
2023년 2월: 영화, TV 프로그램의 모든 점수와 이를 스트리밍할 수 있는 위치를 한 페이지에서 보고 싶었지만 나와 관련된 모든 소스가 포함된 수집기를 찾을 수 없었습니다.
2023년 3월: 그래서 즉석에서 점수를 획득하는 MVP를 구축하고 사이트를 온라인에 올렸습니다. 효과는 있었지만 느렸습니다(점수 표시에 10초 소요).
2023년 10월: 내 편에서 데이터를 저장하는 것이 필수라는 것을 깨닫고 windmill.dev를 발견했습니다. 비슷한 오케스트레이션 엔진을 쉽게 압도합니다. 적어도 내 요구 사항에는 적합합니다.
오늘로 돌아가서 12개월 동안의 지속적인 데이터 수집 끝에 파이프라인이 어떻게 작동하는지 자세히 공유하고 싶습니다. 다양한 소스에서 데이터를 수집하고, 데이터를 정규화하고, 쿼리에 최적화된 형식으로 결합하는 복잡한 시스템을 구축하는 방법을 배우게 됩니다.

실행 보기입니다. 모든 점은 흐름 실행을 나타냅니다. 흐름은 간단한 1단계 스크립트 등 무엇이든 될 수 있습니다.

중앙 블록에는 다음과 같은 스크립트가 포함되어 있습니다(단순화).
def main():
return tmdb_extract_daily_dump_data()
def tmdb_extract_daily_dump_data():
print("Checking TMDB for latest daily dumps")
init_mongodb()
daily_dump_infos = get_daily_dump_infos()
for daily_dump_info in daily_dump_infos:
download_zip_and_store_in_db(daily_dump_info)
close_mongodb()
return [info.to_mongo() for info in daily_dump_infos]
[...]
다음 beast도 흐름입니다(이것은 녹색 점 중 하나일 뿐임을 기억하세요).

(고해상도 이미지: https://i.imgur.com/LGhTUGG.png)
이것을 분석해 보겠습니다.
각 단계는 다소 복잡하며 비동기 프로세스를 사용합니다.
다음에 선택할 타이틀을 결정하기 위해 병렬로 처리되는 두 개의 레인이 있습니다. 이것은 Windmill이 빛나는 또 다른 영역입니다. 병렬화 및 오케스트레이션은 해당 아키텍처와 완벽하게 작동합니다.
다음 항목을 선택하는 두 가지 경로는 다음과 같습니다.
우선 데이터 소스별로 데이터가 첨부되지 않은 타이틀을 선택합니다. 이는 Metacritic 파이프라인에 아직 스크랩되지 않은 영화가 있으면 다음에 선택된다는 의미입니다. 이렇게 하면 새 타이틀을 포함하여 모든 타이틀이 최소한 한 번 처리됩니다.
모든 타이틀에 데이터가 첨부되면 파이프라인은 가장 최근 데이터가 있는 타이틀을 선택합니다.
다음은 이러한 흐름 실행의 예입니다. 비율 제한에 도달하여 오류가 발생했습니다.

