

편집 | ScienceAI
최근 상하이 교통대학, 상하이 AI 연구소, 차이나 모바일 등의 공동 연구팀이 에 "의학을 위한 다목적 대형 언어 모델 평가 및 구축》에서는 데이터, 평가 및 모델의 다양한 관점에서 임상 의학에서 대형 언어 모델의 적용을 종합적으로 분석하고 논의합니다.
이 기사에 포함된 모든 데이터, 코드, 모델은 오픈 소스입니다.
개요
최근 몇 년 동안 대형 언어 모델(LLM)이 의료 분야에서 상당한 발전을 이루었고 일정한 결과를 얻었습니다. 이러한 모델은 MCQA(Medical Multiple Choice Question Answering) 벤치마크에서 효율적인 기능을 입증했으며 UMLS와 같은 전문 시험에서 전문가 수준에 도달하거나 그 이상이었습니다. 그러나 LLM이 실제 임상 시나리오에 적용되려면 아직 멀었습니다. 주요 문제는ICD 코드 해석 오류, 임상 절차 예측, 전자건강기록(EHR) 데이터 구문 분석 오류 등 기본 의학 지식 처리에 있어서 모델의 부적절함에 중점을 두고 있습니다.
이러한 문제는 중요한 점을 지적합니다. 현재 평가 벤치마크는 주로 건강 검진의 객관식 문제에 초점을 맞추고 있으며 실제 임상 시나리오에서 LLM 적용을 적절하게 반영하지 않습니다. 본 연구에서는 객관식 질문뿐만 아니라 임상 보고서 요약, 치료 권장 사항, 진단, 명명된 개체 인식 등 11가지 고급 임상 작업을 다루는 새로운 평가 벤치마크인 MedS-Bench를 제안합니다. . 연구팀은 이번 벤치마크를 통해 여러 주류 의료 모델을 평가한 결과 몇 번의 자극에도 불구하고 GPT-4,클로드 등과 같은 가장 진보된 모델도 이러한 복잡한 임상 작업을 처리하는 데 어려움을 겪습니다.
이 문제를 해결하기 위해 연구팀은 Super-NaturalInstructions에서 영감을 받아 검사, 임상 텍스트, 학술 논문, 58개의 생물 의학 텍스트의 데이터를 통합하는 최초의 종합 의료 교육 미세 조정 데이터 세트 MedS-Ins를 구축했습니다. 122개의 임상 작업을 다루는 1,350만 개 이상의 샘플을 포함하는 의학 지식 기반 및 일상 대화의 데이터 세트입니다. 이를 바탕으로 연구팀은 오픈소스 의료 언어 모델의 지시사항을 조정하고 맥락 내 학습 환경에서 모델 효과를 탐색했습니다. 이번 작업에서 개발된 의료용 대형 언어 모델인 MMedIns-Llama 3는 다양한 임상 작업에서 GPT-4 및 Claude-3.5와 같은 기존의 주요 폐쇄 소스 모델보다 성능이 뛰어납니다. MedS-Ins의 구축은 실제 임상 시나리오에서 의료용 대형 언어 모델의 능력을 크게 향상시켜 그 적용 범위를 온라인 채팅이나 객관식 질문 및 답변의 한계를 훨씬 뛰어넘게 만들었습니다. 저희는 이러한 진전이 의료 언어 모델의 발전을 촉진할 뿐만 아니라 향후 임상 현장에서 인공지능을 적용할 수 있는 새로운 가능성을 제공한다고 믿습니다.테스트 벤치마크 데이터 세트(MedS-Bench)
임상 응용 분야에서 다양한 LLM의 기능을 평가하기 위해 연구팀은 MedS -Bench를 개발했습니다. , 전통적인 객관식 질문을 뛰어 넘는 포괄적인 의료 벤치마크입니다. 아래 그림에서 볼 수 있듯이 MedS-Bench는 39개의 기존 데이터 세트에서 파생되었으며, 11개 범주를 포함하고 총 52개의 작업을 포함합니다. MedS-Bench에서는 데이터가 미세 조정이 가능한 구조로 재구성됩니다. 또한 각 작업에는 수동으로 주석이 달린 작업 정의가 함께 제공됩니다. 관련된 11개 범주는 다음과 같습니다: 객관식 질문 답변(MCQA), 텍스트 요약, 정보 추출(정보 추출), 설명 및 근거, 명명된 엔터티 인식(NER), 진단, 치료 계획, 임상 결과 예측 , 텍스트 분류, 사실 확인 및 자연어 추론(NLI).
