

Python으로 Target.com 리뷰를 긁는 방법

소개
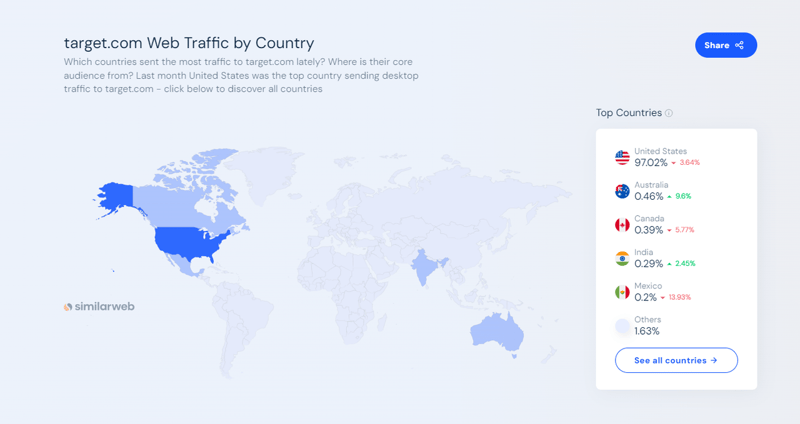
Target.com은 미국 최대의 전자상거래 및 쇼핑 마켓플레이스 중 하나입니다. 이를 통해 소비자는 식료품과 필수품부터 의류, 전자제품에 이르기까지 모든 것을 온라인과 매장에서 쇼핑할 수 있습니다. 유사한 웹의 데이터에 따르면 2024년 9월 현재 Target.com의 월간 웹 트래픽은 1억 6,600만 건이 넘습니다.
Target.com 웹사이트에서는 고객 리뷰, 동적 가격 정보, 제품 비교, 제품 평가 등을 제공합니다. 이는 제품 동향을 추적하고 경쟁업체 가격을 모니터링하거나 리뷰를 통해 고객 감정을 분석하려는 분석가, 마케팅 팀, 기업 또는 연구원을 위한 귀중한 데이터 소스입니다.
이 기사에서는 다음 방법에 대해 알아봅니다.
- 웹 스크래핑을 위한 Python, Selenium, Beautiful Soup 설정 및 설치
- Python을 사용하여 Target.com에서 제품 리뷰 및 평점 스크랩
- ScraperAPI를 사용하여 Target.com의 스크래핑 방지 메커니즘을 효과적으로 우회
- 프록시를 구현하여 IP 금지를 방지하고 스크래핑 성능을 향상하세요
이 기사를 마치면 Python, Selenium 및 ScraperAPI를 사용하여 차단되지 않고 Target.com에서 제품 리뷰 및 평점을 수집하는 방법을 배우게 됩니다. 또한 스크랩한 데이터를 감정 분석에 사용하는 방법도 배우게 됩니다.
이 튜토리얼을 작성하는 동안 흥미가 생겼다면 바로 들어가 보겠습니다. ?
TL;DR: 대상 제품 리뷰 스크랩 [전체 코드]
급한 분들을 위해 이 튜토리얼을 기반으로 구축할 전체 코드 조각은 다음과 같습니다.
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
GitHub에서 전체 코드를 확인하세요: https://github.com/Eunit99/target_com_scraper. 코드의 각 줄을 이해하고 싶으십니까? 웹 스크레이퍼를 처음부터 함께 만들어 봅시다!
Python 및 ScraperAPI를 사용하여 Target.com 리뷰를 스크랩하는 방법
이전 기사에서는 Target.com 제품 데이터를 스크랩하기 위해 알아야 할 모든 것을 다루었습니다. 하지만 이 기사에서는 Python 및 ScraperAPI를 사용하여 Target.com에서 제품 평가 및 리뷰를 스크래핑하는 방법을 안내하는 데 중점을 둘 것입니다.
전제 조건
이 튜토리얼을 따르고 Target.com 스크래핑을 시작하려면 먼저 몇 가지 작업을 수행해야 합니다.
1. ScraperAPI 계정 보유
ScraperAPI에서 무료 계정으로 시작하세요. ScraperAPI를 사용하면 웹 스크래핑을 위한 사용하기 쉬운 API를 사용하여 복잡하고 비용이 많이 드는 해결 방법 없이 수백만 개의 웹 소스에서 데이터 수집을 시작할 수 있습니다.
