
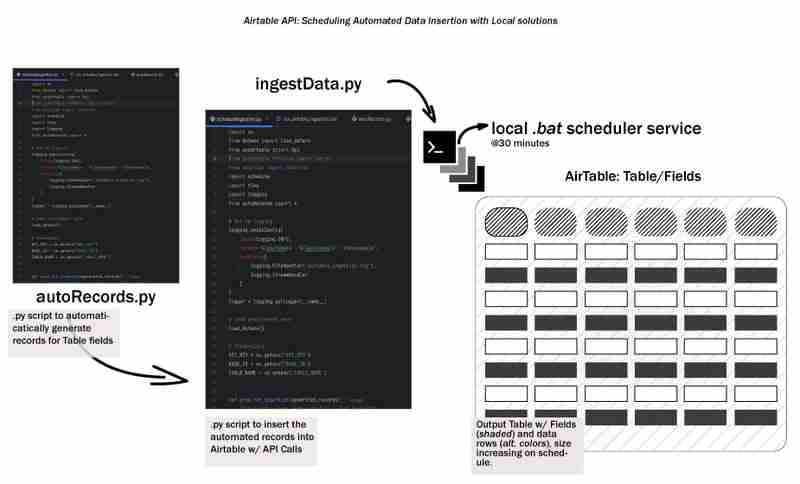
전체 데이터 수명주기는 데이터를 생성하고 어딘가에 어떤 방식으로든 저장하는 것부터 시작됩니다. 이를 초기 단계 데이터 수명 주기라고 부르며 로컬 워크플로를 사용하여 Airtable으로 데이터를 자동으로 수집하는 방법을 살펴보겠습니다. 개발 환경 설정, 수집 프로세스 설계, 배치 스크립트 생성, 워크플로 예약 등을 간단하고 로컬/재현 가능하며 접근 가능하게 유지하는 방법을 다룹니다.
먼저 에어테이블(Airtable)에 대해 알아보겠습니다. Airtable은 스프레드시트의 단순성과 데이터베이스 구조를 결합한 강력하고 유연한 도구입니다. 정보 정리, 프로젝트 관리, 작업 추적에 적합하며 무료 등급도 있습니다!
우리는 Python으로 이 프로젝트를 개발할 것이므로 가장 좋아하는 IDE를 점심으로 먹고 가상 환경을 만드세요
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate
Airtable을 시작하려면 Airtable 웹사이트를 방문하세요. 무료 계정에 가입한 후에는 새 작업 공간을 만들어야 합니다. 작업공간을 모든 관련 테이블과 데이터의 컨테이너로 생각하세요.
다음으로 작업공간 내에 새 테이블을 만듭니다. 테이블은 기본적으로 데이터를 저장하는 스프레드시트입니다. 데이터 구조와 일치하도록 테이블의 필드(열)를 정의하세요.
다음은 튜토리얼에서 사용된 필드의 일부입니다. 텍스트, 날짜 및 숫자를 조합한 것입니다.
스크립트를 Airtable에 연결하려면 API 키 또는 개인 액세스 토큰을 생성해야 합니다. 이 키는 비밀번호 역할을 하여 스크립트가 Airtable 데이터와 상호 작용할 수 있게 해줍니다. 키를 생성하려면 Airtable 계정 설정으로 이동하여 API 섹션을 찾은 후 지침에 따라 새 키를 생성하세요.
*API 키를 안전하게 보관하세요. 공개적으로 공유하거나 공개 저장소에 커밋하지 마세요. *
다음으로, require.txt를 터치하세요. 이 .txt 파일 안에 다음 패키지를 넣으세요:
pyairtable schedule faker python-dotenv
이제 pip install -r 요구사항.txt를 실행하여 필수 패키지를 설치하세요.
이 단계에서는 스크립트를 생성합니다. .env는 자격 증명 autoRecords.py을 저장하는 곳입니다. 정의된 필드와 ingestData.py Airtable에 레코드를 삽입합니다.
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate
좋네요. 이 직원 데이터 생성기에 블로그 게시물에 대한 집중적인 하위 주제 콘텐츠를 모아보겠습니다.
