Mamba c'est bien, mais son développement est encore précoce.
Il existe de nombreuses architectures de deep learning, mais la plus réussie de ces dernières années est Transformer, qui a établi sa position dominante dans de multiples domaines d'application. L'un des principaux facteurs d'un tel succès est le mécanisme d'attention, qui permet aux modèles basés sur Transformer de se concentrer sur les parties pertinentes pour la séquence d'entrée afin d'obtenir une meilleure compréhension du contexte. Cependant, l’inconvénient du mécanisme d’attention est que la charge de calcul est élevée, qui augmente quadratiquement avec la taille d’entrée, ce qui rend difficile le traitement de textes très longs. Heureusement, une nouvelle architecture à fort potentiel est née il y a quelques temps : le modèle de séquence spatiale d'états structurés (SSM). Cette architecture peut capturer efficacement des dépendances complexes dans les données de séquence, ce qui en fait un puissant adversaire de Transformer. La conception de ce type de modèle s'inspire du modèle classique d'espace d'états - nous pouvons le considérer comme un modèle de fusion de réseaux de neurones récurrents et de réseaux de neurones convolutifs. Ils peuvent être calculés efficacement à l’aide d’opérations de boucle ou de convolution, permettant à la charge de calcul d’évoluer de manière linéaire ou presque linéaire avec la longueur de la séquence, réduisant ainsi considérablement les coûts de calcul. Plus précisément, les capacités de modélisation de Mamba, l'une des variantes les plus réussies de SSM, sont déjà comparables à celles de Transformer, tout en conservant une évolutivité linéaire avec la longueur de la séquence. Mamba introduit d'abord un mécanisme de sélection simple mais efficace qui reparamétre SSM en fonction de l'entrée, permettant au modèle de conserver indéfiniment les données nécessaires et pertinentes tout en filtrant les informations non pertinentes. Mamba inclut ensuite un algorithme sensible au matériel qui calcule le modèle de manière itérative à l'aide d'analyses au lieu de convolutions, ce qui entraîne une accélération 3x sur le GPU A100. Comme le montre la figure 1, avec sa puissante capacité à modéliser des données de séquences longues complexes et son évolutivité quasi linéaire, Mamba est devenu un modèle de base et devrait révolutionner la vision par ordinateur, le traitement du langage naturel, les soins médicaux et bien d'autres. d'autres domaines de recherche et d'application. 
Par conséquent, la littérature sur la recherche et l'application de Mamba se développe rapidement et est vertigineuse. Un rapport d'examen complet serait d'un grand bénéfice. Récemment, une équipe de recherche de l'Université polytechnique de Hong Kong a publié sa contribution sur arXiv.
- Titre de l'article : A Survey of Mamba
- Adresse de l'article : https://arxiv.org/pdf/2408.01129
Ce rapport d'examen examine Mamba sous plusieurs angles. Ce résumé peut aide non seulement les débutants à apprendre le mécanisme de fonctionnement de base de Mamba, mais aide également les praticiens expérimentés à comprendre les derniers progrès. Mamba est une direction de recherche populaire, et par conséquent de nombreuses équipes tentent de rédiger des rapports de révision en plus de celui présenté dans cet article, il existe d'autres revues axées sur les modèles spatiaux d'état ou Mamba visuel. reportez-vous à l'article correspondant :
Mamba-360 : Enquête sur les modèles d'espace d'état comme alternative de transformateur pour la modélisation de séquences longues : méthodes, applications et défis arXiv : 2404.16112
Modèle d'espace d'état pour une alternative de réseau de nouvelle génération à. transformateurs : une enquête. arXiv : 2404.09516
-
Vision Mamba : une enquête complète et une taxonomie. arXiv : 2404.15956
.
