Désormais, Long Context Visual Language Model (VLM) dispose d'une nouvelle solution full-stack - LongVILA, qui intègre le système, la formation de modèles et le développement d'ensembles de données.
이 단계에서는 모델에 대한 다중 모드 이해와 긴 컨텍스트 기능을 결합하는 것이 매우 중요합니다. 모델과 상호작용하는 방법. 그리고 긴 컨텍스트를 통해 모델은 긴 문서 및 긴 비디오와 같은 더 많은 정보를 처리할 수 있으며, 이 기능은 더 많은 실제 애플리케이션에 필요한 기능도 제공합니다. 그러나 현재의 문제는 일부 작업에서 긴 상황의 시각적 언어 모델(VLM)을 활성화했지만 일반적으로 포괄적인 솔루션을 제공하기보다는 단순화된 접근 방식을 사용한다는 것입니다. 풀 스택 디자인은 긴 상황의 시각적 언어 모델에 매우 중요합니다. 대규모 모델을 훈련하는 것은 일반적으로 데이터 엔지니어링과 시스템 소프트웨어 공동 설계가 필요한 복잡하고 체계적인 작업입니다. 텍스트 전용 LLM과 달리 VLM(예: LLaVA)에는 고유한 모델 아키텍처와 유연한 분산 교육 전략이 필요한 경우가 많습니다. 또한 긴 컨텍스트 모델링에는 긴 컨텍스트 데이터뿐만 아니라 메모리 집약적인 긴 컨텍스트 훈련을 지원할 수 있는 인프라도 필요합니다. 따라서 긴 컨텍스트 VLM에는 잘 계획된 전체 스택 설계(시스템, 데이터 및 파이프라인 포함)가 필수적입니다. 