ScraperAPI는 가장 까다로운 사이트의 잠금을 해제하고, 인프라 및 개발 비용을 절감하며, 웹 스크래퍼를 더 빠르게 배포할 수 있게 하고, 먼저 시도해 볼 수 있는 무료 1,000 API 크레딧 등을 제공합니다.
2. 텍스트 편집기 또는 IDE
Visual Studio Code와 같은 코드 편집기를 사용하세요. 다른 옵션으로는 Sublime Text 또는 PyCharm
이 있습니다.3. 프로젝트 요구 사항 및 가상 환경 설정
Target.com 리뷰 스크랩을 시작하기 전에 다음 사항을 확인하세요.
- 컴퓨터에 설치된 Python(버전 3.10 이상)
- pip(Python 패키지 설치 프로그램)
Python 프로젝트에 가상 환경을 사용하여 종속성을 관리하고 충돌을 피하는 것이 가장 좋습니다.
가상 환경을 만들려면 터미널에서 다음 명령을 실행하세요.
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
4. 가상 환경 활성화
운영 체제에 따라 가상 환경을 활성화하세요.
python3 -m venv env
일부 IDE는 가상 환경을 자동으로 활성화할 수 있습니다.
5. CSS 선택기와 브라우저 DevTools 탐색에 대한 기본적인 이해가 있어야 합니다.
이 기사를 효과적으로 따르려면 CSS 선택기에 대한 기본적인 이해가 필수적입니다. CSS 선택기는 웹페이지의 특정 HTML 요소를 대상으로 지정하는 데 사용되며 이를 통해 필요한 정보를 추출할 수 있습니다.
또한 웹페이지 구조를 검사하고 식별하려면 브라우저 DevTools에 익숙해지는 것이 중요합니다.
프로젝트 설정
위의 전제 조건을 충족했다면 이제 프로젝트를 설정할 차례입니다. Target.com 스크레이퍼의 소스 코드를 포함할 폴더를 만드는 것부터 시작하세요. 이 경우 폴더 이름을 python-target-dot-com-scraper로 지정합니다.
다음 명령을 실행하여 python-target-dot-com-scraper라는 폴더를 만듭니다.
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
폴더에 들어가서 다음 명령을 실행하여 새 Python main.py 파일을 만듭니다.
mkdir python-target-dot-com-scraper
다음 명령을 실행하여 요구 사항.txt 파일을 만듭니다.
cd python-target-dot-com-scraper && touch main.py
이 기사에서는 Selenium과 Beautiful Soup, Webdriver Manager for Python 라이브러리를 사용하여 웹 스크레이퍼를 구축하겠습니다. Selenium은 브라우저 자동화를 처리하고 Beautiful Soup 라이브러리는 Target.com 웹 사이트의 HTML 콘텐츠에서 데이터를 추출합니다. 동시에 Python용 Webdriver Manager는 다양한 브라우저의 드라이버를 자동으로 관리하는 방법을 제공합니다.
필요한 패키지를 지정하려면 요구사항.txt 파일에 다음 줄을 추가하세요.
touch requirements.txt
패키지를 설치하려면 다음 명령을 실행하세요.
selenium~=4.25.0 bs4~=0.0.2 python-dotenv~=1.0.1 webdriver_manager selenium-wire blinker==1.7.0 python-dotenv==1.0.1
Selenium으로 Target.com 제품 리뷰 추출
이 섹션에서는 Target.com의 이와 같은 제품 페이지에서 제품 평가 및 리뷰를 얻는 방법에 대한 단계별 가이드를 안내하겠습니다.
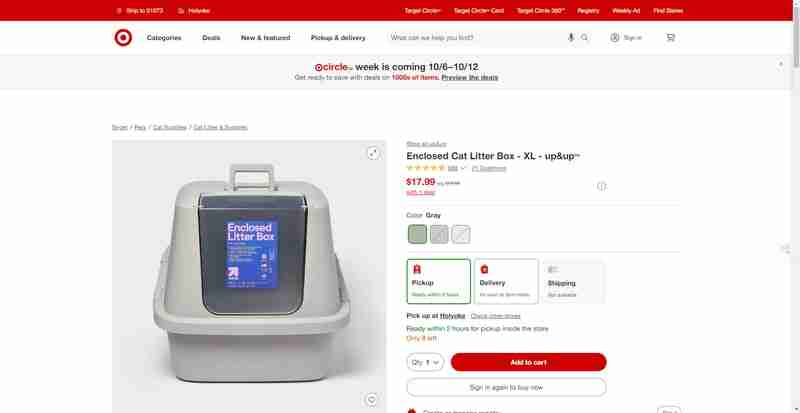
아래 스크린샷에 강조 표시된 웹사이트 섹션의 리뷰와 평점에 중점을 두겠습니다.