직원 데이터가 포함된 프로젝트를 진행하는 경우 현실적인 샘플 데이터를 생성할 수 있는 안정적인 방법을 갖는 것이 도움이 되는 경우가 많습니다. HR 관리 시스템, 직원 디렉토리 등 무엇을 구축하든 강력한 테스트 데이터에 액세스하면 개발을 간소화하고 애플리케이션의 탄력성을 높일 수 있습니다.
이 섹션에서는 다양한 관련 필드를 사용하여 무작위 직원 기록을 생성하는 Python 스크립트를 살펴보겠습니다. 이 도구는 애플리케이션에 현실적인 데이터를 빠르고 쉽게 채워야 할 때 귀중한 자산이 될 수 있습니다.
데이터 생성 프로세스의 첫 번째 단계는 각 직원 기록에 대한 고유 식별자를 만드는 것입니다. 애플리케이션에서 각 개별 직원을 고유하게 참조하는 방법이 필요할 수 있으므로 이는 중요한 고려 사항입니다. 우리 스크립트에는 다음 ID를 생성하는 간단한 함수가 포함되어 있습니다.
pyairtable schedule faker python-dotenv
이 함수는 "N-#####" 형식으로 고유 ID를 생성합니다. 여기서 숫자는 임의의 5자리 값입니다. 특정 요구 사항에 맞게 이 형식을 사용자 정의할 수 있습니다.
다음으로 사원기록 자체를 생성하는 핵심 기능을 살펴보겠습니다. generate_random_records() 함수는 생성할 레코드 수를 입력으로 사용하고 사전 목록을 반환합니다. 여기서 각 사전은 다양한 필드가 있는 직원을 나타냅니다.
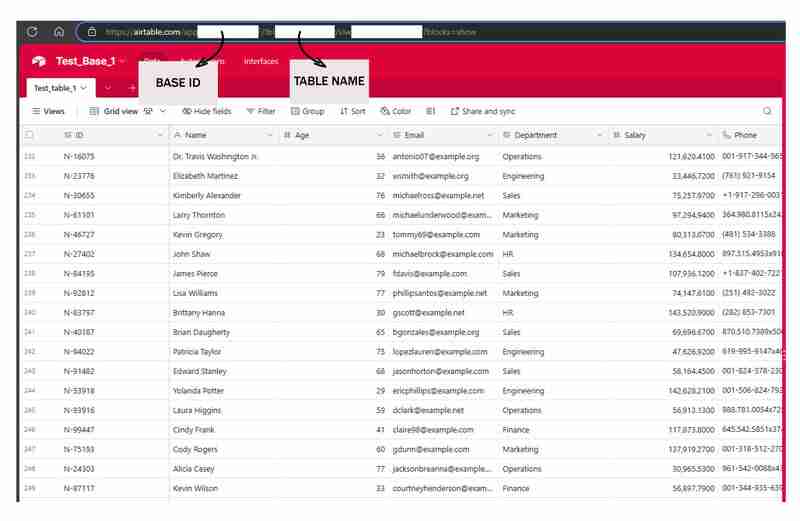
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
이 기능은 Faker 라이브러리를 사용하여 이름, 이메일, 전화번호, 주소 등 다양한 직원 필드에 대해 사실적으로 보이는 데이터를 생성합니다. 또한 연령대와 급여 범위를 합리적인 값으로 제한하는 등 몇 가지 기본적인 제약 사항도 포함되어 있습니다.
이 함수는 사전 목록을 반환하며, 각 사전은 Airtable과 호환되는 형식으로 직원 기록을 나타냅니다.
마지막으로 직원 기록 목록을 가져와 각 기록의 '필드' 부분을 추출하는 prepare_records_for_airtable() 함수를 살펴보겠습니다. Airtable이 데이터를 가져올 때 기대하는 형식은 다음과 같습니다.
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
이 기능을 사용하면 데이터 구조를 단순화하여 생성된 데이터를 에어테이블이나 다른 시스템과 통합할 때 작업하기가 더 쉽습니다.
모두 합치기
이 데이터 생성 도구를 사용하려면 원하는 레코드 수로 generate_random_records() 함수를 호출한 다음 결과 목록을 prepare_records_for_airtable() 함수에 전달할 수 있습니다.