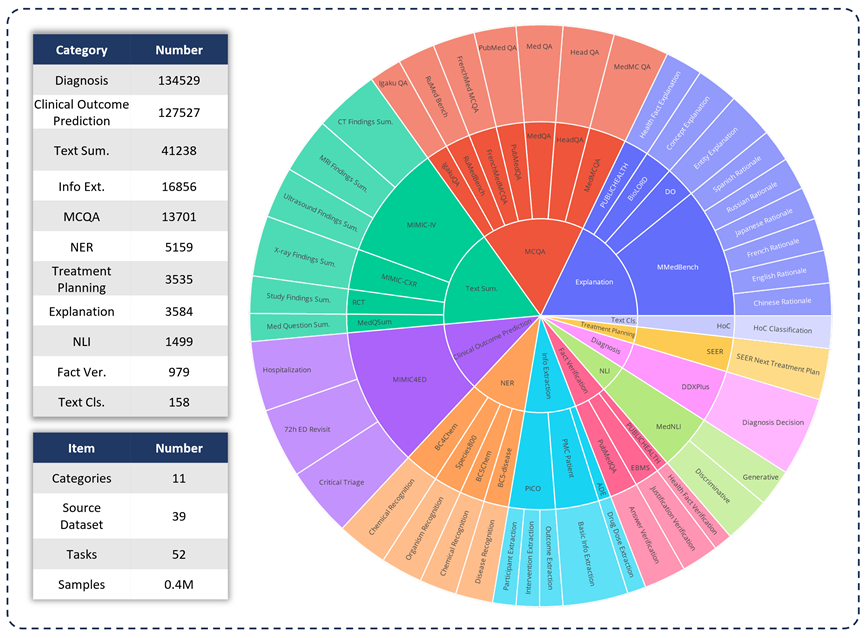
이러한 작업 범주를 정의하는 것 외에도 연구팀은 MedS-Bench 텍스트 길이에 대한 자세한 통계를 수행하고 아래 표와 같이 LLM이 다양한 작업을 처리하는 데 필요한 기능을 구분했습니다. LLM 처리 작업에 필요한 기능은 (i) 모델 내부 지식을 기반으로 한 추론, (ii) 제공된 컨텍스트에서 사실 검색의 두 가지 범주로 나뉩니다.
넓게 말하면 전자는 대규모 사전 학습을 통해 모델 가중치에 인코딩된 지식을 획득해야 하는 작업인 반면, 후자는 요약이나 정보 추출 등 제공된 컨텍스트에서 정보를 추출해야 하는 작업입니다. . 표 1에서 볼 수 있듯이 모델이 모델로부터 지식을 회상해야 하는 작업에는 총 8개 범주가 있으며, 나머지 3개 작업 범주에는 주어진 컨텍스트에서 사실을 검색해야 합니다.
표 1: 사용된 테스트 작업에 대한 자세한 통계입니다.

지시 미세 조정 데이터 세트(MedS-Ins)
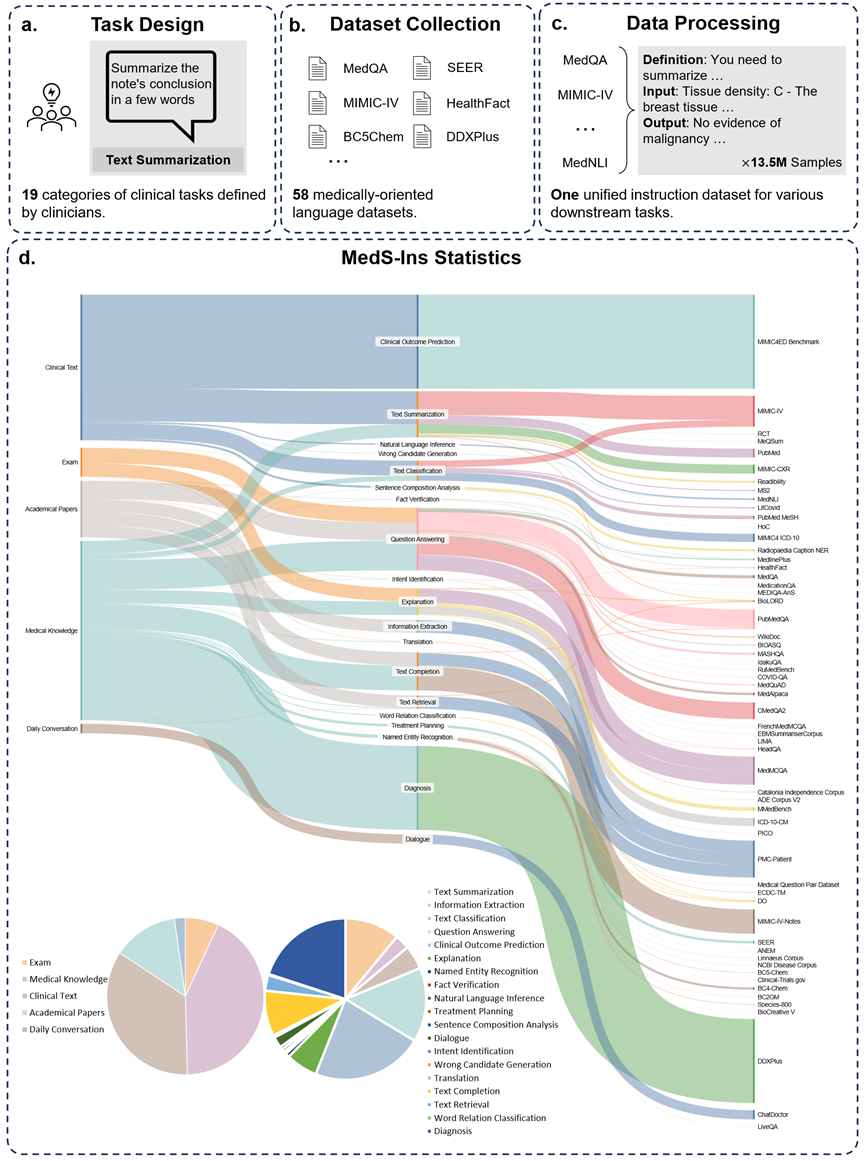
또한 연구팀은 또한 데이터세트 MedS-Ins 미세 조정 지침을 오픈 소스로 제공했습니다. 데이터 세트는 총 122개의 다양한 임상 작업에 대해 5개의 서로 다른 텍스트 소스와 19개의 작업 범주를 포함합니다. 아래 그림은 MedS-In의 구축 과정과 통계정보를 요약한 것입니다.
텍스트 소스
본 논문에서 제안된 지침 미세 조정 데이터 세트는 시험, 임상 텍스트, 학술 논문, 의학 지식 기반, 그리고 일상 대화.
