
Google 검색 스크래핑은 필수 SERP 분석, SEO 최적화 및 데이터 수집 기능을 제공합니다. 최신 스크래핑 도구를 사용하면 이 프로세스가 더욱 빠르고 안정적으로 이루어집니다.
커뮤니티 회원 중 한 명이 Crawlee 블로그에 기고하기 위해 이 블로그를 썼습니다. 이와 같은 블로그를 Crawlee 블로그에 기고하고 싶으시면 Discord 채널을 통해 연락해 주세요.
이 가이드에서는 결과 순위 지정 및 페이지 매기기를 처리할 수 있는 Python용 Crawlee를 사용하여 Google 검색 스크레이퍼를 만듭니다.
다음과 같은 스크레이퍼를 만들겠습니다.
필수 종속성을 포함하여 Crawlee를 설치합니다.
pipx install crawlee[beautifulsoup,curl-impersonate]
Crawlee CLI를 사용하여 새 프로젝트 만들기:
pipx run crawlee create crawlee-google-search
메시지가 표시되면 템플릿 유형으로 Beautifulsoup를 선택하세요.
프로젝트 디렉토리로 이동하여 설치를 완료하세요.
cd crawlee-google-search poetry install
먼저 추출 범위를 정의해 보겠습니다. 이제 Google 검색결과에는 지도, 유명 인물, 회사 세부정보, 동영상, 일반적인 질문 및 기타 여러 요소가 포함됩니다. 표준 검색결과를 순위별로 분석하는 데 중점을 두겠습니다.
추출할 내용은 다음과 같습니다.

페이지의 HTML 코드에서 필요한 데이터를 추출할 수 있는지, 아니면 더 심층적인 분석이나 JS 렌더링이 필요한지 확인해 보겠습니다. 이 확인은 HTML 태그에 민감합니다.

페이지에서 얻은 데이터를 기반으로 필요한 모든 정보가 HTML 코드에 있습니다. 따라서 beautifulsoup_crawler를 사용할 수 있습니다.
추출할 필드:
먼저 크롤러 구성을 생성해 보겠습니다.
CurlImpersonateHttpClient를 사전 설정된 헤더와 함께 http_client로 사용하고 Chrome 브라우저와 관련된 가장을 수행합니다.
스크래핑 공격성을 제어하기 위해 ConcurrencySettings도 구성합니다. 이는 Google의 차단을 피하는 데 매우 중요합니다.
더 집중적으로 데이터를 추출해야 한다면 ProxyConfiguration 설정을 고려해 보세요.
pipx install crawlee[beautifulsoup,curl-impersonate]
먼저 추출해야 하는 요소의 HTML 코드를 분석해 보겠습니다.