Mamba 集中了循环神经网络(RNN)的循环框架、Transformer 的并行计算和注意力机制、状态空间模型(SSM)的线性特性。因此,为了透彻地理解 Mamba,就必需先理解这三种架构。循环神经网络(RNN)具有保留内部记忆的能力,因此很擅长处理序列数据。具体来说,在每个离散时间步骤 k,标准 RNN 在处理一个向量时会连同前一时间步骤的隐藏状态一起处理,之后输出另一个向量并更新隐藏状态。这个隐藏状态就可作为 RNN 的记忆,其能保留过去已见过的输入的信息。这种动态记忆让 RNN 可处理不同长度的序列。也就是说,RNN 是一种非线性的循环模型,可通过使用存储在隐藏状态中历史知识来有效地捕获时间模式。Transformer 的自注意力机制有助于捕获输入之中的全局依赖。其实现方式是基于每个位置相对于其它位置的重要程度为它们分配权重。更具体而言,首先对原始输入进行线性变换,将输入向量的序列 x 转换成三类向量:查询 Q、键 K 和值 V。然后计算归一化的注意力分数 S 并计算注意力权重。除了可以执行单个注意力函数,我们还可以执行多头注意力。这让模型可以捕获不同类型的关系,并从多个视角理解输入序列。多头注意力会使用多组自注意力模块并行地处理输入序列。其中每个头都独立运作,执行的计算与标准自注意力机制一样。之后,将每个头的注意力权重汇聚组合,得到值向量的加权和。这个聚合步骤可让模型使用来自多个头的信息并捕获输入序列中的多种不同模式和关系。状态空间模型(SSM)是一种传统的数学框架,可用于描述系统随时间变化的动态行为。近些年来,人们已将 SSM 广泛应用于控制论、机器人学和经济学等多个不同领域。究其核心,SSM 是通过一组名为「状态」的隐藏变量来体现系统的行为,使其能有效捕获时间数据的依赖关系。不同于 RNN,SSM 是一种具有关联(associative)属性的线性模型。具体来说,经典的状态空间模型会构建两个关键方程(状态方程和观察方程),以通过一个 N 维的隐藏状态 h (t) 建模当前时间 t 时输入 x 与输出 y 之间的关系。
为了满足机器学习的需求,SSM 必需经历一个离散化过程 —— 将连续参数转变成离散参数。通常来说,离散化方法的目标是将连续时间划分为具有尽可能相等积分面积的 K 个离散区间。为了实现这一目标,SSM 采用的最具代表性的解决方案之一是 Zero-Order Hold(ZOH),其假设区间 Δ = [?_{?−1}, ?_? ] 上的函数值保持不变。离散 SSM 与循环神经网络结构相似,因此离散 SSM 能比基于 Transformer 的模型更高效地执行推理过程。
离散 SSM 是一个具有结合属性的线性系统,因此可以与卷积计算无缝整合。RNN、Transformer 和 SSM 之间的关系图 2 展示了 RNN、Transformer 和 SSM 的计算算法。
一方面,常规 RNN 的运作基于一种非线性的循环框架,其中每个计算都仅依赖于之前的隐藏状态和当前输入。尽管这种形式可让 RNN 在自回归推理时快速生成输出,但它也让 RNN 难以充分利用 GPU 的并行计算能力,导致模型训练速度变慢。另一方面,Transformer 架构是在多个「查询 - 键」对上并行执行矩阵乘法,而矩阵乘法可以高效地分配给硬件资源,从而更快地训练基于注意力的模型。但是,如果要让基于 Transformer 的模型生成响应或预测,则推理过程会非常耗时。不同于仅支持一类计算的 RNN 和 Transformer,离散 SSM 灵活性很高;得益于其线性性质,它既能支持循环计算,也可支持卷积计算。这种特性让 SSM 不仅能实现高效推理,也能实现并行训练。但是,需要指出,最常规的 SSM 是时不变的,也就是说其 A、B、C 和 Δ 与模型输入 x 无关。这会限制其上下文感知型建模的能力,导致 SSM 在选择性复制等一些特定任务上表现不佳。Mamba-1:使用硬件感知型算法的选择式状态空间模型Mamba-1 基于结构化状态空间模型引入了三大创新技术,即基于高阶多项式投影算子(HiPPO)的内存初始化、选择机制和硬件感知型计算。如图 3 所示。这些技术的目标是提升 SSM 的长程线性时间序列建模能力。