시험: 이 카테고리에는 여러 국가의 건강 검진 문제 데이터가 포함되어 있습니다. 기본적인 의학 지식부터 복잡한 임상 절차까지 광범위한 의학 지식을 다루고 있습니다. 시험 문제는 의학 교육 수준을 이해하고 평가하는 중요한 수단이지만, 시험의 높은 수준의 표준화로 인해 실제 임상 작업에 비해 사례가 지나치게 단순화되는 경우가 많다는 점은 주목할 가치가 있습니다. 데이터 세트의 데이터 중 7%는 시험에서 비롯됩니다.
임상 텍스트: 이 텍스트 범주는 병원 및 임상 센터의 진단, 치료 및 예방 과정을 포함한 일상적인 임상 실습에서 생성됩니다. 이러한 텍스트에는 전자 건강 기록(EHR), 방사선 보고서, 실험실 결과, 후속 조치 지침, 약물 권장 사항 등이 포함됩니다. 이러한 텍스트는 질병 진단 및 환자 관리에 필수적이므로 LLM의 효과적인 임상 적용을 위해서는 정확한 분석과 이해가 중요합니다. 데이터 세트에 있는 데이터의 35%는 임상 텍스트에서 나옵니다.
학술 논문: 이 데이터 카테고리는 의학 연구 논문에서 가져온 것이며 의학 연구 분야의 최신 발견과 발전을 다루고 있습니다. 학술 논문에서 데이터를 추출하는 것은 접근 용이성과 구조화된 구성으로 인해 상대적으로 간단합니다. 이러한 데이터는 모델이 가장 최첨단 의학 연구 정보를 습득하고 현대 의학의 발전을 더 잘 이해할 수 있도록 모델을 안내하는 데 도움이 됩니다. 데이터 세트의 데이터 중 13%는 학술 논문에서 나온 것입니다.
의학지식베이스: 의학백과사전, 지식그래프, 의학용어집 등의 종합적인 의학지식이 잘 정리된 데이터 카테고리입니다. 이러한 데이터는 의학 지식 기반의 핵심을 형성하고 의학 교육과 임상 실습에서의 LLM 적용을 지원합니다. 데이터 세트의 데이터 중 43%는 의학 지식에서 비롯됩니다.
일상 대화: 이 데이터 카테고리는 주로 온라인 플랫폼과 기타 대화형 시나리오를 통해 의사와 환자 사이의 일상 상담을 의미합니다. 이러한 데이터는 의료진과 환자 간의 실제 상호 작용을 반영하며 환자의 요구를 이해하고 전반적인 의료 서비스 경험을 개선하는 데 중요한 역할을 합니다. 데이터 세트의 데이터 중 2%는 일상 대화에서 나옵니다.
작업 유형
연구팀은 텍스트에 포함된 분야를 분류하는 것 외에도 MedS-Ins에서 샘플의 작업 범주를 더욱 세분화했습니다. 19개의 작업 범주가 식별되었으며 각 범주는 의료용 대형 언어 모델이 갖춰야 할 핵심 기능을 나타냅니다. . 데이터 세트를 미세 조정하고 이에 따라 모델을 미세 조정하는 이 명령어를 구축함으로써 대규모 언어 모델은 그림 2에 표시된 것처럼 의료 애플리케이션을 처리하는 데 필요한 기능을 갖습니다.
MedS-Ins의 19개 작업 범주에는 MedS-Bench 벤치마크의 11개 범주가 포함되지만 이에 국한되지는 않습니다. 추가 작업 범주는 의도 인식, 번역, 단어 관계 분류, 텍스트 검색, 문장 구성 요소 분석, 오류 후보 생성, 대화 및 텍스트 완성을 포함하여 의료 분야에 필요한 다양한 언어 및 분석 작업을 포괄하며 MCQA는 일반 Q&A를 확장합니다. 일반적인 Q&A 및 대화부터 다양한 다운스트림 임상 작업에 이르기까지 다양한 작업 범주를 통해 의료 응용 분야에 대한 포괄적인 이해를 보장합니다.
정량적 비교
연구팀은 기존 주류 모델 6개(MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4 및 Claude-3.5) 성능을 광범위하게 테스트했습니다. 각 작업 유형별로 기존의 다양한 LLM의 성능을 먼저 논의한 후 제안된 최종 모델인 MMedIns-Llama 3과 비교합니다. 이 기사에서는 모든 결과가 3샷 프롬프트를 사용하여 얻어졌습니다. MCQA 작업에서는 이전 연구와 일관성을 유지하기 위해 제로샷 프롬프트가 사용된다는 점을 제외하면. GPT-4, Claude 3.5 등의 비공개 소스 모델은 비용이 발생하고 비용에 따른 제한이 있으므로 실험에서는 각 작업별로 50~100개의 테스트 케이스만 샘플링했습니다. 종합적인 테스트 정량화 결과는 표 2-8에 나와 있습니다.