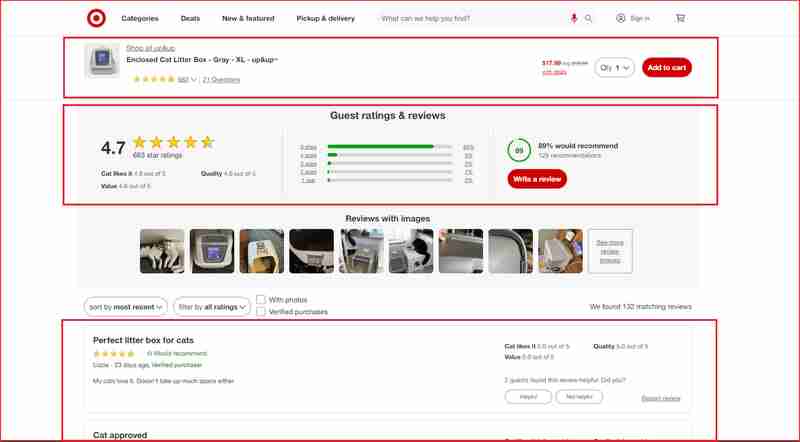
더 자세히 알아보기 전에 HTML 구조를 이해하고 추출하려는 정보를 래핑하는 HTML 태그와 연결된 DOM 선택기를 식별해야 합니다. 다음 섹션에서는 Chrome DevTools를 사용하여 Target.com의 사이트 구조를 이해하는 과정을 안내하겠습니다.
Chrome DevTools를 사용하여 Target.com의 사이트 구조 이해
F12 키를 누르거나 페이지 아무 곳이나 마우스 오른쪽 버튼으로 클릭하고 검사를 선택하여 Chrome DevTools를 엽니다. 위 URL에서 페이지를 검사하면 다음 내용이 드러납니다.
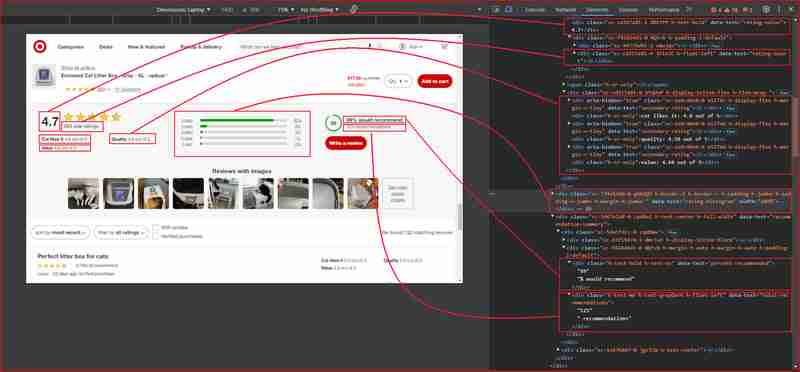
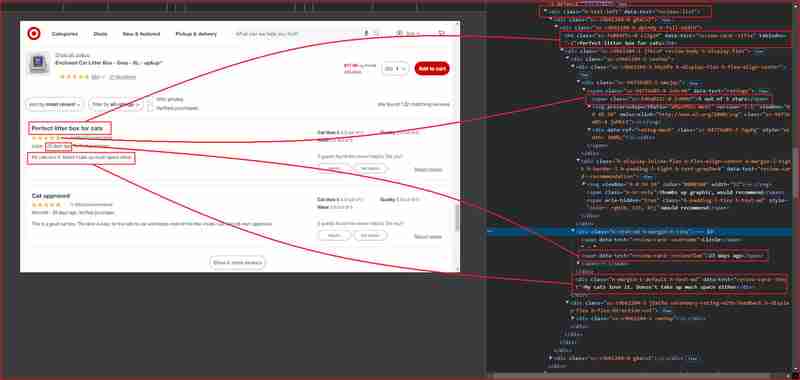
위 사진에서 웹 스크래퍼가 정보를 추출하기 위해 대상으로 삼는 모든 DOM 선택기는 다음과 같습니다.