구체적으로 초기화 전략은 일관된 숨겨진 상태 매트릭스를 구성하여 장거리 메모리를 효과적으로 촉진할 수 있습니다. 그런 다음 선택 메커니즘을 통해 SSM은 인지 가능한 콘텐츠의 표현을 얻을 수 있습니다. 마지막으로 Mamba에는 훈련 효율성을 높이기 위해 병렬 연관 스캔과 메모리 재계산이라는 두 가지 하드웨어 인식 컴퓨팅 알고리즘도 포함되어 있습니다. Mamba-2: State Space Dual Transformer는 매개변수 효율적인 미세 조정, 치명적인 망각 완화, 모델 양자화 등 다양한 기술 개발에 영감을 주었습니다. 상태 공간 모델이 원래 Transformer용으로 개발된 이러한 기술의 이점을 활용하기 위해 Mamba-2는 SSD(Structured State Space Duality)라는 새로운 프레임워크를 도입했습니다. 이 프레임워크는 이론적으로 SSM과 다양한 형태의 주의를 연결합니다. 본질적으로 SSD는 Transformer에서 사용되는 주의 메커니즘과 SSM에서 사용되는 선형 시불변 시스템이 모두 반분리형 행렬 변환으로 볼 수 있음을 보여줍니다. 또한 Albert Gu와 Tri Dao는 선택적 SSM이 반분리형 마스크 매트릭스를 사용하여 구현된 구조화된 선형 주의 메커니즘과 동일하다는 것을 증명했습니다. Mamba-2는 블록 분해 행렬 곱셈 알고리즘을 사용하여 하드웨어를 보다 효율적으로 사용할 수 있는 SSD 기반의 컴퓨팅 방식을 설계합니다. 구체적으로, Mamba-2는 이 행렬 변환을 통해 상태 공간 모델을 반 분리 가능한 행렬로 처리함으로써 이 계산을 행렬 블록으로 분해할 수 있습니다. 여기서 대각선 블록은 블록 내 계산을 나타냅니다. 비대각선 블록은 SSM의 숨겨진 상태 분해를 통한 블록 간 계산을 나타냅니다. 이 방법을 사용하면 Mamba-2는 Mamba-1의 병렬 상관관계 스캔보다 2~8배 더 빠르게 훈련하는 동시에 Transformer와 비슷한 성능을 달성할 수 있습니다. 맘바-1과 맘바-2의 블록 디자인을 살펴보겠습니다. 그림 4에서는 두 아키텍처를 비교합니다.
Mamba-1은 SSM을 중심으로 설계되었으며, 여기서 선택적 SSM 계층은 입력 시퀀스 X에서 Y로의 매핑을 수행하는 작업을 수행합니다. 이 설계에서는 처음에 X의 선형 투영을 생성한 후 (A, B, C)의 선형 투영이 사용됩니다. 그런 다음, 입력 토큰과 상태 행렬은 병렬 상관을 사용하여 선택적 SSM 장치를 통해 스캔되어 출력 Y를 얻습니다. 이후 Mamba-1은 기능 재사용을 장려하고 모델 훈련 중에 자주 발생하는 성능 저하를 완화하기 위해 건너뛰기 연결을 채택합니다. 마지막으로 Mamba 모델은 이 모듈을 표준 정규화와 잔여 연결을 교대로 쌓아서 구성됩니다. Mamba-2의 경우 [X, A, B, C]에서 Y로의 매핑을 생성하기 위해 SSD 계층이 도입되었습니다. 이는 표준 주의 아키텍처가 Q, K, V 투영을 병렬로 생성하는 방법과 유사하게 블록 시작 부분에서 단일 투영을 사용하여 [X, A, B, C]를 동시에 처리함으로써 수행됩니다. 즉, Mamba-2 블록은 Mamba-1 블록을 기반으로 시퀀스 선형 투영을 제거하여 단순화되었습니다. 이를 통해 SSD 패브릭을 Mamba-1의 병렬 선택 스캔보다 빠르게 계산할 수 있습니다. 또한 훈련 안정성을 향상시키기 위해 Mamba-2는 건너뛰기 연결 뒤에 정규화 계층도 추가합니다. 상태 공간 모델과 Mamba는 최근 빠르게 발전하여 큰 잠재력을 지닌 기본 모델 백본 네트워크 선택이 되었습니다. Mamba는 자연어 처리 작업에서는 잘 수행되지만 메모리 손실, 다른 작업으로 일반화하기 어려움, 복잡한 패턴에서의 성능은 Transformer 기반 언어 모델만큼 좋지 않은 등 여전히 몇 가지 문제가 있습니다. 이러한 문제를 해결하기 위해 연구 커뮤니티에서는 Mamba 아키텍처에 대한 많은 개선 사항을 제안했습니다. 기존 연구는 주로 수정 블록 설계, 스캔 패턴 및 메모리 관리에 중점을 두고 있습니다. 표 1은 관련 연구를 카테고리별로 요약한 것입니다.
