AIxiv 칼럼은 본 사이트에 학술적, 기술적인 내용을 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
단위 테스트는 소프트웨어 개발 프로세스의 핵심 링크이며 주로 사용됩니다. 소프트웨어에서 테스트 가능한 가장 작은 단위, 기능 또는 모듈이 예상대로 작동하는지 확인하십시오. 단위 테스트의 목표는 각각의 독립적인 코드 조각이 해당 기능을 올바르게 수행할 수 있는지 확인하는 것입니다. 이는 소프트웨어 품질과 개발 효율성을 향상시키는 데 매우 중요합니다. 그러나 대형 모델 자체로는 테스트 중인 복잡한 기능(사이클복잡도 10보다 큰)에 대한 높은 커버리지 테스트 샘플 세트를 생성할 수 없습니다. 이러한 문제점을 해결하기 위해 Peking University의 Li Ge 교수 팀은 테스트 케이스 커버리지를 향상시키는 새로운 방법을 제안했습니다. 이 방법은 테스트 중인 복잡한 기능을 의미론에 따라 여러 개의 간단한 조각으로 분해하는 방법입니다. 대규모 모델은 각 단순 조각에 대한 테스트 케이스를 별도로 생성합니다. 단일 테스트 케이스를 생성할 때 대규모 모델은 테스트할 원래 기능의 일부만 분석하면 되므로 분석의 어려움과 이 단편을 포괄하는 단위 테스트 생성의 어려움이 줄어듭니다. 이 프로모션은 전체 테스트 샘플 세트의 코드 적용 범위를 향상시킬 수 있습니다. 관련 논문 "HITS: High-coverage LLM-based Unit Test Generation via Method Slicing"이 최근 ASE 2024(제39회 IEEE/ACM 국제 컨퍼런스에서)에 게재되었습니다. 자동화된 소프트웨어 엔지니어링)이 허용됩니다. 
논문 주소: https://www.arxiv.org/pdf/2408.11324다음 보기 구체적인 내용 북경대학교 팀의 논문 연구 내용: HITS는 프로그램 샤딩을 위해 대형 모델을 사용합니다프로그램 샤딩은 의미론에 따라 프로그램을 여러 문제 해결 단계로 나누는 것을 말합니다. 프로그램은 문제에 대한 해결책을 형식적으로 표현한 것입니다. 문제 해결 방법은 일반적으로 여러 단계로 구성되며, 각 단계는 프로그램의 코드 조각에 해당합니다. 아래 그림과 같이 컬러 블록은 코드 조각과 문제 해결 단계에 해당합니다.
HITS에서는 효율적으로 처리할 수 있는 각 코드 조각에 대한 단위 테스트 코드를 설계하기 위해 대규모 모델이 필요합니다. 위 그림을 예로 들면, 그림과 같은 슬라이스를 얻을 때 HITS에서는 슬라이스 1(녹색), 슬라이스 2(파란색), 슬라이스 3(빨간색)에 대한 테스트 샘플을 각각 생성하기 위해 대형 모델이 필요합니다. 슬라이스 1에 대해 생성된 테스트 샘플은 슬라이스 2 및 슬라이스 3에 관계없이 슬라이스 1을 최대한 많이 포함해야 합니다. 다른 코드 부분에도 동일하게 적용됩니다. HITS는 두 가지 이유로 작동합니다. 첫째, 대규모 모델에서는 적용되는 코드의 양을 줄이는 것을 고려해야 합니다. 위 그림을 예로 들면, 슬라이스 3에 대한 테스트 샘플을 생성할 때 슬라이스 3의 조건 분기만 고려하면 됩니다. 슬라이스 3의 일부 조건부 분기를 처리하려면 이 실행 경로가 슬라이스 1과 슬라이스 2의 적용 범위에 미치는 영향을 고려하지 않고 슬라이스 1과 슬라이스 2에서 실행 경로만 찾으면 됩니다. 둘째, 의미론(문제 해결 단계)을 기반으로 분할된 코드 조각은 대규모 모델이 코드 실행의 중간 상태를 파악하는 데 도움이 됩니다. 이후 코드 블록에 대한 테스트 케이스를 생성하려면 이전 코드로 인해 발생한 프로그램 상태의 변경 사항을 고려해야 합니다. 