의 국제학술대회로 국제전산언어학회(International Association for Computational Linguistics)가 주최하고 매년 개최된다. ACL은 NLP 분야에서 학술 영향력 1위를 항상 차지하고 있으며, CCF-A 추천 컨퍼런스이기도 합니다. 올해로 62회째를 맞이하는 ACL 컨퍼런스에는 NLP 분야의 최신 저서가 400편 이상 접수됐다. 어제 오후 컨퍼런스에서는 최우수 논문과 기타 상을 발표했습니다. 이번에 최우수논문상 7개(미출판 2개), 우수주제상 1개, 우수논문상 35개가 있다. 이 컨퍼런스에서는 또한 3개의 리소스 논문상(ResourceAward)과 사회적 영향상(Social Impact Award)을 수상했습니다.
 Li Feifei 팀은 로봇에 공간 지능을 제공하고 GPT-4o를 통합하기 위해 ReKep을 제안했습니다.
Sep 03, 2024 pm 05:18 PM
Li Feifei 팀은 로봇에 공간 지능을 제공하고 GPT-4o를 통합하기 위해 ReKep을 제안했습니다.
Sep 03, 2024 pm 05:18 PM
비전과 로봇 학습의 긴밀한 통합. 최근 화제를 모으고 있는 1X 휴머노이드 로봇 네오(NEO)와 두 개의 로봇 손이 원활하게 협력해 옷 개기, 차 따르기, 신발 싸기 등을 하는 모습을 보면 마치 로봇 시대로 접어들고 있다는 느낌을 받을 수 있다. 실제로 이러한 부드러운 움직임은 첨단 로봇 기술 + 정교한 프레임 디자인 + 다중 모드 대형 모델의 산물입니다. 우리는 유용한 로봇이 종종 환경과 복잡하고 절묘한 상호작용을 요구한다는 것을 알고 있으며, 환경은 공간적, 시간적 영역에서 제약으로 표현될 수 있습니다. 예를 들어, 로봇이 차를 따르도록 하려면 먼저 로봇이 찻주전자 손잡이를 잡고 차를 흘리지 않고 똑바로 세운 다음, 주전자 입구와 컵 입구가 일치할 때까지 부드럽게 움직여야 합니다. 을 누른 다음 주전자를 특정 각도로 기울입니다. 이것
 분산 인공지능 컨퍼런스 DAI 2024 Call for Papers: Agent Day, 강화학습의 아버지 Richard Sutton이 참석합니다! Yan Shuicheng, Sergey Levine 및 DeepMind 과학자들이 기조 연설을 할 예정입니다.
Aug 22, 2024 pm 08:02 PM
분산 인공지능 컨퍼런스 DAI 2024 Call for Papers: Agent Day, 강화학습의 아버지 Richard Sutton이 참석합니다! Yan Shuicheng, Sergey Levine 및 DeepMind 과학자들이 기조 연설을 할 예정입니다.
Aug 22, 2024 pm 08:02 PM
컨퍼런스 소개 과학기술의 급속한 발전과 함께 인공지능은 사회 발전을 촉진하는 중요한 힘이 되었습니다. 이 시대에 우리는 분산인공지능(DAI)의 혁신과 적용을 목격하고 참여할 수 있어 행운입니다. 분산 인공지능(Distributed Artificial Intelligence)은 인공지능 분야의 중요한 한 분야로, 최근 몇 년간 점점 더 많은 주목을 받고 있습니다. 대규모 언어 모델(LLM) 기반 에이전트가 갑자기 등장했습니다. 대규모 모델의 강력한 언어 이해와 생성 기능을 결합하여 자연어 상호 작용, 지식 추론, 작업 계획 등에 큰 잠재력을 보여주었습니다. AIAgent는 빅 언어 모델을 이어받아 현재 AI계에서 화제가 되고 있습니다. 오
 홍멍 스마트 트래블 S9과 풀시나리오 신제품 출시 컨퍼런스, 다수의 블록버스터 신제품이 함께 출시됐다
Aug 08, 2024 am 07:02 AM
홍멍 스마트 트래블 S9과 풀시나리오 신제품 출시 컨퍼런스, 다수의 블록버스터 신제품이 함께 출시됐다
Aug 08, 2024 am 07:02 AM
오늘 오후 Hongmeng Zhixing은 공식적으로 새로운 브랜드와 신차를 환영했습니다. 8월 6일, Huawei는 Hongmeng Smart Xingxing S9 및 Huawei 전체 시나리오 신제품 출시 컨퍼런스를 개최하여 파노라마식 스마트 플래그십 세단 Xiangjie S9, 새로운 M7Pro 및 Huawei novaFlip, MatePad Pro 12.2인치, 새로운 MatePad Air, Huawei Bisheng을 선보였습니다. 레이저 프린터 X1 시리즈, FreeBuds6i, WATCHFIT3 및 스마트 스크린 S5Pro를 포함한 다양한 새로운 올-시나리오 스마트 제품, 스마트 여행, 스마트 오피스, 스마트 웨어에 이르기까지 화웨이는 풀 시나리오 스마트 생태계를 지속적으로 구축하여 소비자에게 스마트한 경험을 제공합니다. 만물인터넷. Hongmeng Zhixing: 스마트 자동차 산업의 업그레이드를 촉진하기 위한 심층적인 권한 부여 화웨이는 중국 자동차 산업 파트너와 손을 잡고
