
이전 블로그에서 APOC 및 Graph Data Science Library(GDS)라는 두 가지 플러그인을 사용하여 neo4j를 로컬에 설치하고 설정하는 방법을 살펴보았습니다. 이 블로그에서는 장난감 데이터세트(전자상거래 웹사이트의 제품)를 가져와 Neo4j에 저장하겠습니다.
사용 사례에 대용량 데이터가 있는 경우 데이터 로드를 시작하기 전에 neo4j에 충분한 양의 메모리가 할당되었는지 확인하세요. 그러려면 :



그래프에는 두 가지 주요 구성 요소인 노드와 관계가 있습니다. 먼저 노드를 만들고 나중에 관계를 설정해 보겠습니다.
내가 사용하는 데이터가 여기에 있습니다. - data
여기에 있는 요구 사항.txt를 사용하여 Python 가상 환경을 만듭니다 - 요구 사항.txt
데이터를 푸시하는 다양한 기능을 정의해 보겠습니다.
필요한 라이브러리 가져오기
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
import pandas as pd
from neo4j import GraphDatabase
from openai import OpenAI
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CREATE CATEGORY
query_list = create_category(product_data_df)
execute_bulk_query(query_list)
# CREATE PRODUCT
query_list = create_product(product_data_df)
execute_bulk_query(query_list)
from neo4j import GraphDatabase
import pandas as pd
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def create_category_food_relationship_query(product_data_df):
"""
Used to create relationship between category and products
:param product_data_df: dataframe - data
:return: query_list: list - cypher queries
"""
query = """MATCH (c:Category {name: '%s'}), (p:Product {name: '%s'}) CREATE (c)-[:CATEGORY_CONTAINS_PRODUCT]->(p)"""
query_list = []
for idx, row in product_data_df.iterrows():
query_list.append(query % (row['Category'], row['Product Name']))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CATEGORY - FOOD RELATIONSHIP
query_list = create_category_food_relationship_query(product_data_df)
execute_bulk_query(query_list)
열기 아이콘 위에 마우스를 놓고 neo4j 브라우저를 클릭하여 우리가 만든 노드를 시각화하세요.
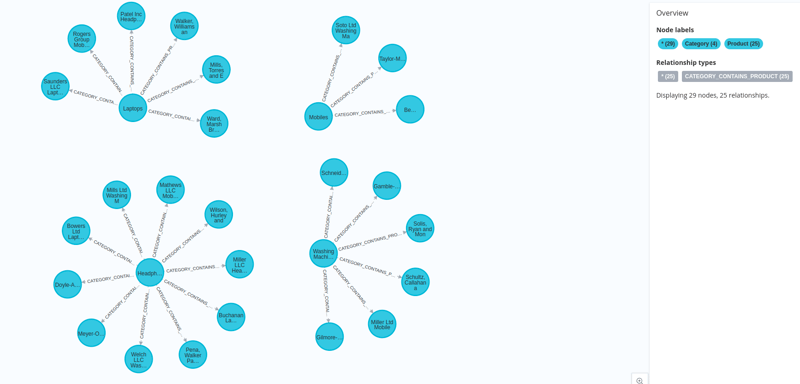
그리고 우리의 데이터는 임베딩과 함께 neo4j에 로드됩니다.
앞으로 나올 블로그에서는 Python을 사용하여 그래프 쿼리 엔진을 구축하고 가져온 데이터를 사용하여 증강 생성을 수행하는 방법을 살펴보겠습니다.
도움이 되길 바랍니다... 또 뵙겠습니다!!!
링크드인 - https://www.linkedin.com/in/praveenr2998/
Github - https://github.com/praveenr2998/Creating-Lightweight-RAG-Systems-With-Graphs/tree/main/push_data_to_db
위 내용은 Neo4j에 데이터 로드의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



