
Django REST에 CSV 파일을 업로드하는 것은(특히 원자 설정에서) 간단한 작업이지만 공유할 몇 가지 요령을 발견할 때까지 계속 혼란스러웠습니다.
이 글에서는 (프런트엔드 대신) postman을 사용할 것이며, 사진을 통한 요청 전송을 위해 postman에 설정해야 할 사항도 공유하겠습니다.
우리가 원하는 것
방법
pip 설치 팬더
값 셀의 경우 '파일 선택' 버튼을 클릭하고 CSV를 업로드하세요. 아래 스크린샷을 확인하세요

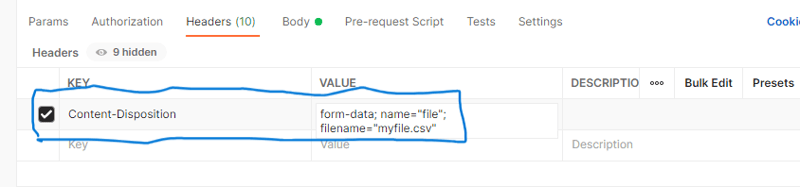
헤더 아래에서 Content-Disposition과 값을 form-data로 설정합니다. 이름="파일"; 파일 이름="your_file_name.csv". your_file_name.csv를 실제 파일 이름으로 바꾸십시오. 아래 스크린샷을 확인해보세요.
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
위 코드 설명:
코드는 필요한 패키지를 가져오고, 클래스 기반 보기를 정의하고, 파서 클래스(FileUploadParser)를 설정하는 것으로 시작됩니다. 클래스에 있는 post 메소드의 첫 번째 부분은 request.FILES에서 파일을 가져오고 해당 파일의 가용성을 확인하려고 시도합니다.
그런 다음 간단한 검증을 통해 확장자를 확인하여 CSV인지 확인합니다.
다음 부분에서는 이를 Pandas 데이터 프레임(스프레드시트와 매우 유사)에 로드합니다.
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
로딩 함수에 전달되는 몇 가지 인수에 대해 설명하겠습니다.
건너뛰기
로드된 csv 파일을 읽을 때 이 경우 csv는 네트워크를 통해 전달되므로 항목과 같은 일부 메타데이터가 파일의 시작과 끝에 추가된다는 점에 유의해야 합니다. 이러한 것들은 성가실 수 있고 쉼표로 구분된 값(csv) 형식이 아니므로 실제로 구문 분석 시 오류가 발생할 수 있습니다. 이는 메타데이터와 헤더가 포함된 처음 3개 행을 건너뛰고 CSV 본문에 직접 배치하기 위해 Skiprows=3을 사용한 이유를 설명합니다. Skiprow를 제거하거나 더 적은 숫자를 사용하는 경우 다음과 같은 오류가 발생할 수 있습니다. 데이터 토큰화 중 오류가 발생했습니다. C 오류가 발생하거나 헤더부터 데이터가 시작되는 것을 볼 수 있습니다.
dtype=str
Pandas는 특정 열의 데이터 유형을 추측하는 데 현명함을 입증하는 것을 좋아합니다. 모든 값을 문자열로 원했기 때문에 dtype=str
구분자
셀이 분리되는 방법을 지정합니다. 기본값은 일반적으로 쉼표입니다.
iloc[:-1]
iloc를 사용하여 데이터프레임을 분할하고 df 끝의 메타데이터를 제거해야 했습니다.
그런 다음 다음 줄 df = df.where(pd.notnull(df), None)은 모든 NaN 값을 None으로 변환합니다. NaNi는 pandas가 None을 나타내는 데 사용하는 대체 값입니다.
다음 블록이 좀 까다롭네요. 데이터프레임의 모든 행을 반복하고, BiodataModel을 사용하여 행 데이터를 인스턴스화하고, 대량 생성이 Django 검증을 우회하기 때문에 full_clean() 메서드를 사용하여 모델 수준 검증(시리얼라이저 수준 아님)을 수행한 다음 생성 작업을 호출된 목록에 추가합니다. 대량 데이터. 예, 추가는 아직 실행되지 않았습니다! 기억하세요. 우리는 원자적 작업(배치 수준에서)을 수행하려고 하므로 모두 또는 없음을 원합니다. 행을 개별적으로 저장한다고 해서 모든 동작이 제공되거나 전혀 제공되지는 않습니다.
그럼 마지막으로 중요한 부분입니다. transaction.atomic() 블록(동작 전체 또는 없음 제공) 내에서 BiodataModel.objects.bulk_create(bulk_data)를 실행하여 모든 행을 한 번에 저장합니다.
한 가지 더. for 루프의 index 변수와 Except 블록을 확인하세요. 블록 제외 오류 메시지에서 df.iterrows()에서 파생된 index변수에 2를 추가했습니다. Excel 파일에서 볼 때 해당 값이 해당 행과 정확히 일치하지 않았기 때문입니다. Except 블록은 모든 오류를 포착하고 Excel에서 열 때 정확한 행 번호가 포함된 오류 메시지를 구성하므로 업로더가 Excel 파일에서 해당 줄을 쉽게 찾을 수 있습니다!
읽어주셔서 감사합니다!!!
사용된 도구 버전
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
위 내용은 DJANGO REST에 CSV 파일을 업로드하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