맘바 블록의 디자인과 구조는 맘바 모델의 전반적인 성능에 큰 영향을 미치기 때문에 이곳이 주요 연구 핫스팟이 되었습니다.
如图 5 所示,基于构建新 Mamba 模块的不同方法,现有研究可以分为三类:
- 集成方法:将 Mamba 块与其它模型集成到一起,实现效果与效率的平衡;
- 替换方法:用 Mamba 块替换其它模型框架中的主要层;
并行关联扫描是 Mamba 模型内的一大关键组件,其目标是解决由选择机制导致的计算问题、提升训练过程速度以及降低内存需求。其实现方式是利用时变的 SSM 的线性性质来在硬件层级上设计核融合和重新计算。但是,Mamba 的单向序列建模范式不利于全面学习多样化的数据,比如图像和视频。
为缓解这一问题,一些研究者探索了新的高效扫描方法,以提升 Mamba 模型的性能以及促进其训练过程。如图 6 所示,在开发扫描模式方面,现有的研究成果可以分为两类:
- 展平式扫描方法:以展平的视角看待 token 序列,并基于此处理模型输入;
- 立体式扫描方法:跨维度、通道或尺度扫描模型输入,这又可进一步分为三类:分层扫描、时空扫描、混合扫描。
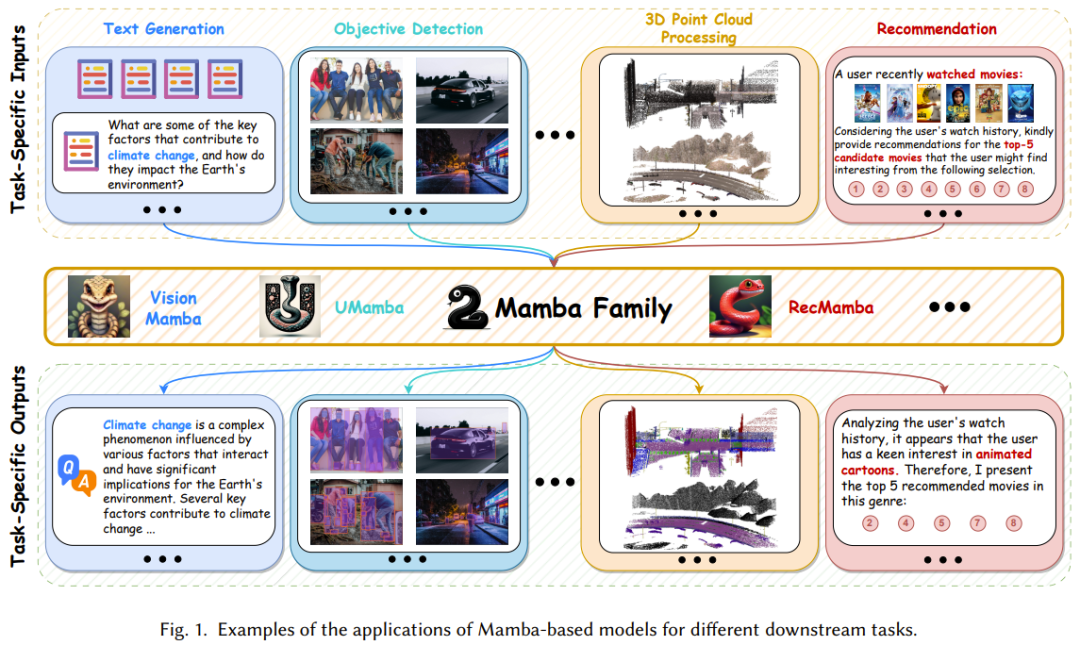
类似于 RNN,在状态空间模型内,隐藏状态的记忆有效地存储了之前步骤的信息,因此对 SSM 的整体性能有着至关重要的影响。尽管 Mamba 引入了基于 HiPPO 的方法来进行记忆初始化,但管理 SSM 单元中的记忆依然难度很大,其中包括在层之前转移隐藏信息以及实现无损记忆压缩。为此,一些开创性研究提出了一些不同的解决方案,包括记忆的初始化、压缩和连接。Mamba 架构是选择式状态空间模型的一种扩展,其具备循环模型的基本特性,因而非常适合作为处理文本、时间序列、语音等序列数据的通用基础模型。不仅如此,近期一些开创性研究更是扩展了 Mamba 架构的应用场景,使其不仅能处理序列数据,还能用于图像和图谱等领域,如图 7 所示。
这些研究的目标是既充分利用 Mamba 能获取长程依赖关系的出色能力,也让其发挥学习和推理过程中的效率优势。表 2 简单总结了这些研究成果。
Data jujukan merujuk kepada data yang dikumpul dan disusun dalam susunan tertentu, di mana susunan titik data adalah penting. Laporan semakan ini secara menyeluruh meringkaskan aplikasi Mamba pada pelbagai data jujukan, termasuk bahasa semula jadi, video, siri masa, pertuturan dan data pergerakan manusia. Lihat kertas asal untuk butiran. Tidak seperti data jujukan, data bukan urutan tidak mengikut susunan tertentu. Titik datanya boleh disusun dalam sebarang susunan tanpa menjejaskan makna data dengan ketara. Kekurangan susunan yang wujud ini boleh menjadi sukar untuk model berulang (RNN, SSM, dll.) yang direka khusus untuk menangkap kebergantungan temporal dalam data. Anehnya, beberapa penyelidikan baru-baru ini telah berjaya membolehkan Mamba (wakil SSM) memproses data bukan urutan dengan cekap, termasuk imej, peta dan data awan titik. Untuk meningkatkan persepsi AI dan keupayaan pemahaman adegan, berbilang