이 기사에서는 NVIDIA, MIT, UC Berkeley 및 University of Texas at Austin의 연구원들이 시스템 설계, 모델 훈련을 포함한 긴 상황의 시각적 언어 모델을 훈련하고 배포하기 위한 풀스택 솔루션인 LongVILA를 소개합니다. 전략 및 데이터 세트 구성.
- 문서 주소: https://arxiv.org/pdf/2408.10188
- 코드 주소: https://github.com/NVlabs/VILA/blob/main/LongVILA.md
- 논문 제목: LONGVILA: SCALING LONG-CONTEXT VISUAL LANGUAGE MODELS FOR LONG VIDEOS
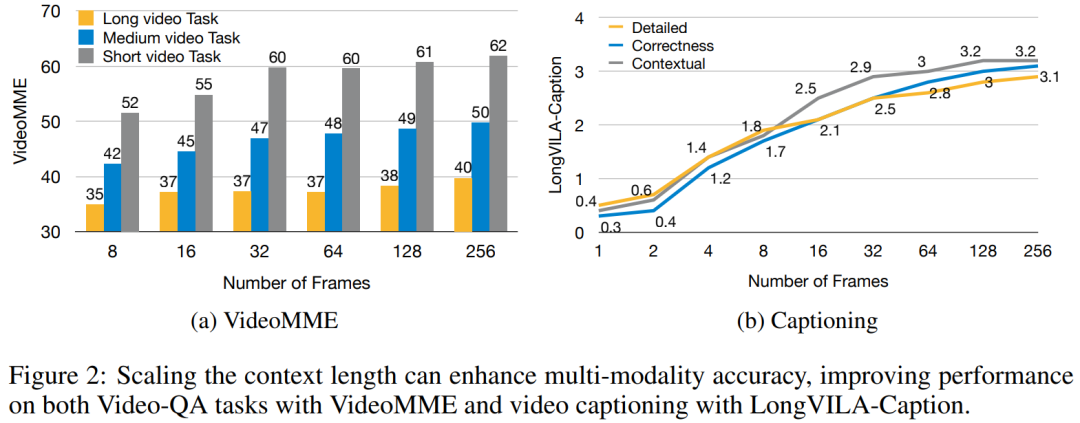
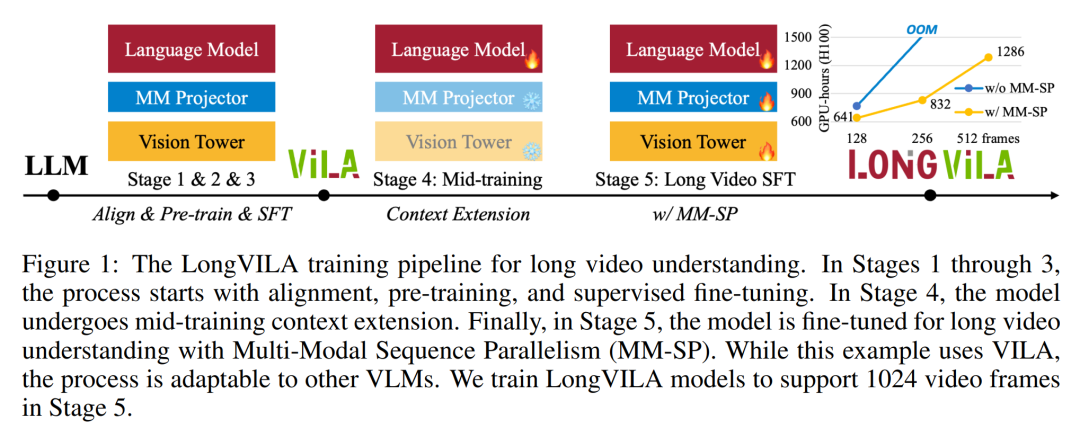
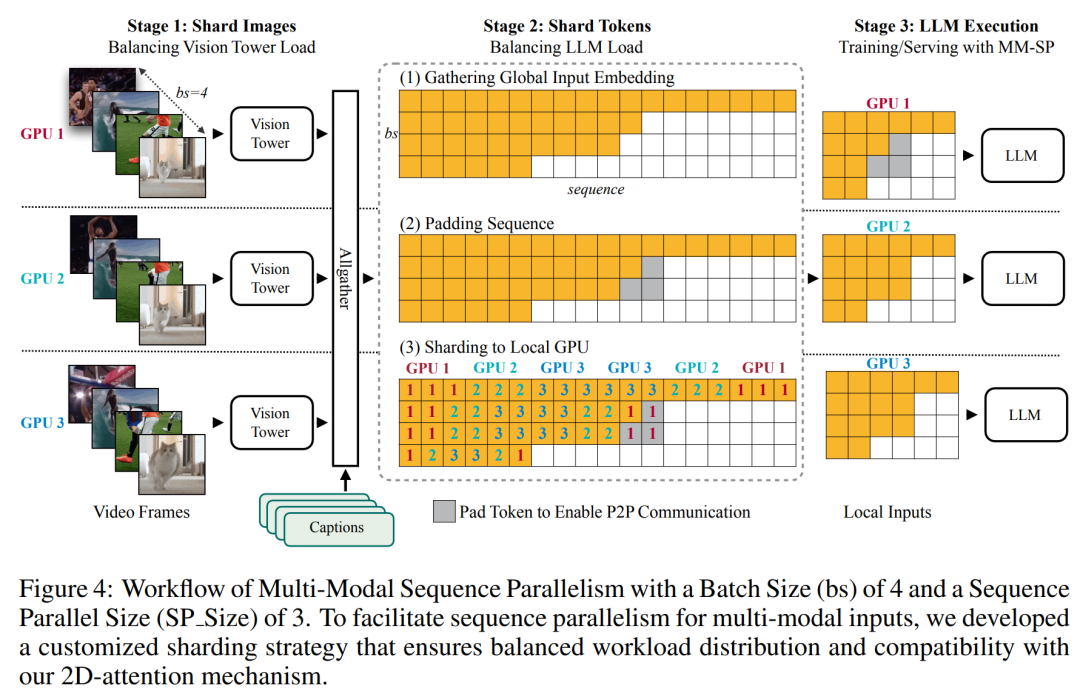
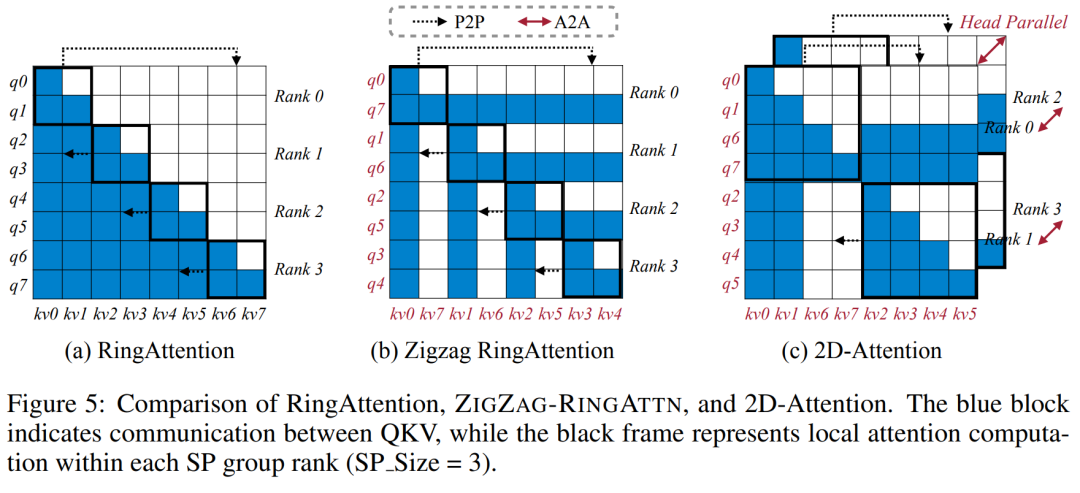
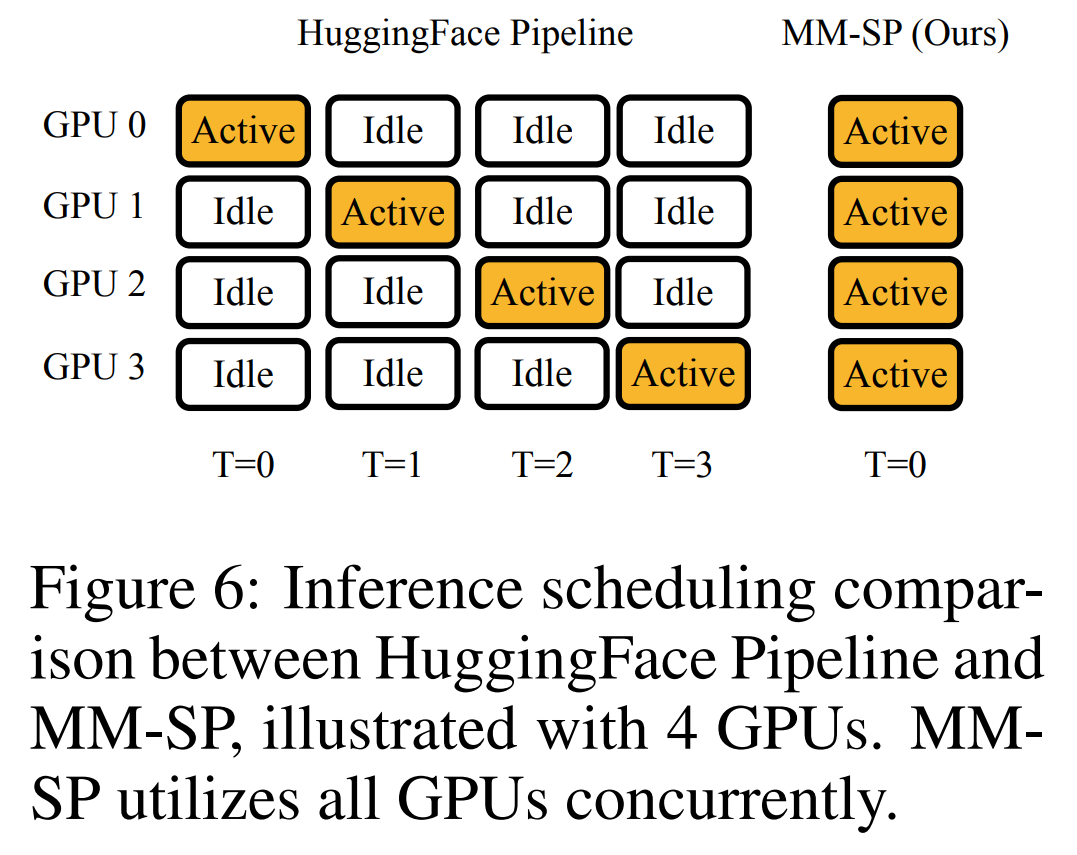
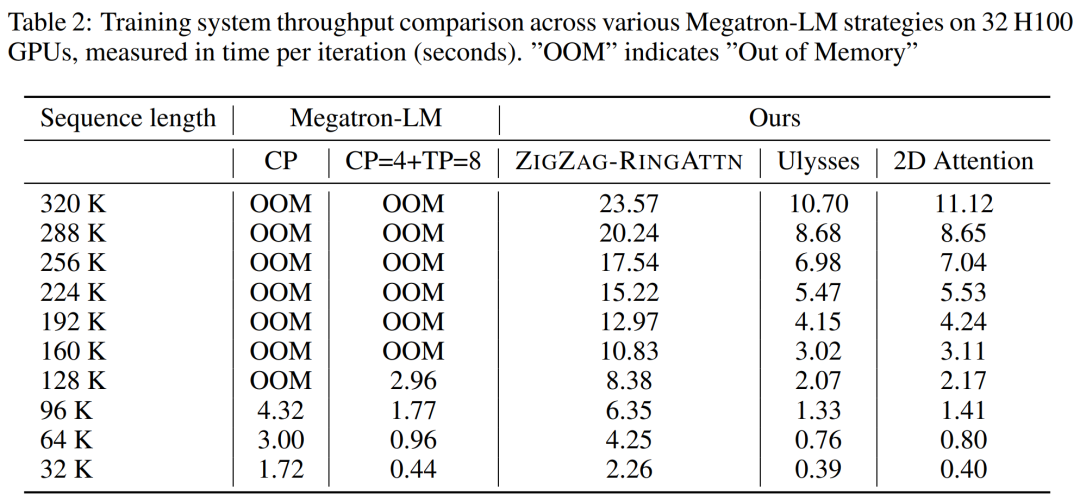
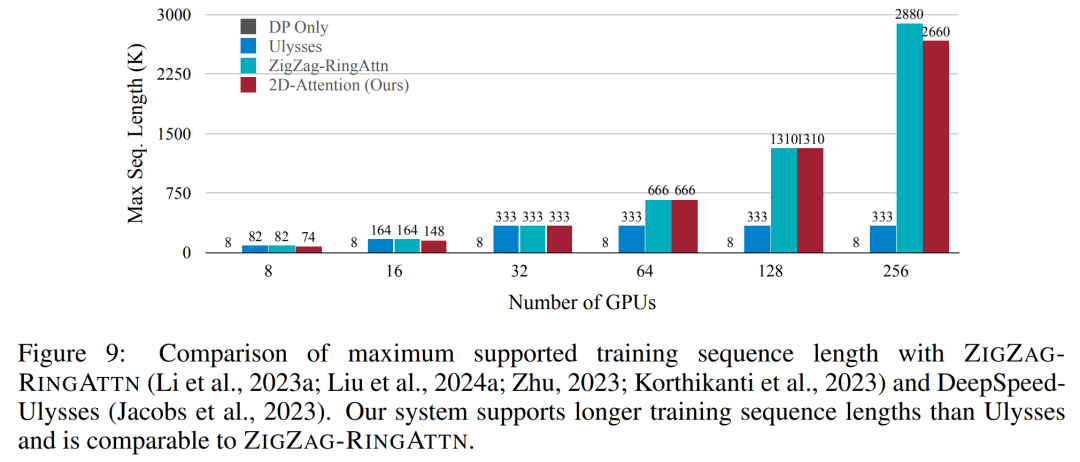
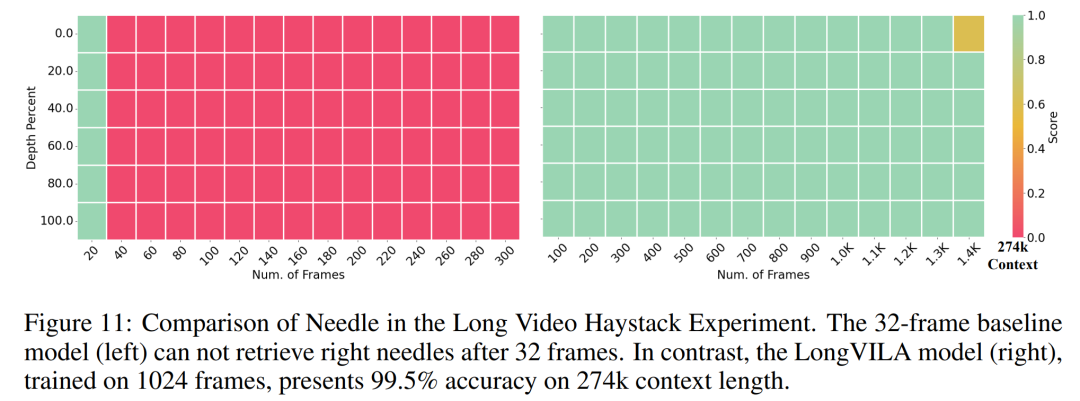
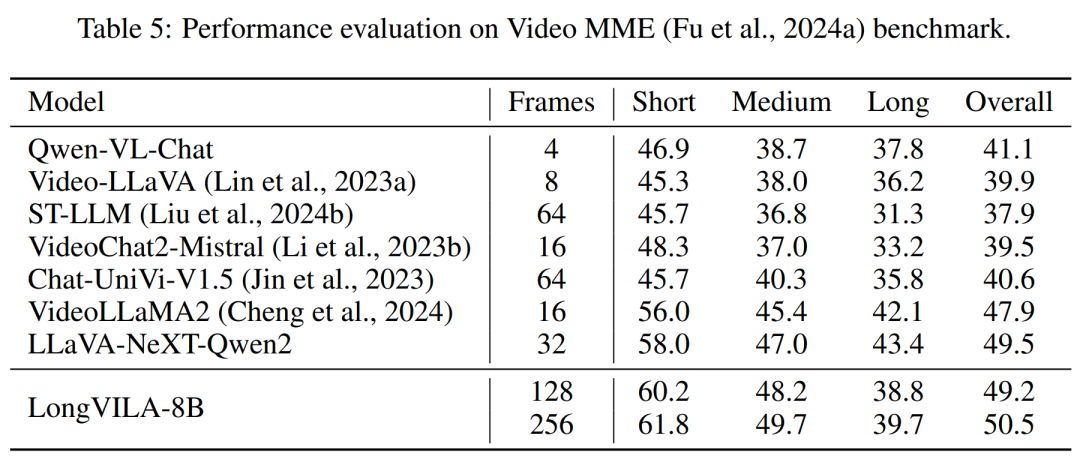