코드 블록은 실제 문제 해결 단계에 따라 분할되므로 이전 코드 블록의 동작을 자연어로 설명할 수 있습니다(위 그림의 주석 참조). 현재 대부분의 대규모 언어 모델은 자연어와 프로그래밍 언어 간의 혼합 교육의 산물이므로, 좋은 자연어 요약은 대규모 모델이 코드로 인한 프로그램 상태의 변화를 보다 정확하게 파악하는 데 도움이 될 수 있습니다. HITS는 프로그램 샤딩을 위해 대형 모델을 사용합니다. 문제 해결 단계는 프로그래머의 주관적인 색감을 담아 자연어로 표현하는 경우가 많아 자연어 처리 능력이 뛰어난 대형 모델을 바로 활용 가능하다. 특히 HITS는 상황 내 학습을 사용하여 대규모 모델을 호출합니다. 팀은 실제 시나리오에서의 과거 실무 경험을 활용하여 여러 프로그램 샤딩 샘플을 수동으로 작성했습니다. 몇 가지 조정 후에 프로그램 샤딩에 대한 대규모 모델의 효과가 연구팀의 기대에 부합했습니다. 다뤄야 할 코드 조각이 주어지면, 해당 테스트 샘플을 생성하려면 다음 세 단계를 거쳐야 합니다. 1. 조각의 입력을 분석합니다. 2. 대규모 모델에 초기 테스트 샘플을 생성하도록 지시하는 프롬프트를 구성합니다. 대형 모델 자체 디버그 조정 샘플이 올바르게 실행되도록 테스트합니다. 프래그먼트의 입력을 분석합니다. 이는 후속 프롬프트 사용을 위해 프래그먼트에서 허용하는 모든 외부 입력을 추출하는 것을 의미합니다. 외부 입력은 이 조각이 적용되는 이전 조각에서 정의된 지역 변수, 테스트 중인 메서드의 형식 매개 변수, 조각 내에서 호출되는 메서드 및 외부 변수를 나타냅니다. 외부 입력의 값은 다룰 조각의 실행을 직접적으로 결정하므로 이 정보를 추출하여 대형 모델을 프롬프트하는 것은 목표한 방식으로 테스트 사례를 설계하는 데 도움이 됩니다. 연구팀은 실험을 통해 대형 모델이 외부 입력을 추출하는 능력이 뛰어나다는 사실을 발견했으며, 따라서 HITS에서는 이 작업을 완료하기 위해 대형 모델을 사용합니다. 다음으로 HITS는 대규모 모델이 테스트 샘플을 생성하도록 안내하는 일련의 사고 프롬프트를 구축합니다. 추론 단계는 다음과 같습니다. 첫 번째 단계는 외부 입력을 제공하고 다룰 코드 조각의 다양한 조건 분기의 순열과 조합을 분석하는 것입니다. 외부 입력이 충족해야 하는 속성은 무엇입니까? 예를 들어 조합 1, 문자열 a는 다음을 포함해야 합니까? 문자 'x', 정수 변수 i는 조합 2에서 음수가 아니어야 하고, 문자열 a는 비어 있지 않아야 하며, 정수 변수 i는 소수여야 합니다. 두 번째 단계에서는 이전 단계의 각 조합에 대해 실제 매개변수의 특성과 전역 변수의 설정을 포함하되 이에 국한되지 않는 해당 테스트 중인 코드가 실행되는 환경의 특성을 분석합니다. 세 번째 단계는 각 조합에 대한 테스트 샘플을 생성하는 것입니다. 연구팀은 대형 모델이 지시 사항을 정확하게 이해하고 실행할 수 있도록 각 단계마다 예제를 직접 제작했습니다. 마지막으로 HITS를 사용하면 대형 모델에서 생성된 테스트 샘플을 후처리 및 자체 디버그를 통해 올바르게 실행할 수 있습니다. 대형 모델에서 생성된 테스트 샘플은 직접 사용하기 어려운 경우가 많으며, 잘못 작성된 테스트 샘플로 인해 다양한 컴파일 오류 및 런타임 오류가 발생하게 됩니다. 연구팀은 자체 관찰과 기존 논문 요약을 바탕으로 몇 가지 규칙과 일반적인 오류 복구 사례를 설계했습니다. 먼저 규칙에 따라 수정해 보세요. 규칙을 복구할 수 없는 경우에는 대형 모델의 자체 디버그 기능을 사용하여 복구하십시오. 일반적인 오류에 대한 복구 사례는 대형 모델을 참조할 수 있도록 프롬프트에 제공됩니다.
