
애플리케이션의 컴퓨팅 딜레마
개발과 프레임워크 중 어느 것이 더 우선시되어야 할까요?
Java는 애플리케이션 개발에서 가장 일반적으로 사용되는 프로그래밍 언어입니다. 하지만 Java에서 데이터를 처리하는 코드를 작성하는 것은 간단하지 않습니다. 예를 들어, 다음은 두 필드에 대해 그룹화 및 집계를 수행하는 Java 코드입니다.
Map<Integer, Map<String, Double>> summary = new HashMap<>();
for (Order order : orders) {
int year = order.orderDate.getYear();
String sellerId = order.sellerId;
double amount = order.amount;
Map<String, Double> salesMap = summary.get(year);
if (salesMap == null) {
salesMap = new HashMap<>();
summary.put(year, salesMap);
}
Double totalAmount = salesMap.get(sellerId);
if (totalAmount == null) {
totalAmount = 0.0;
}
salesMap.put(sellerId, totalAmount + amount);
}
for (Map.Entry<Integer, Map<String, Double>> entry : summary.entrySet()) {
int year = entry.getKey();
Map<String, Double> salesMap = entry.getValue();
System.out.println("Year: " + year);
for (Map.Entry<String, Double> salesEntry : salesMap.entrySet()) {
String sellerId = salesEntry.getKey();
double totalAmount = salesEntry.getValue();
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
}
}
반대로 SQL은 훨씬 간단합니다. GROUP BY 절 하나로 계산을 종료할 수 있습니다.
SELECT 연도(주문 날짜),판매자 ID,합계(금액) FROM 주문 GROUP BY 연도(주문 날짜),판매자 ID
실제로 초기 애플리케이션은 Java와 SQL의 공동 작업으로 작동했습니다. 비즈니스 프로세스는 애플리케이션 측에서 Java로 구현되었으며, 데이터는 백엔드 데이터베이스에서 SQL로 처리되었습니다. 데이터베이스 제한으로 인해 프레임워크를 확장하고 마이그레이션하기가 어려웠습니다. 이는 현대 응용 프로그램에 매우 비우호적이었습니다. 더욱이, 데이터베이스가 없거나 데이터베이스 간 계산이 관련되어 있으면 SQL을 사용할 수 없는 경우가 많았습니다.
이를 고려하여 나중에 많은 애플리케이션이 완전한 Java 기반 프레임워크를 채택하기 시작했습니다. 여기서 데이터베이스는 간단한 읽기 및 쓰기 작업만 수행하고 비즈니스 프로세스와 데이터 처리는 특히 마이크로서비스가 등장할 때 애플리케이션 측에서 Java로 구현됩니다. 이렇게 하면 애플리케이션이 데이터베이스에서 분리되고 뛰어난 확장성과 마이그레이션성을 얻을 수 있으므로 앞서 언급한 Java 개발 복잡성에 직면하면서 프레임워크 이점을 얻는 데 도움이 됩니다.
우리는 개발이나 프레임워크라는 한 가지 측면에만 집중할 수 있는 것 같습니다. Java 프레임워크의 이점을 누리려면 개발의 어려움을 견뎌야 합니다. 그리고 SQL을 사용하려면 프레임워크의 단점을 허용해야 합니다. 딜레마가 생깁니다.
그럼 어떻게 하면 될까요?
Java의 데이터 처리 기능을 향상시키는 것은 어떻습니까? 이는 SQL 문제를 방지할 뿐만 아니라 Java 단점도 극복합니다.
실제로 Java Stream/Kotlin/Scala가 모두 그렇게 하려고 노력하고 있습니다.
스트림
Java 8에 도입된 Stream에는 다양한 데이터 처리 방법이 추가되었습니다. 위 계산을 구현하기 위한 스트림 코드는 다음과 같습니다.
Map<Integer, Map<String, Double>> summary = orders.stream()
.collect(Collectors.groupingBy(
order -> order.orderDate.getYear(),
Collectors.groupingBy(
order -> order.sellerId,
Collectors.summingDouble(order -> order.amount)
)
));
summary.forEach((year, salesMap) -> {
System.out.println("Year: " + year);
salesMap.forEach((sellerId, totalAmount) -> {
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
});
});
Stream은 실제로 코드를 어느 정도 단순화합니다. 그러나 전반적으로 여전히 SQL에 비해 번거롭고 덜 간결합니다.
코틀린
더 강력하다고 주장했던 Kotlin이 더욱 발전했습니다.
val summary = orders
.groupBy { it.orderDate.year }
.mapValues { yearGroup ->
yearGroup.value
.groupBy { it.sellerId }
.mapValues { sellerGroup ->
sellerGroup.value.sumOf { it.amount }
}
}
summary.forEach { (year, salesMap) ->
println("Year: $year")
salesMap.forEach { (sellerId, totalAmount) ->
println(" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Kotlin 코드는 더 간단하지만 개선이 제한적입니다. SQL과 비교하면 아직 격차가 큽니다.
스칼라
그리고 스칼라가 있었습니다:
val summary = orders
.groupBy(order => order.orderDate.getYear)
.mapValues(yearGroup =>
yearGroup
.groupBy(_.sellerId)
.mapValues(sellerGroup => sellerGroup.map(_.amount).sum)
)
summary.foreach { case (year, salesMap) =>
println(s"Year: $year")
salesMap.foreach { case (sellerId, totalAmount) =>
println(s" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Scala는 Kotlin보다 조금 더 간단하지만 여전히 SQL과 비교할 수는 없습니다. 게다가 스칼라는 너무 무거워서 사용하기 불편해요.
사실 이러한 기술은 완벽하지는 않지만 올바른 방향으로 가고 있습니다.
컴파일된 언어는 핫스왑이 불가능합니다
또한 컴파일된 언어인 Java에는 핫 스와핑에 대한 지원이 부족합니다. 코드를 수정하려면 재컴파일 및 재배포가 필요하며, 종종 서비스를 다시 시작해야 합니다. 이로 인해 요구 사항이 자주 변경될 때 최적이 아닌 경험이 발생합니다. 이에 비해 SQL은 이 점에 있어서 아무런 문제가 없습니다.