교육 인프라를 위해 이 연구에서는 효율적이고 사용자 친화적인 프레임워크, 즉 MM-SP(Multimodal Sequence Parallel)를 구축했습니다. ), 훈련 메모리 - 조밀한 긴 컨텍스트 VLM을 지원합니다. 학습 파이프라인의 경우 연구원들은 그림 1과 같이 5단계 학습 프로세스를 구현했습니다. 즉, (1) 다중 모달 정렬, (2) 대규모 사전 학습, (3) 단기 학습 감독 미세 조정, (4) LLM의 상황별 확장, (5) 장기 감독 미세 조정. 추론을 위해 MM-SP는 매우 긴 시퀀스를 처리할 때 병목 현상이 발생할 수 있는 KV 캐시 메모리 사용 문제를 해결합니다. LongVILA를 사용하여 비디오 프레임 수를 늘린 실험 결과에 따르면 이 연구의 성능은 VideoMME 및 긴 비디오 자막 작업에서 지속적으로 향상되는 것으로 나타났습니다(그림 2). 1024개 프레임으로 훈련된 LongVILA 모델은 1400개 프레임의 건초 더미 속 바늘 실험에서 99.5%의 정확도를 달성했습니다. 이는 274k 토큰의 컨텍스트 길이에 해당합니다. 또한 MM-SP 시스템은 그라데이션 체크포인트 없이 컨텍스트 길이를 200만 토큰까지 효과적으로 확장할 수 있어 링 시퀀스 병렬 처리에 비해 2.1배~5.7배의 속도 향상을 달성하고 메가트론 컨텍스트 병렬 처리+ 텐서 병렬 처리는 비해 1.1배~1.4배의 속도 향상을 달성합니다. 텐서 병렬로. 아래 사진은 긴 영상 자막을 처리할 때 LongVILA 기술을 적용한 예입니다. 자막 시작 부분에는 8프레임 기준 모델이 정적인 이미지와 차량 2대만 설명하고 있습니다. 이에 비해 LongVILA의 256개 프레임은 차량의 전면, 후면, 측면 뷰를 포함하여 눈 위의 자동차를 묘사합니다. 