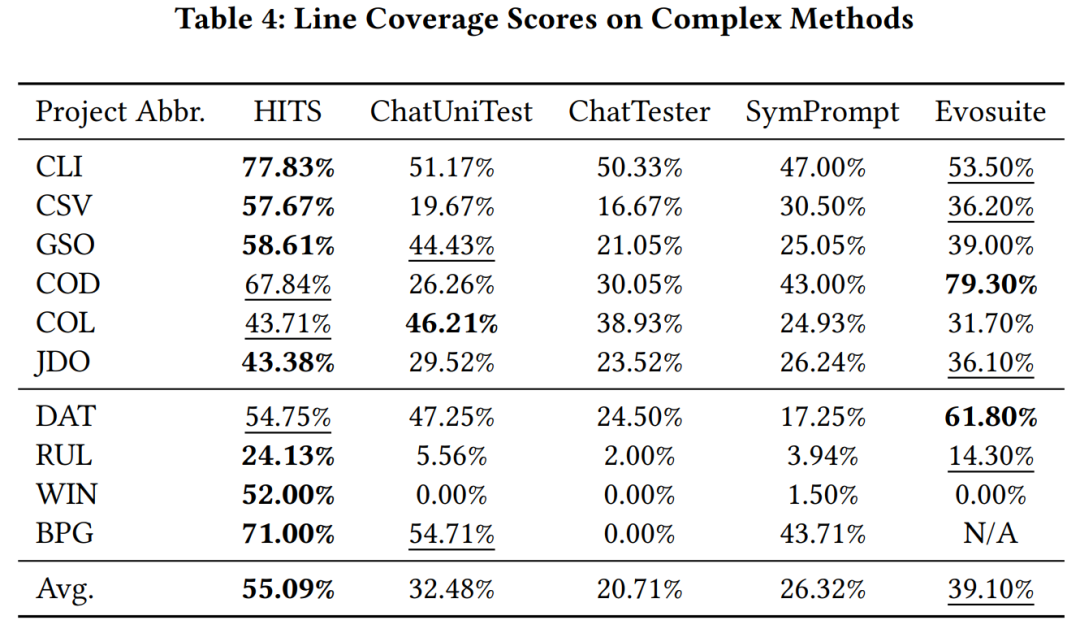
L'illustration globale des Hits Vérification expérimentale L'équipe de recherche utilise gpt-3.5-turbo comme grand modèle appelé par HITS, et compare les HITS sur des fonctions complexes (cyclocomplexité supérieure à 10) dans des projets Java qui ont été appris par de grands modèles et ceux qui n'ont pas été appris. D'autres grandes méthodes de tests unitaires basées sur des modèles et la couverture de code avec evosuite. Les résultats expérimentaux montrent que HITS présente des améliorations de performances significatives par rapport aux méthodes comparées.
Améliorer la couverture du code. Comme le montre l'image.
Dans ce cas, l'échantillon de test généré par la méthode de base n'a pas réussi à couvrir entièrement le fragment de code rouge dans la tranche 2. Cependant, comme HITS s'est concentré sur la tranche 2, il a analysé les variables externes référencées par celle-ci et a capturé la propriété selon laquelle "si vous souhaitez couvrir le fragment de code rouge, la variable 'arguments' doit être non vide", et a construit un test échantillon basé sur cette propriété. Couverture réussie des indicatifs régionaux rouges.
Améliorez la couverture des tests unitaires, améliorez la fiabilité et la stabilité du système et améliorez ainsi la qualité des logiciels. HITS utilise des expériences de fragmentation de programmes pour prouver que cette technologie peut non seulement améliorer considérablement la couverture du code de l'ensemble global d'échantillons de test, mais qu'elle dispose également d'une méthode de mise en œuvre simple et directe, elle devrait aider les équipes à découvrir et à corriger les erreurs de développement à l'avenir. plus tôt dans la pratique de scénarios réels, améliorant ainsi la qualité de la livraison des logiciels.
위 내용은 Peking University Li Ge 팀은 대규모 모델에 대한 단일 테스트를 생성하는 새로운 방법을 제안하여 코드 테스트 범위를 크게 향상시켰습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