Java 개발은 복잡하고 프레임워크에도 단점이 있습니다. SQL은 프레임워크 요구 사항을 충족하는 데 어려움이 있습니다. 딜레마는 해결하기 어렵습니다. 다른 방법은 없나요?
궁극의 솔루션 – esProc SPL
esProc SPL은 순수하게 Java로 개발된 데이터 처리 언어입니다. 개발이 간단하고 프레임워크가 유연합니다.
간결한 구문
위의 그룹화 및 집계 작업에 대한 Java 구현을 검토해 보겠습니다.

Java 코드와 비교하면 SPL 코드가 훨씬 더 간결합니다.
Orders.groups(year(orderdate),sellerid;sum(amount))
SQL 구현만큼 간단합니다.
SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid
사실 SPL 코드는 SQL 코드보다 단순한 경우가 많습니다. 순서 기반 및 절차적 계산을 지원하는 SPL은 복잡한 계산을 더 잘 수행합니다. 다음 예를 생각해 보세요. 주식의 연속 상승 일수의 최대 수를 계산합니다. SQL에는 쓰기는커녕 이해하기도 어려운 다음과 같은 3계층 중첩문이 필요합니다.
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
SPL은 단 한 줄의 코드로 계산을 구현합니다. 이는 Java 코드는 말할 것도 없고 SQL 코드보다 훨씬 간단합니다.
stock.sort(tradeDate).group@i(price<price[-1]).max(~.len())
Comprehensive, independent computing capability
SPL has table sequence – the specialized structured data object, and offers a rich computing class library based on table sequences to handle a variety of computations, including the commonly seen filtering, grouping, sorting, distinct and join, as shown below:
Orders.sort(Amount) // Sorting Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // Filtering Orders.groups(Client; sum(Amount)) // Grouping Orders.id(Client) // Distinct join(Orders:o,SellerId ; Employees:e,EId) // Join ……
More importantly, the SPL computing capability is independent of databases; it can function even without a database, which is unlike the ORM technology that requires translation into SQL for execution.
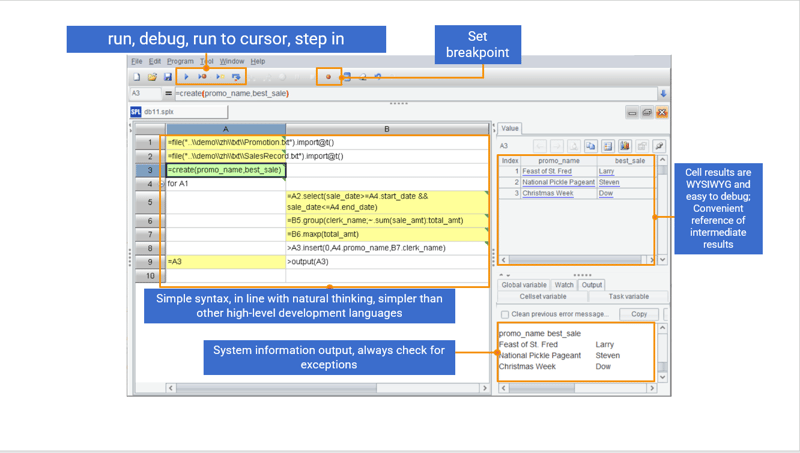
Efficient and easy to use IDE
Besides concise syntax, SPL also has a comprehensive development environment offering debugging functionalities, such as “Step over” and “Set breakpoint”, and very debugging-friendly WYSIWYG result viewing panel that lets users check result for each step in real time.
Support for large-scale data computing
SPL supports processing large-scale data that can or cannot fit into the memory.
In-memory computation:

External memory computation:

We can see that the SPL code of implementing an external memory computation and that of implementing an in-memory computation is basically the same, without extra computational load.
It is easy to implement parallelism in SPL. We just need to add @m option to the serial computing code. This is far simpler than the corresponding Java method.

Seamless integration into Java applications
SPL is developed in Java, so it can work by embedding its JARs in the Java application. And the application executes or invokes the SPL script via the standard JDBC. This makes SPL very lightweight, and it can even run on Android.
Call SPL code through JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call SplScript(?)");
st.setObject(1, "A");
st.execute();
ResultSet rs = st.getResultSet();
ResultSetMetaData rsmd = rs.getMetaData();
As it is lightweight and integration-friendly, SPL can be seamlessly integrated into mainstream Java frameworks, especially suitable for serving as a computing engine within microservice architectures.
Highly open framework
SPL’s great openness enables it to directly connect to various types of data sources and perform real-time mixed computations, making it easy to handle computing scenarios where databases are unavailable or multiple/diverse databases are involved.

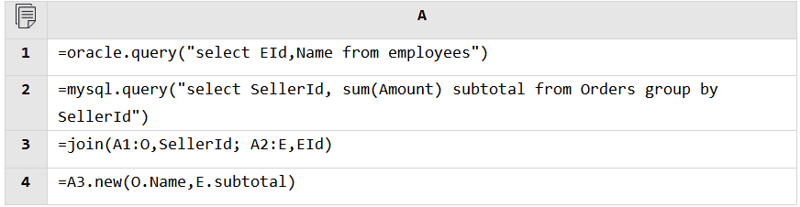
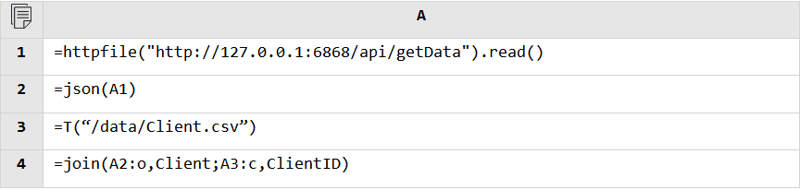
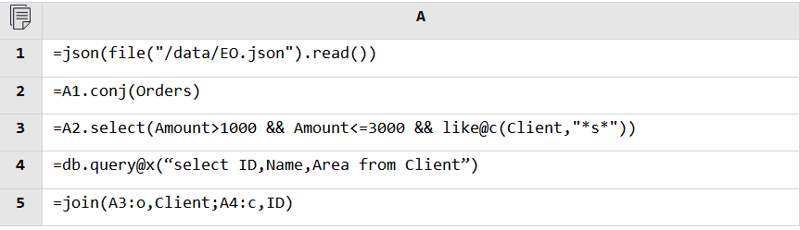
Regardless of the data source, SPL can read data from it and perform the mixed computation as long as it is accessible. Database and database, RESTful and file, JSON and database, anything is fine.
Databases:
RESTful and file:
JSON and database:
Interpreted execution and hot-swapping
SPL is an interpreted language that inherently supports hot swapping while power remains switched on. Modified code takes effect in real-time without requiring service restarts. This makes SPL well adapt to dynamic data processing requirements.

This hot—swapping capability enables independent computing modules with separate management, maintenance and operation, creating more flexible and convenient uses.
SPL can significantly increase Java programmers’ development efficiency while achieving framework advantages. It combines merits of both Java and SQL, and further simplifies code and elevates performance.
SPL open source address
위 내용은 Java 프로그래머의 개발 효율성을 두 배로 높일 수 있는 방법이 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