세부적으로 256프레임 LongVILA는 8프레임 기본 모델에서 누락된 점화 버튼, 기어 레버 및 계기판의 클로즈업도 묘사합니다. 긴 컨텍스트 VLM(시각적 언어 모델)을 교육하면 상당한 메모리 요구 사항이 발생합니다. 예를 들어, 아래 그림 1의 5단계의 긴 비디오 훈련에서 단일 시퀀스에는 1024개의 비디오 프레임을 생성하는 200K 토큰이 포함되어 있으며 이는 단일 GPU의 메모리 용량을 초과합니다. 연구원들은 시퀀스 병렬성을 기반으로 맞춤형 시스템을 개발했습니다. 순차 병렬 처리는 텍스트 전용 LLM 교육을 최적화하기 위해 현재 기본 모델 시스템에서 일반적으로 사용되는 기술입니다. 그러나 연구원들은 기존 시스템이 긴 컨텍스트의 VLM 작업 부하를 처리할 만큼 효율적이지도 않고 확장성도 없다는 사실을 발견했습니다.연구원들은 기존 시스템의 한계를 확인한 후 이상적인 다중 모드 시퀀스 병렬 접근 방식은 모달 및 네트워크 이질성을 해결하여 효율성과 확장성을 우선시해야 하며 확장성은 주의 헤드 수에 의해 제한되어서는 안 된다는 결론을 내렸습니다. MM-SP 워크플로. 모달 이질성 문제를 해결하기 위해 연구자들은 이미지 인코딩 및 언어 모델링 단계에서 계산 작업 부하를 최적화하는 2단계 샤딩 전략을 제안합니다. 아래 그림 4에 표시된 것처럼 첫 번째 단계에서는 먼저 순차 병렬 프로세스 그룹 내의 장치 간에 이미지(예: 비디오 프레임)를 균등하게 배포하여 이미지 인코딩 단계에서 로드 밸런싱을 달성합니다. 두 번째 단계에서 연구원은 토큰 수준 샤딩을 위한 글로벌 시각적 및 텍스트 입력을 집계합니다. 