

나의 첫 오픈소스 기여

문제 제기
첫 번째 기여로 프롬프트 및 완료 생성에 사용되는 토큰을 표시하는 새 플래그 옵션을 추가하는 새로운 기능을 다른 프로젝트에 추가하는 문제를 제출했습니다.
 특징: 채팅 완료 토큰 정보 플래그 옵션
#8
특징: 채팅 완료 토큰 정보 플래그 옵션
#8
 특징: 채팅 완료 토큰 정보 플래그 옵션
#8
특징: 채팅 완료 토큰 정보 플래그 옵션
#8

설명
사용자에게 전송 및 수신된 토큰 수를 제공하는 플래그 옵션입니다. 채팅 완료 요청 시 토큰 예산 내에서 사용자가 머물도록 안내하는 중요한 기능이라고 생각합니다!
구현
이를 위해서는 -t 및 --token-usage가 될 수 있는 또 다른 옵션 플래그를 추가해야 합니다. 사용자가 명령에 이 플래그를 포함하면 완성 생성에 사용된 토큰 수와 프롬프트에 사용된 토큰 수를 명확하게 자세히 표시해야 합니다.
저는 fadingNA의 오픈 소스 프로젝트인 chat-minal에 기여하기로 결정했습니다. chat-minal은 Python으로 작성된 CLI 도구로 OpenAI를 활용하여 코드 검토 생성, 파일 변환, 마크다운 생성 등 다양한 작업을 수행할 수 있습니다. 텍스트, 텍스트 요약.
내 풀 요청
이전에 Python으로 코드를 작성해 본 적이 있지만 그것이 내 능력이 가장 뛰어난 것은 아닙니다. 따라서 이 프로젝트에 참여하는 것은 나에게 어렵지만 좋은 학습 경험을 제공합니다.
문제는 다른 사람의 코드를 읽고 이해해야 하며 코드의 디자인을 깨지 않는 방식으로 적절한 솔루션을 제공해야 한다는 것입니다. 코드를 크게 변경하지 않고도 효율적으로 기능을 추가하고 코드의 일관성을 유지하려면 흐름을 이해하는 것이 중요합니다.
FEAT: 토큰 사용 플래그
#9
특징
사용자에 대해 --token_usage 플래그 옵션을 포함하는 기능을 추가했습니다. 이 옵션은 프롬프트 및 생성된 완료에 사용된 토큰 수에 대한 정보를 사용자에게 제공합니다.
구현
코드 설계를 바탕으로 제가 생각해낸 해결책은 token_usage 플래그가 있는지 확인하는 것입니다. token_usage 플래그가 사용되지 않은 경우 코드에서 불필요한 if 문을 확인하는 것을 원하지 않기 때문에 청크 내부에 Usage_metadata가 있는지 확인하는 차이점을 제외하고 두 개의 별도의 동일한 루프 논리를 만들었습니다.
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)디스플레이
At the end of the execution of get_completions() method, a check for the flag token_usage is added, which then displays the token usage details to stderr if the flag was used.
if token_usage:
logger.error(f"Tokens used for completion: <span class="pl-s1"><span class="pl-kos">{completion_tokens}</span>"</span>)
logger.error(f"Tokens used for prompt: <span class="pl-s1"><span class="pl-kos">{prompt_tokens}</span>"</span>)My solution
Retrieving the token usage
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
Originally, the code only had one for loop which retrieves the content from a stream and appends it to an array which forms the response of the completion.
Why did I write it this way?
My reasoning behind duplicating the for while adding the distinct if block is to prevent the code from repeatedly checking the if block even if the user is not using the newly added --token_usage flag. So instead, I check for the existence of the flag firstly, and then decide which for loop to execute.
Realization
Even though my pull request has been accepted by the project owner, I realized late that this way adds complexity to the code's maintainability. For example, if there are changes required in the for loop for processing the stream, that means modifying the code twice since there are two identical for loops.
What I think I could do as an improvement for it is to make it into a function so that any changes required can be done in one function only, keeping the maintainability of the code. This just proves that even if I wrote the code with optimization in mind, there are still other things that I can miss which is crucial to a project, which in this case, is maintainability.
Receiving a pull request
My tool, genereadme, also received a contribution. I received a PR from Mounayer, which is to add the same feature to my project.
feat: added a new flag that displays the number of tokens sent in prompt and received in completion
#13

