

IRIS-RAG-Gen: IRIS 벡터 검색으로 구동되는 ChatGPT RAG 애플리케이션 개인화

안녕하세요 커뮤니티 여러분,
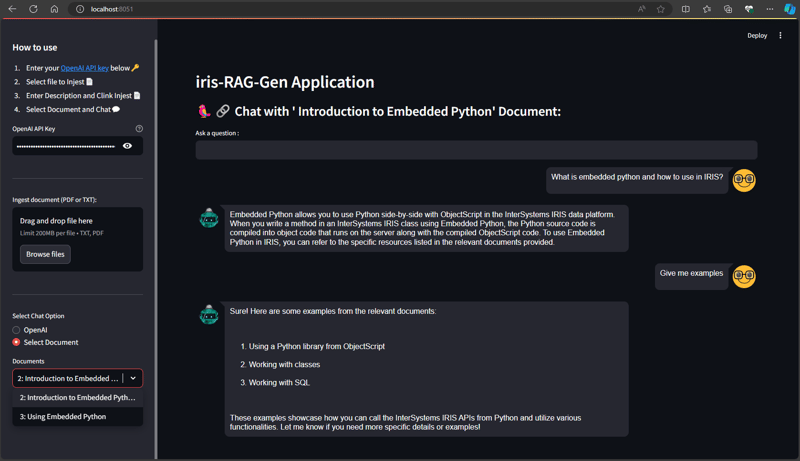
이 글에서는 제 애플리케이션인 iris-RAG-Gen을 소개하겠습니다.
Iris-RAG-Gen은 Streamlit 웹 프레임워크, LangChain 및 OpenAI의 도움으로 IRIS 벡터 검색 기능을 활용하여 ChatGPT를 개인화하는 생성형 AI RAG(검색 증강 생성) 애플리케이션입니다. 이 애플리케이션은 IRIS를 벡터 저장소로 사용합니다.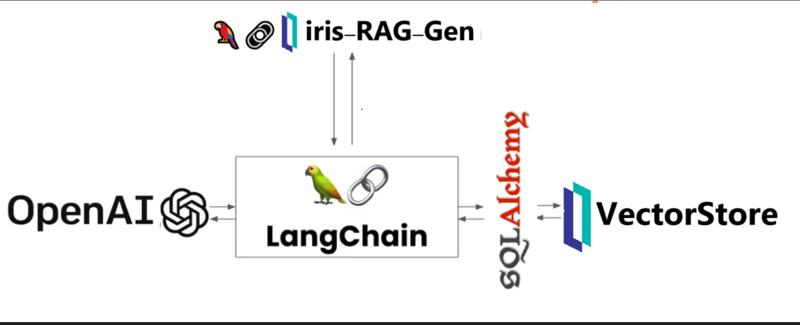
애플리케이션 기능
- 문서(PDF 또는 TXT)를 IRIS에 수집
- 선택한 처리 문서와 채팅
- 수집된 문서 삭제
- 오픈AI 챗GPT
문서(PDF 또는 TXT)를 IRIS로 수집
문서를 수집하려면 아래 단계를 따르세요.
- OpenAI 키 입력
- 문서 선택(PDF 또는 TXT)
- 문서 설명 입력
- 문서 수집 버튼을 클릭하세요
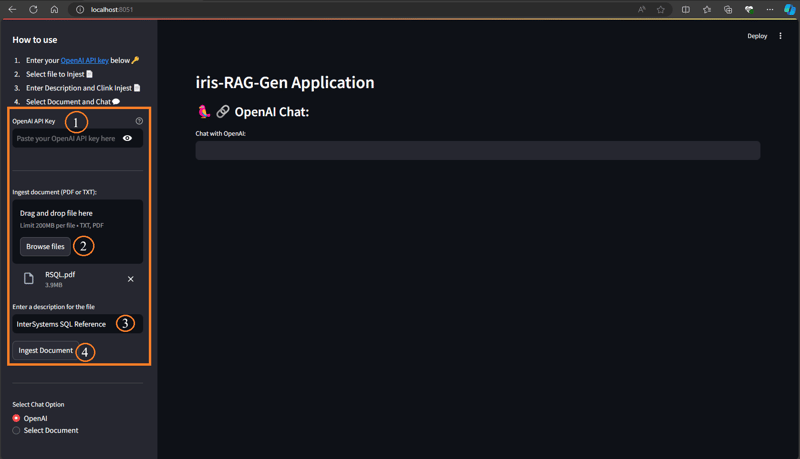
문서 수집 기능은 문서 세부정보를 rag_documents 테이블에 삽입하고 'rag_document id'(rag_documents의 ID) 테이블을 생성하여 벡터 데이터를 저장합니다.