읽을 수 있는 ID 속성과 생성 클래스 이름 및 기타 속성 사이에는 분명한 차이가 있습니다. 데이터 추출을 위한 선택기를 생성할 때 생성된 속성을 무시해야 합니다. Google이 N년 동안 생성된 특정 태그를 사용해 왔다는 내용을 읽었더라도 이에 의존해서는 안 됩니다. 이는 강력한 코드 작성 경험을 반영합니다.
이제 HTML 구조를 이해했으니 추출을 구현해 보겠습니다. 크롤러는 한 가지 유형의 페이지만 처리하므로 이를 처리하기 위해 router.default_handler를 사용할 수 있습니다. 핸들러 내에서 BeautifulSoup을 사용하여 각 검색 결과를 반복하면서 제목, URL, text_widget과 같은 데이터를 추출하고 결과를 저장합니다.
pipx run crawlee create crawlee-google-search
Google 결과는 검색 요청의 IP 위치정보에 따라 달라지므로 페이지 매김 시 링크 텍스트에 의존할 수 없습니다. 지리적 위치 및 언어 설정에 관계없이 작동하는 보다 정교한 CSS 선택기를 만들어야 합니다.
max_crawl_length 매개변수는 크롤러가 스캔해야 하는 페이지 수를 제어합니다. 강력한 선택기가 있으면 다음 페이지 링크를 가져와서 크롤러 대기열에 추가하기만 하면 됩니다.
더 효율적인 선택기를 작성하려면 CSS 및 XPath 구문의 기본을 배우세요.
cd crawlee-google-search poetry install
모든 검색 결과 데이터를 CSV와 같은 편리한 표 형식으로 저장하고 싶기 때문에 크롤러를 실행한 직후에 간단히export_data 메소드 호출을 추가하면 됩니다.
from crawlee.beautifulsoup_crawler import BeautifulSoupCrawler
from crawlee.http_clients.curl_impersonate import CurlImpersonateHttpClient
from crawlee import ConcurrencySettings, HttpHeaders
async def main() -> None:
concurrency_settings = ConcurrencySettings(max_concurrency=5, max_tasks_per_minute=200)
http_client = CurlImpersonateHttpClient(impersonate="chrome124",
headers=HttpHeaders({"referer": "https://www.google.com/",
"accept-language": "en",
"accept-encoding": "gzip, deflate, br, zstd",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}))
crawler = BeautifulSoupCrawler(
max_request_retries=1,
concurrency_settings=concurrency_settings,
http_client=http_client,
max_requests_per_crawl=10,
max_crawl_depth=5
)
await crawler.run(['https://www.google.com/search?q=Apify'])
핵심 크롤러 로직이 작동하는 동안 현재 결과에 순위 위치 정보가 부족하다는 점을 눈치채셨을 것입니다. 스크레이퍼를 완성하려면 요청의 user_data를 사용하여 요청 간에 데이터를 전달함으로써 적절한 순위 위치 추적을 구현해야 합니다.
여러 쿼리를 처리하고 검색 결과 분석을 위한 순위 위치를 추적하도록 스크립트를 수정해 보겠습니다. 또한 크롤링 깊이를 최상위 변수로 설정하겠습니다. 프로젝트 구조와 일치하도록 router.default_handler를 Routes.py로 이동해 보겠습니다.
@crawler.router.default_handler
async def default_handler(context: BeautifulSoupCrawlingContext) -> None:
"""Default request handler."""
context.log.info(f'Processing {context.request} ...')
for item in context.soup.select("div#search div#rso div[data-hveid][lang]"):
data = {
'title': item.select_one("h3").get_text(),
"url": item.select_one("a").get("href"),
"text_widget": item.select_one("div[style*='line']").get_text(),
}
await context.push_data(data)
또한 쿼리 및 order_no 필드와 기본 오류 처리를 추가하도록 핸들러를 수정해 보겠습니다.
await context.enqueue_links(selector="div[role='navigation'] td[role='heading']:last-of-type > a")
끝났습니다!
Google 검색 크롤러가 준비되었습니다. google_ranked.csv 파일의 결과를 살펴보겠습니다.
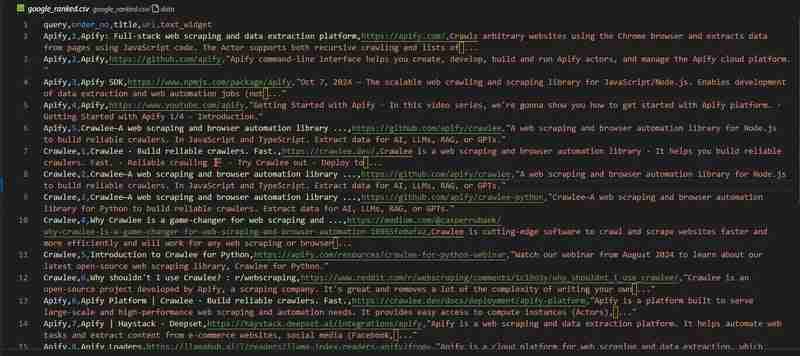
코드 저장소는 GitHub에서 사용할 수 있습니다
Google 순위 분석에 관한 이 기사에 소개된 프로젝트와 같이 수백만 개의 데이터 포인트가 필요한 대규모 프로젝트를 진행하는 경우 기성 솔루션이 필요할 수 있습니다.
Apify 팀의 Google 검색 결과 스크레이퍼 사용을 고려해 보세요.
다음과 같은 중요한 기능을 제공합니다.
Apify 블로그에서 자세한 내용을 알아볼 수 있습니다
이 블로그에서는 순위 데이터를 수집하는 Google 검색 크롤러를 만드는 방법을 단계별로 살펴보았습니다. 이 데이터 세트를 분석하는 방법은 귀하에게 달려 있습니다!
참고로 전체 프로젝트 코드는 GitHub에서 찾을 수 있습니다.
5년 후에는 "법학 석사를 위한 최고의 검색 엔진에서 데이터를 추출하는 방법"에 대한 기사를 작성해야 한다고 생각하고 싶지만, 5년 후에도 이 기사가 여전히 관련성이 있을 것으로 생각됩니다.
위 내용은 Python으로 Google 검색 결과를 긁는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