| Information | DOM selector | Value |
|---|---|---|
| Product ratings | ||
| Rating value | div[data-test='rating-value'] | 4.7 |
| Rating count | div[data-test='rating-count'] | 683 star ratings |
| Secondary rating | div[data-test='secondary-rating'] | 683 star ratings |
| Rating histogram | div[data-test='rating-histogram'] | 5 stars 85%4 stars 8%3 stars 3%2 stars 1%1 star 2% |
| Percent recommended | div[data-test='percent-recommended'] | 89% would recommend |
| Total recommendations | div[data-test='total-recommendations'] | 125 recommendations |
| Product reviews | ||
| Reviews list | div[data-test='reviews-list'] | Returns children elements corresponding to individual product review |
| Review card title | h4[data-test='review-card--title'] | Perfect litter box for cats |
| Ratings | span[data-test='ratings'] | 4.7 out of 5 stars with 683 reviews |
| Review time | span[data-test='review-card--reviewTime'] | 23 days ago |
| Review card text | div[data-test='review-card--text'] | My cats love it. Doesn't take up much space either |
타겟 리뷰 스크레이퍼 구축
이제 모든 요구 사항을 설명하고 Target.com 제품 리뷰 페이지에서 관심 있는 다양한 요소를 찾았습니다. 필요한 모듈을 가져오는 다음 단계로 넘어갑니다.
1. 셀레늄 및 기타 모듈 가져오기
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
이 코드에서 각 모듈은 웹 스크래퍼를 구축하기 위한 특정 목적을 수행합니다.
- os는 API 키와 같은 환경 변수를 처리합니다.
- 시간이 지나면 페이지 로딩이 지연됩니다.
- dotenv는 .env 파일에서 API 키를 로드합니다.
- Selenium은 브라우저 자동화 및 상호 작용을 가능하게 합니다.
- webdriver_manager는 ChromeDriver를 자동으로 설치합니다.
- BeautifulSoup은 데이터 추출을 위해 HTML을 구문 분석합니다.
- seleniumwire는 IP 금지 없이 스크래핑을 위한 프록시를 관리합니다.
2. 웹 드라이버 설정
이 단계에서는 Selenium의 Chrome WebDriver를 초기화하고 중요한 브라우저 옵션을 구성합니다. 이러한 옵션에는 성능 향상을 위한 불필요한 기능 비활성화, 창 크기 설정 및 로그 관리가 포함됩니다. webdriver.Chrome()을 사용하여 WebDriver를 인스턴스화하여 스크래핑 프로세스 전반에 걸쳐 브라우저를 제어합니다.
python3 -m venv env
아래로 스크롤 기능 만들기
이 섹션에서는 전체 페이지를 스크롤하는 기능을 만듭니다. Target.com 웹사이트는 사용자가 아래로 스크롤할 때 추가 콘텐츠(예: 리뷰)를 동적으로 로드합니다.
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
scroll_down_page() 함수는 각 스크롤 사이에 짧은 일시정지(지연)를 두고 설정된 픽셀 수(거리)만큼 웹페이지를 점진적으로 스크롤합니다. 먼저 페이지의 전체 높이를 계산하고 맨 아래에 도달할 때까지 아래로 스크롤합니다. 스크롤하면서 총 페이지 높이가 동적으로 업데이트되어 프로세스 중에 로드될 수 있는 새 콘텐츠를 수용할 수 있습니다.
셀레늄과 BeautifulSoup의 결합
이 섹션에서는 Selenium과 BeautifulSoup의 장점을 결합하여 효율적이고 안정적인 웹 스크래핑 설정을 만듭니다. Selenium은 페이지 로드 및 JavaScript 렌더링 요소 처리와 같은 동적 콘텐츠와 상호 작용하는 데 사용되는 반면, BeautifulSoup은 정적 HTML 요소를 구문 분석하고 추출하는 데 더 효과적입니다. 먼저 Selenium을 사용하여 웹페이지를 탐색하고 제품 평가 및 리뷰 수와 같은 특정 요소가 로드될 때까지 기다립니다. 이러한 요소는 Selenium의 WebDriverWait 기능으로 추출되어 데이터를 캡처하기 전에 데이터가 표시되도록 합니다. 하지만 Selenium만으로는 개별 리뷰를 처리하는 것이 복잡하고 비효율적일 수 있습니다.