data modal boleh disepadukan, seperti bahasa (data berjujukan) dan imej (data bukan urutan). Penyepaduan sedemikian boleh memberikan maklumat yang sangat berharga dan pelengkap. Sejak kebelakangan ini, model bahasa besar berbilang mod (MLLM) telah menjadi tumpuan penyelidikan yang paling popular; model jenis ini mewarisi keupayaan hebat model bahasa besar (LLM), termasuk ekspresi bahasa yang berkuasa dan keupayaan penaakulan logik. Walaupun Transformer telah menjadi kaedah dominan dalam bidang ini, Mamba juga muncul sebagai pesaing yang kuat dalam menjajarkan data sumber bercampur dan mencapai penskalaan kerumitan linear dengan panjang jujukan menjadikan Mamba menjanjikan dalam pembelajaran pelbagai mod. Berikut ialah beberapa aplikasi penting model berasaskan Mamba. Pasukan itu membahagikan aplikasi ini ke dalam kategori berikut: pemprosesan bahasa semula jadi, penglihatan komputer, analisis pertuturan, penemuan dadah, sistem pengesyoran dan sistem robotik dan autonomi. Kami tidak akan memperkenalkannya terlalu banyak di sini, sila lihat kertas asal untuk butirannya. Mamba Walaupun ia telah mencapai prestasi cemerlang dalam beberapa bidang, secara keseluruhannya, penyelidikan Mamba masih di peringkat awal, dan masih terdapat beberapa cabaran yang perlu diatasi. Sudah tentu, cabaran ini juga peluang.
- Cara untuk membangunkan dan menambah baik model asas berdasarkan Mamba; Cara meningkatkan Mamba Kredibiliti model, yang memerlukan penyelidikan lanjut tentang keselamatan dan keteguhan, keadilan, kebolehjelasan dan privasi
- Cara menggunakan teknologi baharu dalam medan Transformer untuk Mamba, seperti penalaan halus yang cekap parameter; dan bencana melupakan Mitigation, Retrieval Augmented Generation (RAG).
-
위 내용은 트랜스포머의 최강 경쟁자인 맘바를 이해하기 위한 한 편의 글의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



