

소프트웨어 개발의 재귀 작업


이 고전적인 재귀 계승을 살펴보겠습니다.
으아악재귀 계승 -factorial.c
자신을 호출하는 함수라는 개념은 처음에는 이해하기 어렵습니다. 이 프로세스를 더욱 생생하고 구체적으로 만들기 위해 다음 그림은 계승(5)이 호출되고 코드 n == 1 줄에 도달할 때 스택의 끝점을 보여줍니다.

팩토리얼이 호출될 때마다 새로운 스택 프레임이 생성됩니다. 이러한 스택 프레임의 생성 및 파괴로 인해 재귀 버전이 해당 반복 버전보다 팩터리얼하게 느려집니다. 이러한 스택 프레임이 누적되면 호출이 반환되기 전에 스택 공간이 소진되어 프로그램이 중단될 수 있습니다.
그리고 이러한 걱정은 이론상으로 존재하는 경우가 많습니다. 예를 들어 스택 프레임은 각 계승에 대해 16바이트를 사용합니다(이는 스택 배열 및 기타 요인에 따라 달라질 수 있음). 컴퓨터에서 최신 x86 Linux 커널을 실행하는 경우 일반적으로 스택 공간이 8GB이므로 계승 프로그램의 n은 최대 약 512,000까지 될 수 있습니다. 이는 엄청난 결과이며 이를 표현하는 데 8,971,833비트가 필요하므로 스택 공간은 전혀 문제가 되지 않습니다. 작은 정수(심지어 64비트 정수라도)가 이전에 스택 공간에 수천 번 오버플로되었습니다. 그것은 다 떨어졌다.
CPU의 사용에 대해서는 잠시 살펴보겠습니다. 지금은 비트와 바이트에서 한발 물러나 재귀를 일반적인 기술로 다루겠습니다. 우리의 계승 알고리즘은 정수 N, N-1, … 1을 스택에 푸시하고 역순으로 곱하는 것으로 요약됩니다. 이를 달성하기 위해 실제로 프로그램 호출 스택을 사용합니다. 자세한 내용은 다음과 같습니다. 힙에 스택을 할당하고 사용합니다. 호출 스택에는 특별한 특성이 있지만 원하는 대로 사용할 수 있는 또 다른 데이터 구조일 뿐입니다. 이 다이어그램이 이를 이해하는 데 도움이 되기를 바랍니다.
콜 스택을 데이터 구조로 생각하면 더 명확해집니다. 이러한 정수를 쌓은 다음 곱하는 것은 좋은 생각이 아닙니다. 이는 구현에 결함이 있습니다. 마치 드라이버를 사용하여 못을 박는 것과 같습니다. 계승을 계산하기 위해 반복 프로세스를 사용하는 것이 더 합리적입니다.
그런데 나사가 너무 많아서 하나만 고를 수 있어요. 미로 속에 쥐가 있고 쥐가 치즈 조각을 찾도록 도와야 하는 고전적인 인터뷰 질문이 있습니다. 쥐가 미로에서 왼쪽이나 오른쪽으로 회전할 수 있다고 가정해 보세요. 이 문제를 해결하기 위해 어떻게 모델링합니까?
실생활의 많은 문제와 마찬가지로 치즈를 찾는 쥐의 문제를 그래프로 단순화할 수 있습니다. 이진 트리의 각 노드는 미로에서의 위치를 나타냅니다. 그런 다음 가능하면 마우스를 왼쪽으로 돌리고, 막다른 골목에 도달하면 뒤로 돌아가서 다시 오른쪽으로 돌게 할 수 있습니다. 다음은 미로를 통과하는 마우스의 예입니다.
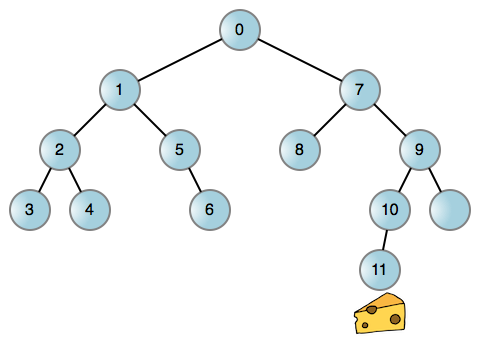
가장자리(선)에 도달할 때마다 마우스를 왼쪽이나 오른쪽으로 돌려 새로운 위치에 도달하세요. 회전하는 방향 중 어느 방향으로든 막히면 해당 모서리가 존재하지 않는다는 의미입니다. 이제 토론해 봅시다! 호출 스택을 사용하든 다른 데이터 구조를 사용하든 이 프로세스는 재귀 프로세스와 분리될 수 없습니다. 그리고 호출 스택을 사용하는 것은 매우 쉽습니다:
으아악재귀 미로 해결 다운로드
maze.c:13에서 치즈를 찾으면 스택은 다음과 같습니다. 또한 명령을 사용하여 수집된 데이터인 GDB 출력에서 더 자세한 데이터를 볼 수도 있습니다.