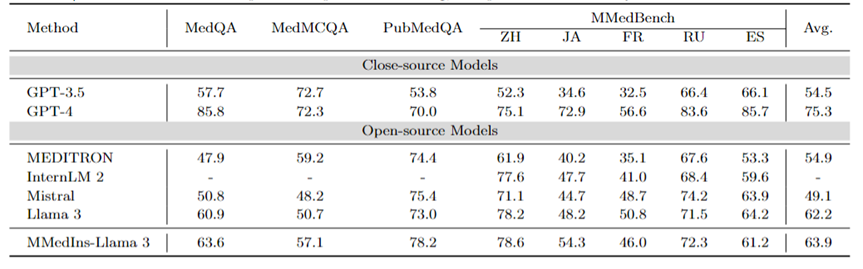
다국어 MCQA: 표 2는 널리 사용되는 MCQA 벤치마크의 '정확성' 평가 결과를 보여준다. 이러한 객관식 질문 답변 데이터 세트에서 기존의 대규모 언어 모델은 매우 높은 정확도를 보여주었습니다. 예를 들어 MedQA에서 GPT-4는 인간 전문가와 거의 비슷한 85.8점에 도달할 수 있는 반면 Llama 3도 시험을 통과할 수 있습니다. 점수는 60.9입니다. 마찬가지로 영어 이외의 언어에서도 LLM은 MMedBench의 다중 선택 정확도에서 탁월한 결과를 보여줍니다.
결과에 따르면 기존 연구에서는 객관식 문제가 널리 고려되었으므로 다양한 LLM이 이러한 작업에 특별히 최적화되어 더 높은 성과를 거두었을 수 있습니다. 따라서 LLM을 임상 적용으로 더욱 촉진하기 위해서는 보다 포괄적인 벤치마크를 확립할 필요가 있습니다.
표 2: 객관식 문제의 정량적 결과 각 지표는 선택 정확도 ACC로 측정됩니다.
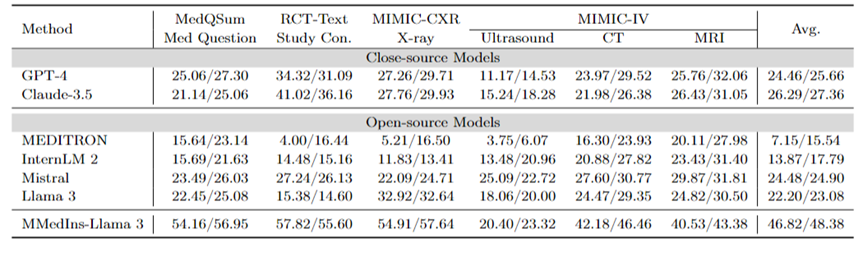
텍스트 요약: 표 3은 "BLEU/ROUGE" 점수 형식으로 텍스트 요약 작업에 대한 다양한 언어 모델의 성능을 보고합니다. 테스트에는 엑스레이, CT, MRI, 초음파 및 기타 의료 문제를 포함한 다양한 보고서 유형이 포함됩니다. 실험 결과에 따르면 GPT-4 및 Claude-3.5와 같은 폐쇄 소스 대규모 언어 모델이 모든 오픈 소스 대규모 언어 모델보다 성능이 뛰어난 것으로 나타났습니다.
오픈 소스 모델 중에서는 Mistral이 BLEU/ROGE가 각각 24.48/24.90으로 가장 좋은 결과를 얻었고, Llama 3가 22.20/23.08로 그 뒤를 이었습니다.
본 글에서 제안하는 MMedIns-Llama 3는 특정 의료 교육 데이터 세트(MedS-Ins)를 기반으로 학습되었으며, 고급 비공개 소스 모델인 GPT-4 및 Claude- 3.5, 평균 점수 46.82/48.38.
표 3: 텍스트 요약 작업의 정량적 결과.
정보 추출: 표 4는 "정확도"를 갖는 다양한 모델의 정보 추출 성능을 보여줍니다. InternLM 2는 평균 81.58점으로 이 작업에서 우수한 성능을 보였으며 GPT-4 및 Claude-3.5와 같은 폐쇄 소스 모델은 각각 평균 점수 77.49 및 78.86으로 다른 모든 오픈 소스 모델보다 뛰어났습니다.
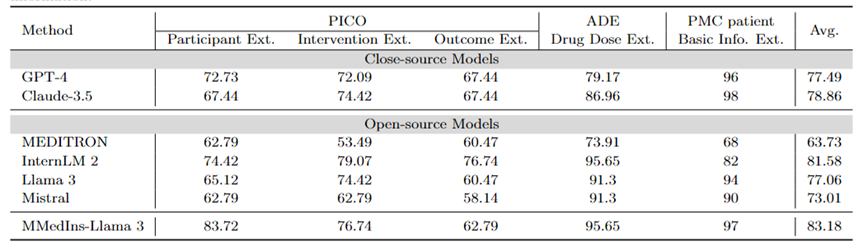
개별 작업 결과를 분석한 결과, 대부분의 대규모 언어 모델은 전문 의료 데이터에 비해 기본 환자 정보 등 덜 복잡한 의료 정보를 추출하는 데 더 나은 성능을 보이는 것으로 나타났습니다. 예를 들어, PMC 환자로부터 기본 정보를 추출하는 경우 대부분의 대규모 언어 모델이 90점 이상의 점수를 얻었으며 Claude-3.5는 98.02점의 최고 점수를 획득했습니다. 이에 반해 PICO의 임상 결과 추출 작업 수행은 상대적으로 열악했습니다. 본 논문에서 제안한 모델인 MMedIns-Llama 3는 평균 점수 83.18점으로 InternLM 2 모델보다 1.6점 더 높은 종합 성능을 보였다.
표 4: 정보 추출 작업에 대한 정량적 결과 각 지표는 정확도(ACC)로 측정됩니다. "Ext."는 추출을 의미하고 "Info."는 정보를 의미합니다.
의학적 개념 설명: 표 5는 "BLEU/ROUGE" 점수, GPT-4 형태로 다양한 모델의 의학적 개념 설명 능력을 보여준다. , Llama 3 및 Mistral이 이 작업을 잘 수행합니다.