Description
Closes #12.
- Added a new flag --token-usage which when given, prints the number of tokens that were sent in the prompt and the number of tokens that were returned in the completion to `stderr.
This simply required the addition for another flag check --token-usage:
.option("--token-usage", "Show prompt and completion token usage")I've also made sure to keep your naming conventions/formatting style consistent, in the for loop that does the chat completion for each file processed, I have accumulated the total tokens sent and received:
promptTokens += response.usage.prompt_tokens;
completionTokens += response.usage.completion_tokens;which I then display at the end of program run-time if the --token-usage flag is provided as such:
if (program.opts().tokenUsage) {
console.error(`Prompt tokens: <span class="pl-s1"><span class="pl-kos">${promptTokens}</span>`</span>);
console.error(`Completion tokens: <span class="pl-s1"><span class="pl-kos">${completionTokens}</span>`</span>);
}- Updated README.md to explain the new flag.
Testing
Test 1
genereadme examples/sum.js --token-usage
This should display something like:
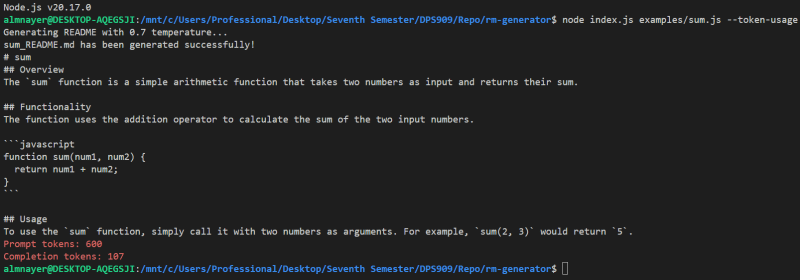
Test 2
You can try it out with multiple files too, i.e.:
genereadme examples/sum.js examples/createUser.js --token-usage
This time, instead of having to read someone else's code, someone had to read mine and contribute to it. It is nice knowing that someone is able to contribute to my project. To me, it means that they understood how my code works, so they were able to add the feature without breaking anything or adding any complexity to the code base.
With that being mentioned, reading code is also a skill that is not to be underestimated. My code is nowhere near perfect and I know there are still places I can improve on, so credit is also due to being able to read and understand code.
This specific pull request did not really require any back and forth changes as the code that was written by Mounayer is what I would have written myself.
위 내용은 나의 첫 오픈소스 기여의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Python vs. C : 응용 및 사용 사례가 비교되었습니다
Apr 12, 2025 am 12:01 AM
Python vs. C : 응용 및 사용 사례가 비교되었습니다
Apr 12, 2025 am 12:01 AM
Python은 데이터 과학, 웹 개발 및 자동화 작업에 적합한 반면 C는 시스템 프로그래밍, 게임 개발 및 임베디드 시스템에 적합합니다. Python은 단순성과 강력한 생태계로 유명하며 C는 고성능 및 기본 제어 기능으로 유명합니다.
 2 시간 안에 얼마나 많은 파이썬을 배울 수 있습니까?
Apr 09, 2025 pm 04:33 PM
2 시간 안에 얼마나 많은 파이썬을 배울 수 있습니까?
Apr 09, 2025 pm 04:33 PM
2 시간 이내에 파이썬의 기본 사항을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우십시오. 이를 통해 간단한 파이썬 프로그램 작성을 시작하는 데 도움이됩니다.
 파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
Python은 게임 및 GUI 개발에서 탁월합니다. 1) 게임 개발은 Pygame을 사용하여 드로잉, 오디오 및 기타 기능을 제공하며 2D 게임을 만드는 데 적합합니다. 2) GUI 개발은 Tkinter 또는 PYQT를 선택할 수 있습니다. Tkinter는 간단하고 사용하기 쉽고 PYQT는 풍부한 기능을 가지고 있으며 전문 개발에 적합합니다.
 2 시간의 파이썬 계획 : 현실적인 접근
Apr 11, 2025 am 12:04 AM
2 시간의 파이썬 계획 : 현실적인 접근
Apr 11, 2025 am 12:04 AM
2 시간 이내에 Python의 기본 프로그래밍 개념과 기술을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우기, 2. 마스터 제어 흐름 (조건부 명세서 및 루프), 3. 기능의 정의 및 사용을 이해하십시오. 4. 간단한 예제 및 코드 스 니펫을 통해 Python 프로그래밍을 신속하게 시작하십시오.
 Python vs. C : 학습 곡선 및 사용 편의성
Apr 19, 2025 am 12:20 AM
Python vs. C : 학습 곡선 및 사용 편의성
Apr 19, 2025 am 12:20 AM
Python은 배우고 사용하기 쉽고 C는 더 강력하지만 복잡합니다. 1. Python Syntax는 간결하며 초보자에게 적합합니다. 동적 타이핑 및 자동 메모리 관리를 사용하면 사용하기 쉽지만 런타임 오류가 발생할 수 있습니다. 2.C는 고성능 응용 프로그램에 적합한 저수준 제어 및 고급 기능을 제공하지만 학습 임계 값이 높고 수동 메모리 및 유형 안전 관리가 필요합니다.
 파이썬 : 기본 응용 프로그램 탐색
Apr 10, 2025 am 09:41 AM
파이썬 : 기본 응용 프로그램 탐색
Apr 10, 2025 am 09:41 AM
Python은 웹 개발, 데이터 과학, 기계 학습, 자동화 및 스크립팅 분야에서 널리 사용됩니다. 1) 웹 개발에서 Django 및 Flask 프레임 워크는 개발 프로세스를 단순화합니다. 2) 데이터 과학 및 기계 학습 분야에서 Numpy, Pandas, Scikit-Learn 및 Tensorflow 라이브러리는 강력한 지원을 제공합니다. 3) 자동화 및 스크립팅 측면에서 Python은 자동화 된 테스트 및 시스템 관리와 같은 작업에 적합합니다.
 파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
제한된 시간에 Python 학습 효율을 극대화하려면 Python의 DateTime, Time 및 Schedule 모듈을 사용할 수 있습니다. 1. DateTime 모듈은 학습 시간을 기록하고 계획하는 데 사용됩니다. 2. 시간 모듈은 학습과 휴식 시간을 설정하는 데 도움이됩니다. 3. 일정 모듈은 주간 학습 작업을 자동으로 배열합니다.
 파이썬 : 다목적 프로그래밍의 힘
Apr 17, 2025 am 12:09 AM
파이썬 : 다목적 프로그래밍의 힘
Apr 17, 2025 am 12:09 AM
Python은 초보자부터 고급 개발자에 이르기까지 모든 요구에 적합한 단순성과 힘에 호의적입니다. 다목적 성은 다음과 같이 반영됩니다. 1) 배우고 사용하기 쉽고 간단한 구문; 2) Numpy, Pandas 등과 같은 풍부한 라이브러리 및 프레임 워크; 3) 다양한 운영 체제에서 실행할 수있는 크로스 플랫폼 지원; 4) 작업 효율성을 향상시키기위한 스크립팅 및 자동화 작업에 적합합니다.