Windmill을 사용하면 흐름의 각 단계에 대한 재시도를 쉽게 정의할 수 있습니다. 이 경우 오류가 발생할 경우 세 번 다시 시도하는 것이 논리입니다. 속도 제한에 도달하지 않는 한(일반적으로 다른 상태 코드 또는 오류 메시지) 즉시 중지됩니다.
위 내용은 작동하지만 심각한 문제가 있습니다. 최근 릴리스가 적시에 업데이트되지 않습니다. 모든 데이터 측면을 성공적으로 가져오는 데 몇 주 또는 몇 달이 걸릴 수 있습니다. 예를 들어, 영화에 최신 IMDb 점수가 있지만 다른 점수는 오래되었고 스트리밍 링크가 완전히 누락되는 경우가 발생할 수 있습니다. 특히 점수와 스트리밍 가용성에 대해 훨씬 더 나은 정확성을 얻고 싶었습니다.
이 문제를 해결하기 위해 두 번째 차선은 다른 우선 순위 지정 전략에 중점을 둡니다. 모든 데이터 소스에서 완전한 데이터 새로 고침을 위해 가장 인기 있고 인기 있는 영화/쇼가 선택됩니다. 이전에 이 흐름을 보여 드렸는데, 아까 짐승이라고 불렀던 그 놈이군요.
앱에 더 자주 표시되는 타이틀도 우선순위가 높아집니다. 즉, 영화나 프로그램이 상위 검색 결과에 나타날 때마다 또는 세부정보 보기가 열릴 때마다 곧 새로 고쳐질 가능성이 높습니다.
모든 타이틀은 그 동안 변경되지 않았을 가능성이 있는 데이터를 가져오지 않도록 우선순위 레인을 사용하여 일주일에 한 번만 새로 고칠 수 있습니다.
스크래핑이 합법인가요?라고 질문하실 수도 있습니다. 데이터를 가져오는 행위는 일반적으로 괜찮습니다. 하지만 데이터를 사용하여 수행하는 작업에는 신중한 고려가 필요합니다. 스크래핑된 데이터를 사용하는 서비스에서 이익을 얻는 순간 아마도 해당 서비스의 이용 약관을 위반하는 것입니다. (웹 스크래핑 및 '스크래핑'의 법적 환경은 자동화된 액세스일 뿐이며 누구나 그렇게 합니다 참조) )
스크래핑 및 관련 법률은 새롭고 검증되지 않은 경우가 많으며 법적 회색 영역이 많습니다. 이에 따라 모든 출처를 인용하고 속도 제한을 준수하며 불필요한 요청을 피하여 서비스에 미치는 영향을 최소화하기로 결심했습니다.
사실, 해당 데이터는 수익을 창출하는 데 사용되지 않습니다. GoodWatch는 누구나 영원히 무료로 사용할 수 있습니다.
Windmill은 작업자를 사용하여 여러 프로세스에 걸쳐 코드 실행을 분산합니다. 흐름의 각 단계는 작업자에게 전송되므로 실제 비즈니스 로직과 독립됩니다. 기본 앱만 작업을 조정하는 반면 작업자는 입력 데이터, 코드를 실행하고 결과를 반환하기만 합니다.
확장성이 뛰어난 효율적인 아키텍처입니다. 현재 12명의 작업자가 작업을 분담하고 있습니다. 모두 Hetzner에서 호스팅됩니다.
각 작업자의 최대 리소스 소비량은 vCPU 1개와 RAM 2GB입니다. 개요는 다음과 같습니다.

Windmill은 린팅, 자동 서식 지정, AI 도우미 및 심지어 협업 편집 (마지막 기능은 유료 기능입니다). 가장 좋은 점은 이 버튼입니다:
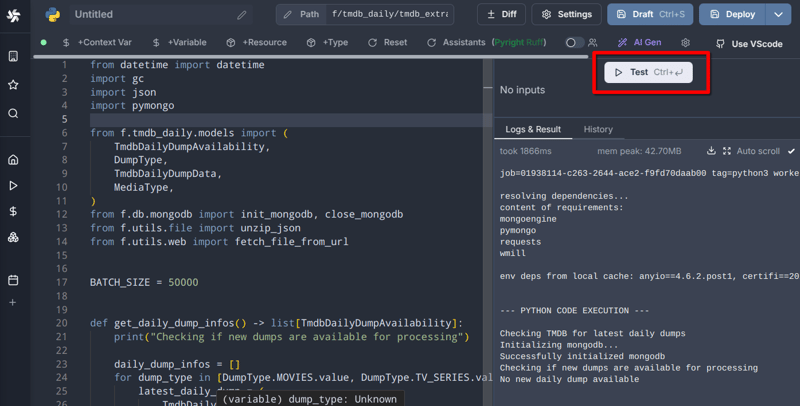
최적의 코딩 환경에 누락된 유일한 것은
디버깅 도구(중단점 및 변수 컨텍스트)입니다. 현재 저는 이 약점을 극복하기 위해 로컬 IDE에서 스크립트를 디버깅하고 있습니다.
숫자. 나는 숫자를 좋아한다현재 GoodWatch에는 약
100GB의 영구 데이터 저장소가 필요합니다.
6,500개의 흐름이 Windmill의 오케스트레이션 엔진을 통해 실행됩니다. 그 결과 일일 볼륨은 다음과 같습니다.
하루에 한 번 데이터를 정리하고 최종 데이터 형식으로 결합합니다. 현재 GoodWatch 웹앱 스토어를 지원하는 데이터베이스:
영화를 장르로만 구분할 수 있고 극히 제한적일 수 있다고 상상해 보세요.
그래서 DNA 프로젝트를 시작하게 됐어요. 분위기, 플롯 요소, 문자 유형, 대화 또는 주요 소품과 같은 다른 속성을 기준으로 영화와 프로그램을 분류할 수 있습니다. .
다음은 모든 항목에 대한 모든 DNA 값의 상위 10개입니다.