相反,Claude-3.5、InternLM 2 和 MEDITRON 的得分相對較低。 MEDITRON 的表現相對較差可能是由於其訓練語料更側重於學術論文和指南,因此在醫學概念解釋方面能力有所欠缺。
最終模型 MMedIns-Llama 3 在所有概念解釋任務中的表現都明顯優於其他模型。
表 5:醫學概念解釋上的量化結果,各項指標以 BLEU-1/ROUGE-1 進行衡量;「Exp.」表示 Explanation。
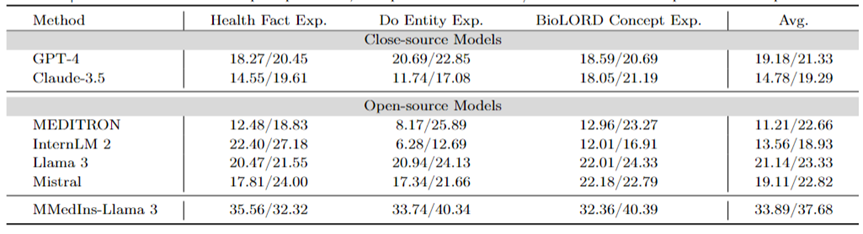
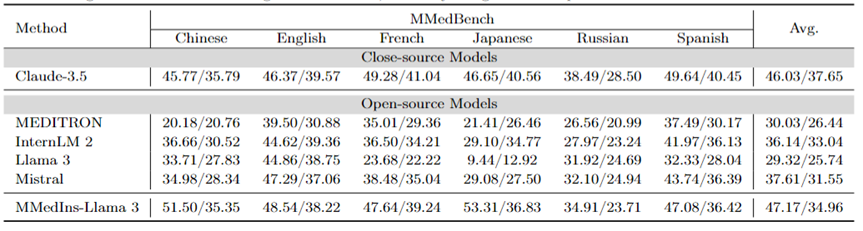
歸因分析(Rationale):表6 以「BLEU/ROUGE 」分數的形式評估了各個模型在歸因分析任務上的性能,使用MMedBench 資料集對六種語言的各種模型的推理能力進行了比較。
在測試的模型中,閉源模型 Claude-3.5 表現出最強的性能,平均得分為 46.03/37.65。這種優異的表現可能是因為該任務與產生 COT 相似,而後者在許多通用 LLM 中均得到了特別增強。
在開源模型中,Mistral 和 InternLM 2 表現出了相當的性能,平均得分分別為 37.61/31.55 和 30.03/26.44。值得注意的是,GPT-4 被排除在本次評估之外,因為 MMedBench 資料集的歸因分析部分主要使用 GPT-4 來產生構建,這可能會引入測試偏差,從而導致不公平的比較。
與概念解釋任務上的表現一致,最終模型 MMedIns-Llama 3 也展現了最佳的整體性能,所有語言上的平均得分為 47.17/34.96。這種優異的表現可能是因為選用的基礎語言模型(MMed-Llama 3)最初是為多語言開發的。因此,即使指令調整沒有明確針對多語言數據,最終模型在多種語言中的表現仍然優於其他模型。
表 6:歸因分析(Rationale)上的量化結果,各項指標以 BLEU-1/ROUGE-1 進行衡量。此處沒有 GPT-4 是因為原始資料是基於 GPT-4 產生結果構造,有公平性偏倚,故未比較 GPT-4。
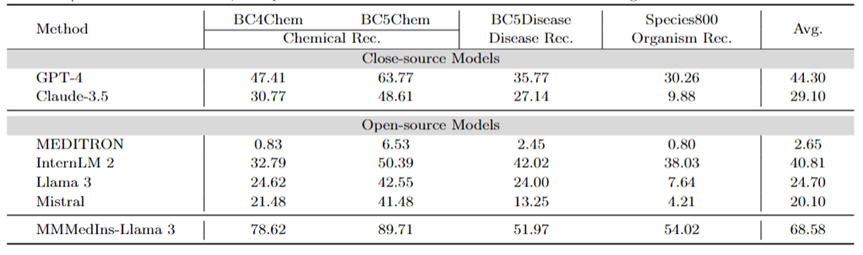
醫學實體抽取(NER):表7 以「F1」分數的形式測試了現有的6 個模型在NER 任務上的表現。 GPT-4 是唯一一個在命名實體辨識 (NER) 各項任務中均表現優異的模型,平均 F1 分數為 44.30 。
它在 BC5Chem 化學實體辨識任務中表現尤為出色,得分為 63.77。 InternLM 2 則緊隨其後,平均 F1 分數為 40.81,在 BC5Chem 和 BC5Disease 任務中均表現出色。 Llama 3 和 Mistral 的平均 F1 分數則分別為 24.70 和 20.10,表現為中等。 MEDITRON 未針對 NER 任務進行最佳化,在此領域的效果差強人意。 MMedIns-Llama 3 的表現則明顯優於所有其他模型,平均 F1 分數為68.58。
表7:NER 任務上的量化結果,各項指標以F1-score衡量;「Rec.」代表「recognition」
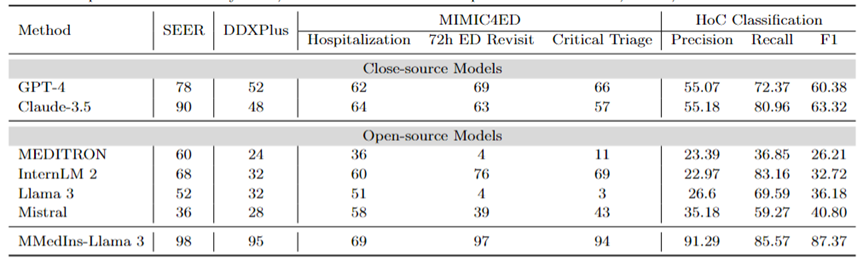
診斷、治療推薦、和臨床結果預測:表8 使用DDXPlus 數據集作為診斷基準、SEER 數據集作為治療推薦基準和MIMIC4ED 數據作為臨床結果預測任務基準來評估診斷、治療推薦和臨床結果預測三大任務的模型表現,結果以準確度來衡量,如表8 所示。
在此,使用可以使用準確度指標來評估產生預測是因為這些資料集每一個都將原始問題簡化為一個閉集上的選擇問題。具體而言,DDXPlus 使用預先定義的疾病列表,模型必須根據提供的患者背景從中選擇疾病。在 SEER 中,治療建議則被分為了八個高級類別,而在 MIMIC4ED 中,最終的臨床結果決策是始終是二值的(True or False)。
整體而言,開源 LLM 在這些任務中的表現不如閉源 LLM,在某些情況下,它們無法提供有意義的預測。例如,Llama 3 在預測 Critical Triage 方面表現不佳。對於 DDXPlus 診斷任務而言,InternLM 2 和 Llama 3 的表現略好一些,準確度為 32。然而,GPT-4 和 Claude-3.5 等閉源模型表現出明顯更好的性能。例如,Claude-3.5在SEER上準確度可以達到為90,而GPT-4則在 DDXPlus 的診斷方面的準確度上更高,得分為 52,突顯出了開源和閉源 LLM 之間的巨大差距。