2D 주의 병렬 처리. 네트워크 이질성을 해결하고 확장성을 달성하기 위해 연구자들은 링 시퀀스 병렬성과 Ulysses 시퀀스 병렬성의 장점을 결합합니다. 구체적으로 시퀀스 차원 또는 주의 헤드 차원에 걸친 병렬성을 "1D SP"로 간주합니다. 이 방법은 어텐션 헤드와 시퀀스 차원에 걸쳐 병렬 계산을 통해 확장되어 1D SP를 링(P2P) 및 Ulysses(A2A) 프로세스의 독립적인 그룹으로 구성된 2D 그리드로 변환합니다. 아래 그림 3의 왼쪽과 같이 2개 노드에 걸쳐 8도 시퀀스 병렬성을 달성하기 위해 연구원은 2D-SP를 사용하여 4×2 통신 그리드를 구축했습니다. 또한 아래 그림 5에서 ZIGZAG-RINGATTN이 계산 균형을 맞추는 방법과 2D-Attention 메커니즘이 작동하는 방식을 추가로 설명하기 위해 연구원들은 다양한 방법을 사용하여 주의 계산 계획을 설명합니다. HuggingFace의 기본 파이프라인 병렬 전략과 비교할 때 이 기사의 추론 모드는 모든 장치가 동시에 계산에 참여하여 그림과 같이 컴퓨터 수에 비례하여 프로세스를 가속화하기 때문에 더 효율적입니다. 아래 6. 동시에 이 추론 모드는 확장 가능하며 메모리가 장치 전체에 고르게 분산되어 더 많은 시스템을 사용하여 더 긴 시퀀스를 지원합니다. 위에서 언급했듯이 LongVILA의 훈련 과정은 5단계로 완료됩니다. 각 단계의 주요 임무는 다음과 같습니다. Stage 1에서는 다중 모달 매퍼만 훈련할 수 있으며, 다른 매퍼는 동결됩니다. 2단계에서 연구원들은 시각적 인코더를 동결하고 LLM 및 다중 모드 매퍼를 훈련했습니다. 