아래 Python 코드는 선택한 문서를 벡터로 저장합니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings
from sqlalchemy import create_engine,text
<span>class RagOpr:</span>
#Ingest document. Parametres contains file path, description and file type
<span>def ingestDoc(self,filePath,fileDesc,fileType):</span>
embeddings = OpenAIEmbeddings()
#Load the document based on the file type
if fileType == "text/plain":
loader = TextLoader(filePath)
elif fileType == "application/pdf":
loader = PyPDFLoader(filePath)
#load data into documents
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
#Split text into chunks
texts = text_splitter.split_documents(documents)
#Get collection Name from rag_doucments table.
COLLECTION_NAME = self.get_collection_name(fileDesc,fileType)
# function to create collection_name table and store vector data in it.
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
#Get collection name
<span>def get_collection_name(self,fileDesc,fileType):</span>
# check if rag_documents table exists, if not then create it
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'SQLUser'
AND TABLE_NAME = 'rag_documents';
""")
result = []
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
#if table is not created, then create rag_documents table first
if len(result) == 0:
sql = text("""
CREATE TABLE rag_documents (
description VARCHAR(255),
docType VARCHAR(50) )
""")
try:
result = conn.execute(sql)
except Exception as err:
print("An exception occurred:", err)
return ''
#Insert description value
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
INSERT INTO rag_documents
(description,docType)
VALUES (:desc,:ftype)
""")
try:
result = conn.execute(sql, {'desc':fileDesc,'ftype':fileType})
except Exception as err:
print("An exception occurred:", err)
return ''
#select ID of last inserted record
sql = text("""
SELECT LAST_IDENTITY()
""")
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
return "rag_document"+str(result[0][0])벡터 데이터를 검색하려면 관리 포털에서 아래 SQL 명령을 입력하세요
SELECT top 5 id, embedding, document, metadata FROM SQLUser.rag_document2
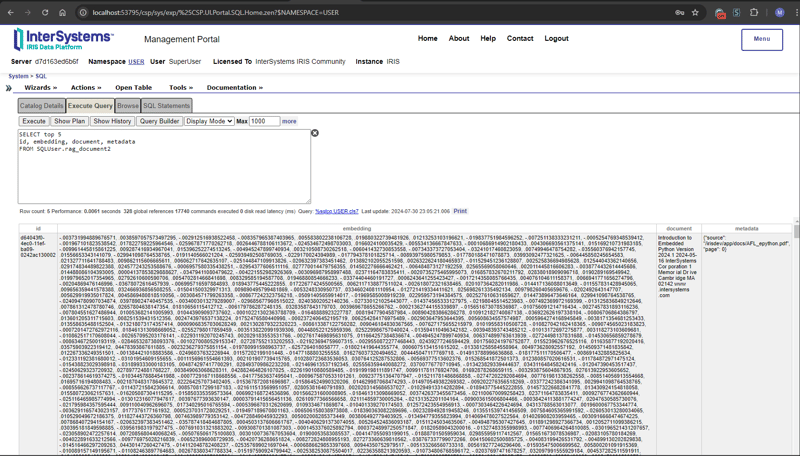
선택한 처리 문서와 채팅
채팅 옵션 선택 섹션에서 문서를 선택하고 질문을 입력하세요. 애플리케이션은 벡터 데이터를 읽고 관련 답변을 반환합니다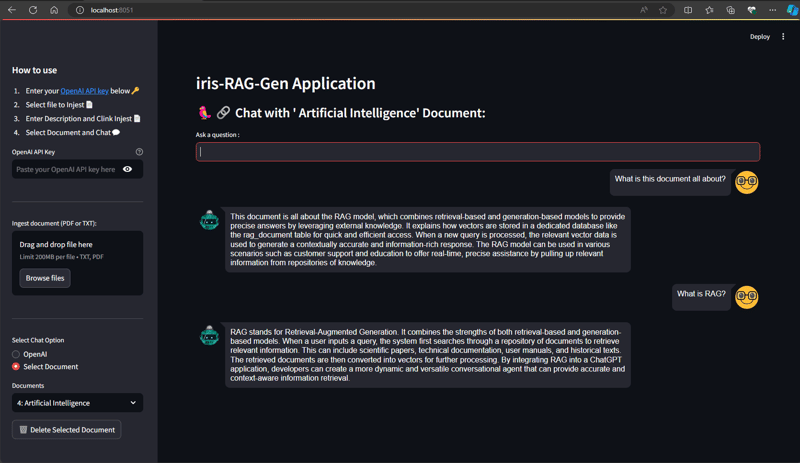
아래 Python 코드는 선택한 문서를 벡터로 저장합니다.
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings,ChatOpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationSummaryMemory
from langchain.chat_models import ChatOpenAI
<span>class RagOpr:</span>
<span>def ragSearch(self,prompt,id):</span>
#Concat document id with rag_doucment to get the collection name
COLLECTION_NAME = "rag_document"+str(id)
embeddings = OpenAIEmbeddings()
#Get vector store reference
db2 = IRISVector (
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
#Similarity search
docs_with_score = db2.similarity_search_with_score(prompt)
#Prepair the retrieved documents to pass to LLM
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
#init LLM
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo"
)
#manage and handle LangChain multi-turn conversations
conversation_sum = ConversationChain(
llm=llm,
memory= ConversationSummaryMemory(llm=llm),
verbose=False
)
#Create prompt
template = f"""
Prompt: <span>{prompt}
Relevant Docuemnts: {relevant_docs}
"""</span>
#Return the answer
resp = conversation_sum(template)
return resp['response']
자세한 내용은 iris-RAG-Gen 공개 교환 신청 페이지를 참조하세요.
감사합니다
위 내용은 IRIS-RAG-Gen: IRIS 벡터 검색으로 구동되는 ChatGPT RAG 애플리케이션 개인화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7870
7870
 15
1649
14
1407
52
1301
25
1244
29
15
1649
14
1407
52
1301
25
1244
29

 Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 보려고 할 때 Linux 터미널에서 Python 버전을 볼 때 권한 문제에 대한 솔루션 ... Python을 입력하십시오 ...
 중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?
Apr 02, 2025 am 07:15 AM
중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?
Apr 02, 2025 am 07:15 AM
Fiddlerevery Where를 사용할 때 Man-in-the-Middle Reading에 Fiddlereverywhere를 사용할 때 감지되는 방법 ...
 한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
Python의 Pandas 라이브러리를 사용할 때는 구조가 다른 두 데이터 프레임 사이에서 전체 열을 복사하는 방법이 일반적인 문제입니다. 두 개의 dats가 있다고 가정 해
 Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 HTTP 요청을 어떻게 지속적으로 듣습니까? Uvicorn은 ASGI를 기반으로 한 가벼운 웹 서버입니다. 핵심 기능 중 하나는 HTTP 요청을 듣고 진행하는 것입니다 ...
 Linux 터미널에서 Python (Version 명령)을 사용할 때 권한 문제를 해결하는 방법은 무엇입니까?
Apr 02, 2025 am 06:36 AM
Linux 터미널에서 Python (Version 명령)을 사용할 때 권한 문제를 해결하는 방법은 무엇입니까?
Apr 02, 2025 am 06:36 AM
Linux 터미널에서 Python 사용 ...

 10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?
Apr 02, 2025 am 07:18 AM
10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?
Apr 02, 2025 am 07:18 AM
10 시간 이내에 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법은 무엇입니까? 컴퓨터 초보자에게 프로그래밍 지식을 가르치는 데 10 시간 밖에 걸리지 않는다면 무엇을 가르치기로 선택 하시겠습니까?
 Inversiting.com의 크롤링 메커니즘을 우회하는 방법은 무엇입니까?
Apr 02, 2025 am 07:03 AM
Inversiting.com의 크롤링 메커니즘을 우회하는 방법은 무엇입니까?
Apr 02, 2025 am 07:03 AM
Investing.com의 크롤링 전략 이해 많은 사람들이 종종 Investing.com (https://cn.investing.com/news/latest-news)에서 뉴스 데이터를 크롤링하려고합니다.