재귀를 사용하기에 적합한 문제이기 때문에 재귀의 좋은 동작을 보여줍니다. 이는 놀라운 일이 아닙니다. 알고리즘의 경우 재귀는 예외가 아닌 규칙입니다. 이는 검색할 때, 트리 및 기타 데이터 구조를 탐색할 때, 구문 분석할 때, 정렬해야 할 때 등 어디에나 나타납니다. 파이나 e가 우주의 모든 것의 기초이기 때문에 수학에서 "신"으로 알려진 것처럼, 재귀도 동일합니다. 즉, 계산 구조에만 존재합니다.
Steven Skienna의 훌륭한 저서 A Guide to Algorithm Design의 장점은 그가 "전쟁 이야기"를 통해 자신의 작업을 실제 문제 해결 뒤에 숨은 알고리즘을 보여주는 수단으로 해석한다는 것입니다. 이것은 알고리즘에 대한 지식을 확장하는 데 제가 아는 최고의 리소스입니다. 또 다른 자료는 LISP 구현에 관한 McCarthy의 원본 논문입니다. 재귀는 언어의 이름이자 기본 원리입니다. 논문은 읽기 쉽고 흥미롭고, 석사의 작업을 직장에서 보는 것은 매우 흥미롭습니다.
回到迷宫问题上。虽然它在这里很难离开递归,但是并不意味着必须通过调用栈的方式来实现。你可以使用像 RRLL 这样的字符串去跟踪转向,然后,依据这个字符串去决定老鼠下一步的动作。或者你可以分配一些其它的东西来记录追寻奶酪的整个状态。你仍然是实现了一个递归的过程,只是需要你实现一个自己的数据结构。
那样似乎更复杂一些,因为栈调用更合适。每个栈帧记录的不仅是当前节点,也记录那个节点上的计算状态(在这个案例中,我们是否只让它走左边,或者已经尝试向右)。因此,代码已经变得不重要了。然而,有时候我们因为害怕溢出和期望中的性能而放弃这种优秀的算法。那是很愚蠢的!
正如我们所见,栈空间是非常大的,在耗尽栈空间之前往往会遇到其它的限制。一方面可以通过检查问题大小来确保它能够被安全地处理。而对 CPU 的担心是由两个广为流传的有问题的示例所导致的:哑阶乘dumb factorial和可怕的无记忆的 O( 2n ) Fibonacci 递归。它们并不是栈递归算法的正确代表。
事实上栈操作是非常快的。通常,栈对数据的偏移是非常准确的,它在 缓存 中是热数据,并且是由专门的指令来操作它的。同时,使用你自己定义的在堆上分配的数据结构的相关开销是很大的。经常能看到人们写的一些比栈调用递归更复杂、性能更差的实现方法。最后,现代的 CPU 的性能都是 非常好的 ,并且一般 CPU 不会是性能瓶颈所在。在考虑牺牲程序的简单性时要特别注意,就像经常考虑程序的性能及性能的测量那样。
下一篇文章将是探秘栈系列的最后一篇了,我们将了解尾调用、闭包、以及其它相关概念。然后,我们就该深入我们的老朋友—— Linux 内核了。感谢你的阅读!