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate
이렇게 하면 무작위 직원 기록 2개가 생성되어 원본 형식으로 인쇄된 다음 Airtable에 적합한 플랫 형식으로 기록이 인쇄됩니다.
실행:
pyairtable schedule faker python-dotenv
출력:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
실제 직원 데이터를 생성하는 것 외에도 우리의 스크립트는 해당 데이터를 Airtable과 원활하게 통합하는 기능도 제공합니다
생성된 데이터를 Airtable에 삽입하기 전에 플랫폼에 대한 연결을 설정해야 합니다. 우리 스크립트는 pyairtable 라이브러리를 사용하여 Airtable API와 상호 작용합니다. Airtable API 키와 데이터를 저장하려는 기본 ID 및 테이블 이름을 포함하여 필요한 환경 변수를 로드하는 것부터 시작합니다.
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
이러한 자격 증명을 사용하여 Airtable API 클라이언트를 초기화하고 작업하려는 특정 테이블에 대한 참조를 얻을 수 있습니다.
def generate_random_records(num_records=10):
"""
Generate random records with reasonable constraints
:param num_records: Number of records to generate
:return: List of records formatted for Airtable
"""
records = []
# Constants
departments = ['Sales', 'Engineering', 'Marketing', 'HR', 'Finance', 'Operations']
statuses = ['Active', 'On Leave', 'Contract', 'Remote']
for _ in range(num_records):
# Generate date in the correct format
random_date = datetime.now() - timedelta(days=random.randint(0, 365))
formatted_date = random_date.strftime('%Y-%m-%dT%H:%M:%S.000Z')
record = {
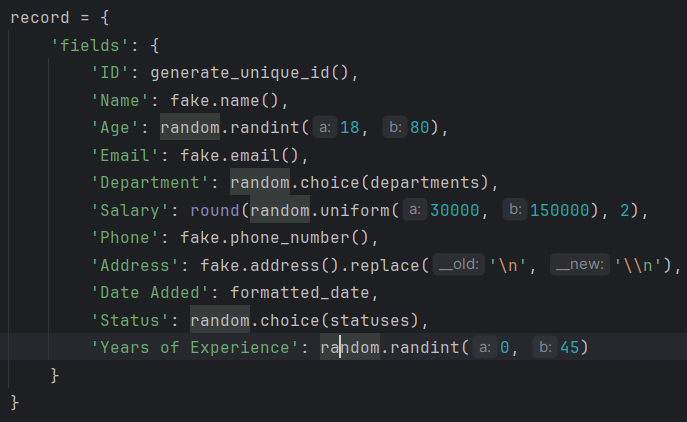
'fields': {
'ID': generate_unique_id(),
'Name': fake.name(),
'Age': random.randint(18, 80),
'Email': fake.email(),
'Department': random.choice(departments),
'Salary': round(random.uniform(30000, 150000), 2),
'Phone': fake.phone_number(),
'Address': fake.address().replace('\n', '\n'), # Escape newlines
'Date Added': formatted_date,
'Status': random.choice(statuses),
'Years of Experience': random.randint(0, 45)
}
}
records.append(record)
return records
이제 연결이 설정되었으므로 이전 섹션의 generate_random_records() 함수를 사용하여 직원 기록 배치를 생성한 다음 이를 Airtable에 삽입할 수 있습니다.
def prepare_records_for_airtable(records):
"""Convert records from nested format to flat format for Airtable"""
return [record['fields'] for record in records]
prep_for_insertion() 함수는 generate_random_records()에서 반환된 중첩 레코드 형식을 Airtable API에서 예상하는 플랫 형식으로 변환하는 역할을 합니다. 데이터가 준비되면 table.batch_create() 메서드를 사용하여 단일 대량 작업으로 레코드를 삽입합니다.
통합 프로세스가 강력하고 쉽게 디버깅할 수 있도록 몇 가지 기본 오류 처리 및 로깅 기능도 포함했습니다. 데이터 삽입 프로세스 중에 오류가 발생하면 스크립트는 문제 해결에 도움이 되는 오류 메시지를 기록합니다.
if __name__ == "__main__":
records = generate_random_records(2)
print(records)
prepared_records = prepare_records_for_airtable(records)
print(prepared_records)
이전 스크립트의 강력한 데이터 생성 기능과 여기에 표시된 통합 기능을 결합하면 Airtable 기반 애플리케이션에 현실적인 직원 데이터를 빠르고 안정적으로 채울 수 있습니다.