3단계에서 연구자들은 이미지 및 짧은 비디오 데이터 세트를 사용하는 등의 작업에 따라 짧은 데이터 지시를 위한 모델을 종합적으로 미세 조정합니다. 4단계에서 연구원은 텍스트 전용 데이터 세트를 사용하여 지속적인 사전 학습 방식으로 LLM의 컨텍스트 길이를 확장합니다. 5단계에서 연구자들은 긴 비디오 감독을 사용하여 미세 조정하여 지시 따르기 능력을 향상시킵니다. 이 단계에서는 모든 매개변수를 학습할 수 있다는 점에 주목할 가치가 있습니다. 연구원들은 이 글의 풀스택 솔루션을 시스템과 모델링이라는 두 가지 측면에서 평가했습니다. 먼저 훈련 및 추론 결과를 제시하여 장기 컨텍스트 훈련 및 추론을 지원할 수 있는 시스템의 효율성과 확장성을 보여줍니다. 그런 다음 작업에 따른 캡션 및 지침에 대한 긴 컨텍스트 모델의 성능을 평가합니다. 이 연구는 훈련 시스템의 처리량, 추론 시스템의 대기 시간, 지원되는 최대 시퀀스 길이에 대한 정량적 평가를 제공합니다. 표 2는 처리량 결과를 보여줍니다. ZIGZAG-RINGATTN과 비교하여 이 시스템은 2.1배에서 5.7배의 가속을 달성하며 성능은 DeepSpeed-Ulysses와 비슷합니다. Megatron-LM CP의 더욱 최적화된 링 시퀀스 병렬 구현에 비해 3.1x~4.3x의 속도 향상이 달성됩니다.본 연구에서는 메모리 부족 오류가 발생할 때까지 시퀀스 길이를 1k에서 10k까지 점진적으로 늘려 고정된 수의 GPU가 지원하는 최대 시퀀스 길이를 평가합니다. 결과는 그림 9에 요약되어 있습니다. 256 GPU로 확장할 때 우리 방법은 컨텍스트 길이의 약 8배를 지원할 수 있습니다. 