儘管取得了這些成果,但這些分數仍然不足以可靠地用於臨床。相較之下, MMedIns-Llama 3 在臨床決策支援任務中則表現出了更卓越的準確性,例如SEER 上為98,DDXPlus 上為95,臨床結果預測任務上平均準確度為86.67(Hospitalization, 72h ED Revisit, and Critical Triage 得分的平均值)。
文字分類:表8 也展示了對 HoC 多標籤分類任務的評估,並報告了Macro-precision、Macro-recall 和Macro-F1 Scores 。對於這類任務,所有候選標籤都以清單的形式輸入到語言模型中,並要求模型選擇其對應的答案,並允許進行多項選擇。然後根據模型最終的選擇輸出計算準確度指標。
GPT-4 和 Claude-3.5 在此任務上表現良好,GPT-4 的 Macro-F1 分數為 60.38,Claude-3.5 則更為優異,取得了63.32。這兩個模型都表現出很強的回想能力,尤其是 Claude-3.5,其 Macro-Recall 為 80.96。 Mistral 表現中等,Macro-F1 分數為 40.8,在精確度和召回率之間保持平衡。
相較之下,Llama 3 和 InternLM 2 的整體表現較差,Macro-F1 得分分別為36.18 和 32.72。這些模型(尤其是 InternLM 2)表現出較高的召回率,但準確率卻很差,導致 Macro-F1 得分較低。
MEDITRON 在此任務中排名最低,Macro-F1 得分為 26.21。 MMedIns-Llama 3 明顯優於所有其他模型,在所有指標中均獲得最高分,Macro-precision 為 91.29,Macro-recall 為 85.57,Macro-F1 得分為 87.37。這些結果凸顯了 MMedIns-Llama 3 準確分類文本的能力,使其成為處理這類複雜任務最有效的模型。
表 8:治療規劃(SEER)、診斷(DDXPlus)、臨床結果預測(MIMIC4ED)和文本分類(HoC Classification)四類任務上的結果。前 3 項任務的結果以準確率(Accuracy)為依據,文字分類結果以精確度(Precision)、回想率(Recall)和 F1 分數為依據。
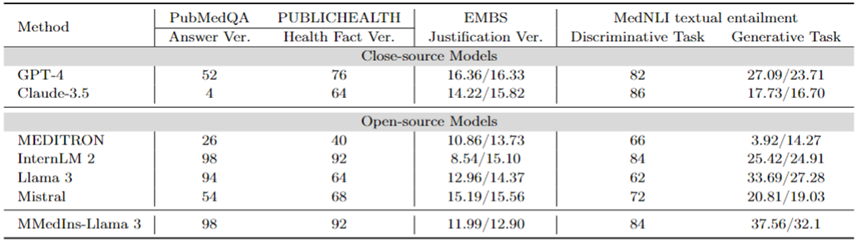
事實修正:表 9 展示了在事實驗證任務上模型評估結果。對於 PubMedQA 答案驗證和 HealthFact 驗證,LLM 需要從提供的候選清單中選擇一個答案,因此以準確度作為評估指標。
相對的,由於 EBMS 理由驗證,任務涉及生成自由格式的文本,使用 BLEU-1 和 ROUGE-1 分數來評估性能。 InternLM 2 在 PubMedQA 答案驗證和 HealthFact 驗證中獲得了最高的準確度,得分分別為 98 和 92。
在 EBMS 基準測試中,GPT-4 表現出最強的效能,BLEU-1/ROUGE-1 得分分別為16.36/16.33。 Claude-3.5 緊隨其後,得分為14.22/15.82,但它在PubMedQA答案驗證中表現不佳。
Llama 3 在 PubMedQA 和 HealthFact Verification 上的準確率分別為 94 和 64,BLEU-1/ROUGE-1 得分為12.96/14.37。 MMedIns-Llama 3 繼續超越現有模型,與InternLM 2 一樣在PubMedQA答案驗證任務上取得了最高的準確度得分,而在EMBS 中,MMedIns-Llama 3 在BLEU-1和ROUGE-1 中以11.99/12.90的成績略落後GPT-4。
醫學文本蘊含(NLI):表 9 也展示了以 MedNLI 為主的,在醫學文本蘊含(NLI)上的評估結果。測驗方式有兩種,一種是判別任務(從候選清單中選出正確答案),以準確度衡量,另一種是產生任務(產生自由格式文字答案),以BLEU/ROUGE 指標來衡量。
InternLM 2 在開源 LLM 中得分最高,得分為 84。對於閉源 LLM,GPT-4 和 Claude-3.5 都顯示出相對較高的分數,準確度分別為 82 和 86。在生成任務中,Llama 3 與真實值的一致性最高,BLEU 和 ROUGE 得分為 33.69/27.28。 Mistral 和 Llama 3 則表現出中等程度。 GPT-4 緊隨其後,得分為 27.09/23.71,而 Claude-3.5 在生成任務中表現並不理想。