데이터 수집 프로세스를 완전히 자동화하기 위해 정기적으로 Python 스크립트를 실행하는 배치 스크립트(.bat 파일)를 만들 수 있습니다. 이를 통해 수동 개입 없이 자동으로 데이터 수집이 이루어지도록 설정할 수 있습니다.
다음은 ingestData.py 스크립트를 실행하는 데 사용할 수 있는 배치 스크립트의 예입니다.
python autoRecords.py
이 스크립트의 주요 부분을 분석해 보겠습니다.
이 배치 스크립트가 자동으로 실행되도록 예약하려면 Windows 작업 스케줄러를 사용할 수 있습니다. 단계에 대한 간략한 개요는 다음과 같습니다.

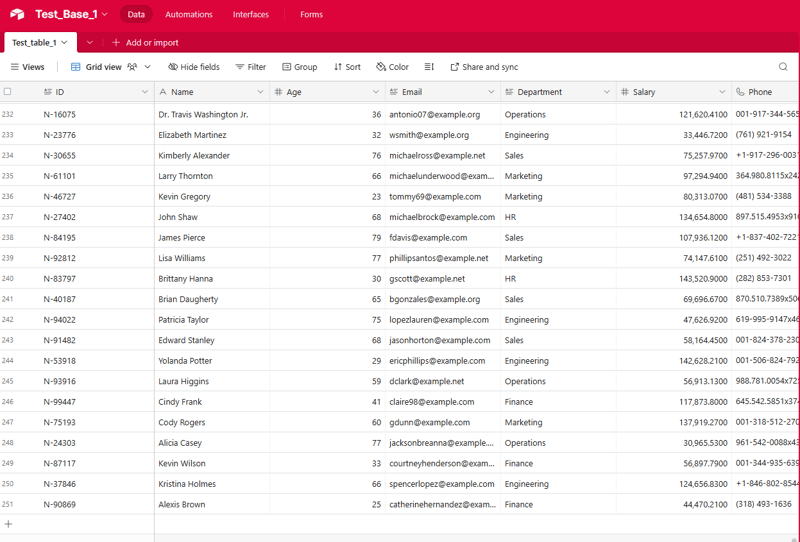
이제 Windows 작업 스케줄러는 지정된 간격으로 배치 스크립트를 자동으로 실행하여 수동 개입 없이 Airtable 데이터가 정기적으로 업데이트되도록 합니다.
이는 테스트, 개발은 물론 데모 목적으로도 매우 유용한 도구가 될 수 있습니다.
이 가이드 전체에서는 필요한 개발 환경을 설정하고, 수집 프로세스를 설계하고, 작업을 자동화하기 위한 배치 스크립트를 만들고, 무인 실행을 위한 워크플로를 예약하는 방법을 배웠습니다. 이제 우리는 로컬 자동화의 힘을 활용하여 데이터 수집 작업을 간소화하고 Airtable 기반 데이터 생태계
에서 귀중한 통찰력을 얻는 방법을 확실히 이해했습니다.이제 자동화된 데이터 수집 프로세스를 설정했으므로 이 기반을 구축하고 Airtable 데이터에서 더 많은 가치를 창출할 수 있는 다양한 방법이 있습니다. 코드를 실험하고, 새로운 사용 사례를 탐색하고, 커뮤니티와 경험을 공유해 보시기 바랍니다.
시작하는 데 도움이 되는 몇 가지 아이디어는 다음과 같습니다.
가능성은 무궁무진합니다! 이 자동화된 데이터 수집 프로세스를 어떻게 구축하고 Airtable 데이터에서 새로운 통찰력과 가치를 얻을 수 있을지 기대됩니다. 주저하지 말고 실험하고, 협력하고, 진행 상황을 공유하세요. 저는 여러분이 가는 길을 지원하기 위해 여기 있습니다.
전체 코드 보기(https://github.com/AkanimohOD19A/scheduling_airtable_insertion), 전체 동영상 튜토리얼이 진행 중입니다.
위 내용은 로컬 워크플로: Airtable에 대한 데이터 수집 조정의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