위 내용은 소프트웨어 개발의 재귀 작업의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Linux Architecture : 5 개의 기본 구성 요소를 공개합니다
Apr 20, 2025 am 12:04 AM
Linux Architecture : 5 개의 기본 구성 요소를 공개합니다
Apr 20, 2025 am 12:04 AM
Linux 시스템의 5 가지 기본 구성 요소는 다음과 같습니다. 1. Kernel, 2. System Library, 3. System Utilities, 4. 그래픽 사용자 인터페이스, 5. 응용 프로그램. 커널은 하드웨어 리소스를 관리하고 시스템 라이브러리는 사전 컴파일 된 기능을 제공하며 시스템 유틸리티는 시스템 관리에 사용되며 GUI는 시각적 상호 작용을 제공하며 응용 프로그램은 이러한 구성 요소를 사용하여 기능을 구현합니다.
 git의 창고 주소를 확인하는 방법
Apr 17, 2025 pm 01:54 PM
git의 창고 주소를 확인하는 방법
Apr 17, 2025 pm 01:54 PM
git 저장소 주소를 보려면 다음 단계를 수행하십시오. 1. 명령 줄을 열고 리포지토리 디렉토리로 이동하십시오. 2. "git remote -v"명령을 실행하십시오. 3. 출력 및 해당 주소에서 저장소 이름을 봅니다.
 코드를 작성한 후 숭고한 실행 방법
Apr 16, 2025 am 08:51 AM
코드를 작성한 후 숭고한 실행 방법
Apr 16, 2025 am 08:51 AM
Sublime에서 코드를 실행하는 6 가지 방법이 있습니다. 핫키, 메뉴, 빌드 시스템, 명령 줄, 기본 빌드 시스템 설정 및 사용자 정의 빌드 명령, 프로젝트/파일을 마우스 오른쪽 단추로 클릭하여 개별 파일/프로젝트를 실행합니다. 빌드 시스템 가용성은 숭고한 텍스트 설치에 따라 다릅니다.
 Apr 16, 2025 pm 07:39 PM
Apr 16, 2025 pm 07:39 PM
메모장은 Java 코드를 직접 실행할 수는 없지만 다른 도구를 사용하여 명령 줄 컴파일러 (Javac)를 사용하여 Bytecode 파일 (filename.class)을 생성하면 달성 할 수 있습니다. Java Interpreter (Java)를 사용하여 바이트 코드를 해석하고 코드를 실행하고 결과를 출력하십시오.
 vScode 이전 다음 바로 가기 키
Apr 15, 2025 pm 10:51 PM
vScode 이전 다음 바로 가기 키
Apr 15, 2025 pm 10:51 PM
vs 코드 1 단계/다음 단계 바로 가기 키 사용 : 1 단계 (뒤로) : Windows/Linux : Ctrl ←; MACOS : CMD ← 다음 단계 (앞으로) : Windows/Linux : Ctrl →; MACOS : CMD →
 Linux의 주요 목적은 무엇입니까?
Apr 16, 2025 am 12:19 AM
Linux의 주요 목적은 무엇입니까?
Apr 16, 2025 am 12:19 AM
Linux의 주요 용도에는 다음이 포함됩니다. 1. 서버 운영 체제, 2. 임베디드 시스템, 3. 데스크탑 운영 체제, 4. 개발 및 테스트 환경. Linux는이 분야에서 뛰어나 안정성, 보안 및 효율적인 개발 도구를 제공합니다.
 Laravel 설치 코드
Apr 18, 2025 pm 12:30 PM
Laravel 설치 코드
Apr 18, 2025 pm 12:30 PM
Laravel을 설치하려면 다음 단계를 순서대로 수행하십시오. Composer 설치 (MacOS/Linux 및 Windows) 설치 LARAVEL 설치 프로그램 새 프로젝트 시작 서비스 액세스 애플리케이션 (URL : http://127.0.1:8000) 데이터베이스 연결 (필요한 경우)을 설정하십시오.
 vscode를 사용하는 방법
Apr 15, 2025 pm 11:21 PM
vscode를 사용하는 방법
Apr 15, 2025 pm 11:21 PM
Visual Studio Code (VSCODE)는 Microsoft가 개발 한 크로스 플랫폼, 오픈 소스 및 무료 코드 편집기입니다. 광범위한 프로그래밍 언어에 대한 가볍고 확장 성 및 지원으로 유명합니다. VSCODE를 설치하려면 공식 웹 사이트를 방문하여 설치 프로그램을 다운로드하고 실행하십시오. VScode를 사용하는 경우 새 프로젝트를 만들고 코드 편집, 디버그 코드, 프로젝트 탐색, VSCODE 확장 및 설정을 관리 할 수 있습니다. VSCODE는 Windows, MacOS 및 Linux에서 사용할 수 있으며 여러 프로그래밍 언어를 지원하며 Marketplace를 통해 다양한 확장을 제공합니다. 이점은 경량, 확장 성, 광범위한 언어 지원, 풍부한 기능 및 버전이 포함됩니다.