또한 제안된 시스템은 ZIGZAG-RINGATTN과 유사한 컨텍스트 길이 스케일링을 달성하여 256 GPU에서 200만 개 이상의 컨텍스트 길이를 지원합니다. Table 3은 지원되는 최대 시퀀스 길이를 비교한 것으로, 본 연구에서 제안하는 방법은 HuggingFace Pipeline에서 지원하는 것보다 2.9배 더 긴 시퀀스를 지원한다. 그림 11은 건초 더미에 바늘을 꽂는 긴 비디오 실험의 결과를 보여줍니다. 이와 대조적으로 LongVILA 모델(오른쪽)은 다양한 프레임 수와 깊이에서 향상된 성능을 보여줍니다. 표 5에는 Video MME 벤치마크에서 다양한 모델의 성능이 나열되어 있으며, 짧은, 중간, 긴 비디오 길이의 효율성과 전반적인 성능을 비교합니다. LongVILA-8B는 256개의 프레임을 사용하며 총점은 50.5입니다. 연구원들은 표 6의 3단계와 4단계의 영향에 대한 절제 연구도 수행했습니다. 표 7은 다양한 프레임 수(8, 128, 256)에서 훈련 및 평가된 LongVILA 모델의 성능 메트릭을 보여줍니다. 프레임 수가 증가하면 모델 성능이 크게 향상됩니다. 특히 평균 점수가 2.00에서 3.26으로 증가하여 더 많은 수의 프레임에서 정확하고 풍부한 자막을 생성하는 모델의 능력이 강조되었습니다. 위 내용은 1024 프레임과 거의 100% 정확도를 지원하는 NVIDIA 'LongVILA”가 긴 비디오 개발 시작의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