MMedIns-Llama 3 在判別任務中準確率最高,得分為 84,但略落後於 Claude-3.5。 MMedIns-Llama 3 在生成任務中也表現出色,BLEU/ROUGE 得分為 37.56/32.17,明顯優於其他模式。
表 9:事實驗證和文本蘊含兩類任務上的量化結果,結果以準確度(ACC)和BLEU/ROUGE來衡量;表中「Ver.」是「verification」的簡寫。
總的而言,研究團隊在各種任務維度上,評測了六大主流模型,研究結果顯示目前的主流LLMs 處理臨床任務時仍舊相當脆弱,會在多樣化的複雜臨床場景下產生嚴重的性能不足。
同時,實驗結果也展現出,透過在指令資料集中加入更多臨床任務文本,強化 LLM 與臨床實際適用的匹配程度,可以大大的加強 LLM 表現。
資料收集方法與訓練流程
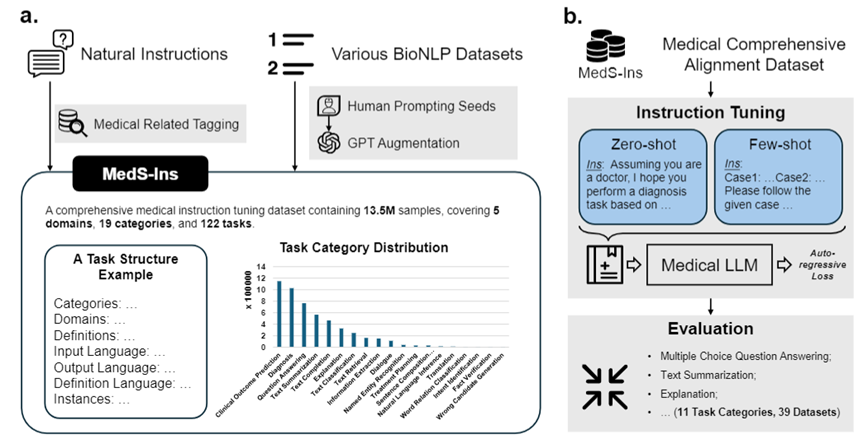
本節將詳細介紹訓練過程,如圖 3b 所示。具體方法與先前的工作 MMedLM 和 PMC-LLaMA 相同,均透過在醫學相關的語料庫上進行進一步的自回歸訓練可以為模型注入相應的醫學知識,從而使它們在不同的下游任務中表現得更好。
具體而言,研究團隊從多語言 LLM 基座模型(MMed-Llama 3)開始,利用來自 MedS-Ins 的指令微調資料對其進行進一步訓練。
指令微調的資料主要涉及兩個面向:
醫學過濾後的自然指令資料:首先從自然領域最大規模的指令資料集Super-NaturalInstructions中篩選出與醫療相關的任務。由於Super-NaturalInstructions更側重於通用領域的不同自然語言處理任務,因此對醫療領域的分類粒度相對較粗。
首先提取了 “醫療保健 ”和 “醫學 ”類別中的所有指令,然後在任務類別不變的情況下,手動為它們添加了更詳細的領域標籤。此外,許多通用領域的組織指令微調資料集也涵蓋了一些醫療相關數據,例如LIMA和ShareGPT。
為了過濾出這些資料中的醫療部分,研究團隊使用了InsTag對每條指令的領域進行粗粒度分類。具體來說,InsTag是一種 LLM,專門用於標記不同的指令樣本。給定一個指令查詢,它將分析該指令屬於哪個領域和任務,在此基礎上篩選出標記為醫療保健、醫療或生物醫學的樣本。
最後,透過過濾一般領域的指令資料集,收集到 37 個任務,共 75373 個樣本。
提示建構現有的 BioNLP 資料集:在現有資料集中有許多關於臨床場景中文字分析的優秀資料集。然而,由於大多數資料集的收集目的不同,它們不能直接用於訓練大型語言模型。然而,可以透過將這些現有的醫學 NLP 任務轉換成可用於訓練生成模型的格式,從而將它們加入指令調整。
具體來說,研究團隊以 MIMIC-IV-Note 為例。 MIMIC-IV-Note 提供了高品質的結構化報告,其中既有發現也有結論,發現到結論的生成被視為經典的臨床文本總結任務。首先手動編寫提示來定義任務,例如:「鑑於超音波成像診斷的詳細結果,用幾個詞概括發現。」考慮到指令調整的多樣性需求,研究團隊要求5個人獨立地用3種不同的提示描述某項任務。
這樣,每個任務就有了 15 個自由文字提示,保證了語意相似,但措辭和格式盡可能多樣化。然後,受 Self-Instruct 的啟發,將這些人工編寫的指令作為種子指令,並要求 GPT-4 根據其進行改寫,從而獲得更多的多樣化指令。
透過上述過程,將額外的85 個任務提示為統一的自由問答格式,再結合過濾後的數據,得到了總計1350 萬個高質量樣本,涵蓋122 個任務,稱為MedS- Ins,並透過指令微調,訓練了一個全新的8B 尺寸的醫學LLM,結果顯示該方法顯著提高了臨床任務的效能。
在指令微調中,研究團隊重點考慮了兩種指令形式:
零樣本提示:在這裡,任務的指令包含一些語義任務描述作為提示,因此要求模型根據其內部模型知識直接回答問題。在收集到的 MedS-Ins 中,每個任務的 “定義 ”內容都可以自然地用作零點指令輸入。由於涵蓋了各種不同的醫療任務定義,該模型有望學習對各種任務描述的語義理解。
少樣本提示:在這裡,指令包含了少量的範例,這些範例允許模型從上下文中學習到任務的大致需求。只需從相同任務的訓練集中隨機抽取其他案例,並使用以下簡單模板對其進行組織,即可獲得此類指令:
Case1: Input: {CASE1_INPUT}, Output: {CASE1_OUTPUT} ... CaseN: Input: {CASEN_INPUT}, Output: {CASEN_OUTPUT} {INSTRUCTION} see what content you have to output. Input: {INPUT}
討論
整體而言,本文做出了幾項重要貢獻:
綜合評估基準--MedS-Bench
醫學LLM 的開發在很大程度上依賴於多選題答案(MCQA)的基準測試。然而,這種狹隘的評估框架回忽略 LLM 在各種複雜臨床場景下中真實的能力表現。
因此,在這項工作中,研究團隊引入了MedS-Bench,這是一個綜合基準,旨在評估閉源和開源LLM 在各種臨床任務中的性能,包括那些需要從模型預訓練語料中回憶事實或從給定上下文中進行推理的任務。
研究結果表明,雖然現有的 LLM 在 MCQA 基準測試中表現優異,但它們很難與臨床實踐保持一致,尤其是在治療推薦和解釋等任務中。這項發現凸顯了進一步開發適配於更廣泛臨床和醫學場景的醫學大語言模型的必要性。
綜合指令調整資料集--MedS-Ins
研究團隊從現有的BioNLP 資料集中廣泛取得數據,並將這些樣本轉換為統一格式,同時採用半自動化的提示策略,建構開發了MedS-Ins--一種新型的醫療指令調整資料集。以往的指令微調資料集的工作主要集中在從日常對話、考試或學術論文中建立問答對,往往忽略了從實際臨床實踐中產生的文本。
相較之下,MedS-Ins 整合了更廣泛的醫學文本資源,包括 5 個主要文本領域和 19 個任務類別。這種對資料組成的系統性分析有利於使用者理解 LLM 的臨床應用邊界。
醫學大語言模型--MMedIns-Llama 3
在模型方面,研究團隊證明了透過在MedS-Ins上進行指令微調訓練,可以顯著提高開源醫學LLM與臨床需求的一致性。
需要強調的是,最終模型MMedIns-Llama 3更多是一個「概念驗證」模型,它採用了8B的中等參數規模,最終的模型對各種臨床任務展現出了深刻的理解,並能透過零次或少量的指令提示靈活適應多種醫療場景,而無需進一步的特定任務訓練。
結果表明,MMedIns-Llama 3在特定臨床任務類型上優於現有的LLM、 包括 GPT-4、Claude-3.5等。
現有的限制
在此,研究團隊也要強調了本文的限制以及未來可能的改進。
首先,MedS-Bench 目前只涵蓋了 11 項臨床任務、 這並不能完全涵蓋所有臨床場景的複雜性。此外,雖然評估了六種主流 LLM,但分析中仍缺少部分最新的 LLM。為了解決這些局限性,研究團隊計劃在發表本文的同時發布一個醫學 LLM 的 Leaderboard,旨在鼓勵更多的研究人員一同不斷擴展和完善醫學 LLM 的綜合評估基準。透過在評估過程中納入更多來自不同文本源的任務類別,希望能更深入了解醫學領域中 LLMs 的開發及使用邊界。
其次,儘管現在 MedS-Ins 包含了廣泛的醫療任務,但它仍然不完整,還是缺少某些實用的醫療場景。為了解決這個問題,研究團隊在 GitHub 上開源了所有收集到的數據和資源。由衷希望更多的臨床醫生或研究學者可以一同維護擴張這個指令調整資料集,類似於通用領域中的 Super-NaturalInstructions。研究團隊在 GitHub 頁面上提供了詳細的上傳指南,同時將在論文的迭代更新中書面感謝每位參與資料集更新的貢獻者。
第三,研究團隊計劃在 MedS-Bench 和 MedS-Ins 中加入更多語言,以支持開發更強大的多語言醫學 LLM。目前,儘管在 MedS-Bench 和 MedS-Ins 中包含了一些多語言任務,但這些資源主要以英語為中心。將其擴展到更廣泛的語言範圍將是一個很有前景的未來方向,以便確保醫療人工智慧的最新進展能夠公平地惠及更廣泛、更多樣化的地區。
最後,研究團隊已將所有程式碼、資料和評估流程進行開源。希望這項工作能引導醫學 LLM 的發展更多的關注到如何將這些強大的語言模型與現實世界的臨床應用結合。
위 내용은 '만능' 의료 모델을 지향하는 Shanghai Jiao Tong University 팀은 대규모 명령 미세 조정 데이터, 오픈 소스 모델 및 포괄적인 벤치마크 테스트를 공개합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



