

Snowflake(SiS)에서 Streamlit을 사용하여 토큰 개수 확인 앱을 만들었습니다.

소개
안녕하세요. 저는 Snowflake의 영업 엔지니어입니다. 다양한 포스팅을 통해 저의 경험과 실험을 여러분과 공유하고 싶습니다. 이 기사에서는 토큰 수를 확인하고 Cortex LLM의 비용을 추정하기 위해 Snowflake에서 Streamlit을 사용하여 앱을 만드는 방법을 보여 드리겠습니다.
참고: 이 게시물은 Snowflake의 의견이 아닌 개인적인 견해를 나타냅니다.
Snowflake(SiS)의 Streamlit이란 무엇입니까?
Streamlit은 HTML/CSS/JavaScript가 필요 없이 간단한 Python 코드로 웹 UI를 만들 수 있는 Python 라이브러리입니다. 앱 갤러리에서 예시를 보실 수 있습니다.
Snowflake의 Streamlit을 사용하면 Snowflake에서 직접 Streamlit 웹 앱을 개발하고 실행할 수 있습니다. Snowflake 계정만 있으면 사용하기 쉽고 Snowflake 테이블 데이터를 웹 앱에 통합하는 데 적합합니다.
Snowflake의 Streamlit 정보(공식 Snowflake 문서)
눈송이 피질이란 무엇입니까?
Snowflake Cortex는 Snowflake의 생성 AI 기능 모음입니다. Cortex LLM을 사용하면 SQL 또는 Python의 간단한 함수를 사용하여 Snowflake에서 실행되는 대규모 언어 모델을 호출할 수 있습니다.
LLM(대형 언어 모델) 함수(Snowflake Cortex)(공식 Snowflake 문서)
기능 개요
영상
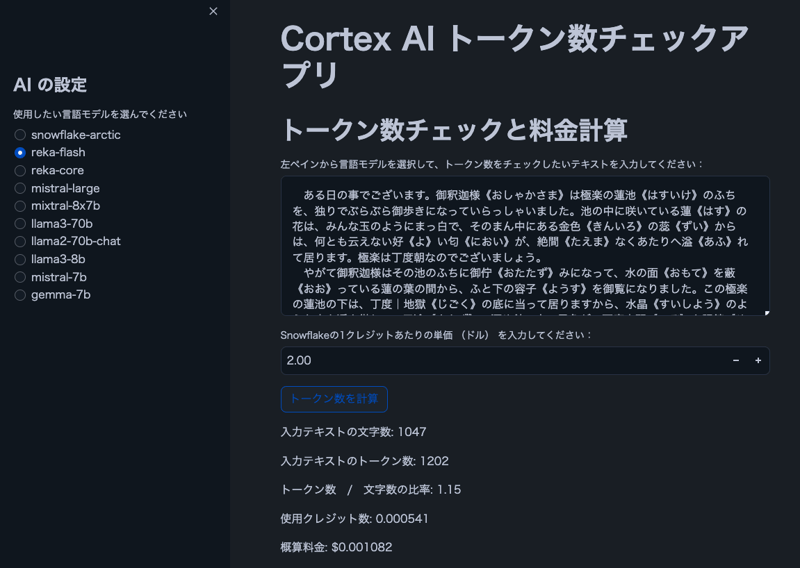
참고: 이미지의 텍스트는 아쿠타가와 류노스케의 "거미줄"에서 가져온 것입니다.
특징
- 사용자는 Cortex LLM 모델을 선택할 수 있습니다
- 사용자 입력 텍스트에 대한 문자 및 토큰 수 표시
- 캐릭터 대비 토큰 비율 표시
- Snowflake 크레딧 가격을 기준으로 예상 비용 계산
참고: Cortex LLM 가격표(PDF)
전제 조건
- Cortex LLM 액세스 권한이 있는 Snowflake 계정
- snowflake-ml-python 1.1.2 이상
참고: Cortex LLM 지역 가용성(공식 Snowflake 문서)
소스 코드
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
결론
이 앱을 사용하면 특히 문자 수와 토큰 수 사이에 차이가 있는 일본어와 같은 언어를 처리할 때 LLM 워크로드 비용을 더 쉽게 예측할 수 있습니다. 도움이 되셨으면 좋겠습니다!
공지사항
X의 Snowflake 새로운 기능 업데이트
Snowflake의 X에 대한 새로운 소식을 공유하고 있습니다. 관심이 있으시면 언제든지 팔로우해주세요!
영어 버전
Snowflake What's New Bot(영어 버전)
https://x.com/snow_new_en
일본어 버전
Snowflake What's New Bot(일본어 버전)
https://x.com/snow_new_jp
변경 내역
(20240914) 첫글
일본어 원본 기사
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
위 내용은 Snowflake(SiS)에서 Streamlit을 사용하여 토큰 개수 확인 앱을 만들었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7315
7315
 9
1625
14
1348
46
1261
25
1208
29
9
1625
14
1348
46
1261
25
1208
29








 Tensorflow 또는 Pytorch로 딥 러닝을 수행하는 방법은 무엇입니까?
Mar 10, 2025 pm 06:52 PM
Tensorflow 또는 Pytorch로 딥 러닝을 수행하는 방법은 무엇입니까?
Mar 10, 2025 pm 06:52 PM
Tensorflow 또는 Pytorch로 딥 러닝을 수행하는 방법은 무엇입니까?