두 가지를 허용합니다:
예:
향후 더 자세한 내용을 담은 DNA 전용 블로그 게시물이 있을 예정입니다.
데이터 파이프라인의 작동 방식을 완전히 이해하기 위해 각 데이터 소스에 대해 어떤 일이 발생하는지 분석해 보겠습니다.
각 데이터 소스에는 필요한 모든 데이터가 포함된 MongoDB 컬렉션을 준비하는 ìnit 흐름이 있습니다. IMDb의 경우 imdb_id만 해당됩니다. Rotten Tomatoes의 경우 제목과 출시_연도가 필수입니다. ID를 알 수 없고, 이름을 보고 정확한 URL을 추측해야 하기 때문입니다.
위에서 설명한 우선순위 선택에 따라 준비된 컬렉션의 항목이 가져온 데이터로 업데이트됩니다. 각 데이터 소스에는 시간이 지남에 따라 점점 더 완전해지는 자체 컬렉션이 있습니다.
영화에 대한 흐름, TV 프로그램에 대한 흐름, 스트리밍 링크에 대한 흐름이 있습니다. 다양한 컬렉션에서 필요한 모든 데이터를 수집하여 해당 Postgres 테이블에 저장한 다음 웹 애플리케이션에서 쿼리합니다.
다음은 카피 무비 흐름 및 대본의 일부입니다.

이러한 흐름 중 일부는 실행하는 데 오랜 시간이 걸리며 때로는 6시간이 넘는 경우도 있습니다. 업데이트된 모든 항목에 플래그를 지정하고 전체 데이터 세트를 일괄 처리하는 대신 해당 항목만 복사하여 최적화할 수 있습니다. 내 목록에 있는 많은 TODO 항목 중 하나인가요?
자동으로 실행되어야 하는 각 흐름이나 스크립트에 대한 크론 표현식을 정의하는 것만큼 쉽게 예약할 수 있습니다.

다음은 GoodWatch에 정의된 모든 일정의 일부입니다.

총 50개 정도의 일정이 정의되어 있습니다.
훌륭한 데이터에는 큰 책임이 따릅니다. 많은 일이 잘못될 수 있습니다. 그리고 그렇게 되었습니다.
초기 버전의 스크립트에서는 컬렉션이나 테이블의 모든 항목을 업데이트하는 데 시간이 오래 걸렸습니다. 모든 항목을 개별적으로 upserted했기 때문입니다. 이로 인해 많은 오버헤드가 발생하고 프로세스 속도가 크게 느려집니다.
훨씬 더 나은 접근 방식은 업데이트할 데이터를 수집하고 데이터베이스 쿼리를 일괄 처리하는 것입니다. 다음은 MongoDB의 예입니다.
def main():
return tmdb_extract_daily_dump_data()
def tmdb_extract_daily_dump_data():
print("Checking TMDB for latest daily dumps")
init_mongodb()
daily_dump_infos = get_daily_dump_infos()
for daily_dump_info in daily_dump_infos:
download_zip_and_store_in_db(daily_dump_info)
close_mongodb()
return [info.to_mongo() for info in daily_dump_infos]
[...]
일괄 처리를 수행하더라도 일부 스크립트는 너무 많은 메모리를 소비하여 작업자가 충돌했습니다. 해결책은 모든 사용 사례에 맞게 배치 크기를 신중하게 미세 조정하는 것이었습니다.
어떤 배치는 5000단계로 실행해도 괜찮고 다른 배치는 훨씬 더 많은 데이터를 메모리에 저장하고 500단계로 더 잘 실행됩니다.
Windmill에는 스크립트가 실행되는 동안 메모리를 관찰할 수 있는 훌륭한 기능이 있습니다.

Windmill은 작업 자동화를 위한 모든 개발자 툴킷의 훌륭한 자산입니다. 작업 조정, 오류 처리, 재시도 및 캐싱과 같은 무거운 작업을 아웃소싱하는 동시에 흐름 구조와 비즈니스 논리에 집중할 수 있게 해 준 덕분에 생산성이 매우 향상되었습니다.
대량의 데이터를 처리하는 것은 여전히 어려운 일이며 파이프라인 최적화는 지속적인 과정입니다. 하지만 지금까지의 결과에 정말 만족합니다.
그렇게 생각했어요. 몇 가지 리소스를 연결하면 끝입니다.
GoodWatch가 오픈소스라는 사실을 알고 계셨나요? 이 저장소에서 모든 스크립트와 흐름 정의를 살펴볼 수 있습니다: https://github.com/alp82/goodwatch-monorepo/tree/main/goodwatch-flows/windmill/f
궁금한 점이 있으면 알려주세요.
위 내용은 수많은 영화와 수백만 개의 스트리밍 링크를 위한 데이터 파이프라인의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