BeautifulSoup을 사용하여 페이지의 여러 리뷰를 반복하는 프로세스를 단순화했습니다. Selenium이 페이지를 완전히 로드하면 BeautifulSoup는 HTML 콘텐츠를 구문 분석하여 리뷰를 효율적으로 추출합니다. BeautifulSoup의 select() 및 select_one() 메소드를 사용하여 페이지 구조를 탐색하고 각 리뷰에 대한 제목, 평가, 시간 및 텍스트를 수집할 수 있습니다. 이 접근 방식을 사용하면 반복되는 요소(예: 리뷰 목록)를 더 깔끔하고 구조적으로 스크래핑할 수 있으며 Selenium만 사용하여 모든 것을 관리하는 것에 비해 HTML 처리에 더 큰 유연성을 제공합니다.
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Python Selenium에서 프록시 사용: 헤드리스 브라우저와의 복잡한 상호 작용
복잡한 웹사이트, 특히 Target.com과 같은 강력한 봇 방지 조치를 갖춘 웹사이트를 스크랩할 때 IP 금지, 속도 제한 또는 액세스 제한과 같은 문제가 발생하는 경우가 많습니다. 이러한 작업에 Selenium을 사용하는 것은 특히 헤드리스 브라우저를 배포할 때 복잡해집니다. 헤드리스 브라우저는 GUI 없이 상호 작용을 허용하지만 이 환경에서 수동으로 프록시를 관리하는 것은 어렵습니다. 프록시 설정을 구성하고, IP를 순환하고, JavaScript 렌더링과 같은 기타 상호 작용을 처리해야 하므로 스크래핑 속도가 느려지고 오류가 발생하기 쉽습니다.
반대로 ScraperAPI는 프록시를 자동으로 관리하여 이 프로세스를 크게 간소화합니다. Selenium에서 수동 구성을 처리하는 대신 ScraperAPI의 프록시 모드는 여러 IP 주소에 요청을 분산시켜 IP 금지, 속도 제한 또는 지리적 제한에 대한 걱정 없이 원활한 스크래핑을 보장합니다. 이는 동적 콘텐츠와 복잡한 사이트 상호 작용을 처리하기 위해 추가 코딩이 필요한 헤드리스 브라우저로 작업할 때 특히 유용합니다.
Selenium으로 ScraperAPI 설정
ScraperAPI의 프록시 모드를 Selenium과 통합하는 것은 쉬운 프록시 구성을 가능하게 하는 도구인 Selenium Wire를 사용하여 단순화됩니다. 빠른 설정은 다음과 같습니다.
- ScraperAPI에 가입: 계정을 만들고 API 키를 검색하세요.
- Selenium Wire 설치: pip install selenium-wire를 실행하여 표준 Selenium을 Selenium Wire로 교체합니다.
- 프록시 구성: WebDriver 설정에서 ScraperAPI의 프록시 풀을 사용하여 IP 순환을 손쉽게 관리하세요.
이 구성을 통합하면 헤드리스 브라우저 환경에서 수동으로 프록시를 관리해야 하는 번거로움 없이 동적 페이지, 자동 회전 IP 주소, 속도 제한 우회와의 원활한 상호 작용이 가능해집니다.
아래 스니펫은 Python에서 ScraperAPI의 프록시를 구성하는 방법을 보여줍니다.
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
이 설정을 사용하면 ScraperAPI 프록시 서버로 전송된 요청이 Target.com 웹 사이트로 리디렉션되어 실제 IP가 숨겨지고 Target.com 웹 사이트 스크래핑 방지 메커니즘에 대한 강력한 방어가 제공됩니다. JavaScript 렌더링을 위해 render=true와 같은 매개변수를 포함하거나 위치정보를 위해 country_code를 지정하여 프록시를 사용자 정의할 수도 있습니다.
Target.com에서 스크랩한 리뷰 데이터
아래 JSON 코드는 Target Reviews Scraper를 사용한 응답 샘플입니다.
python3 -m venv env
Cloud Target.com 리뷰 스크레이퍼를 사용하는 방법
환경을 설정하거나 코딩 방법을 모르거나 프록시를 설정하지 않고도 Target.com 리뷰를 빠르게 얻으려면 Target Scraper API를 사용하여 필요한 데이터를 무료로 얻을 수 있습니다. Target Scraper API는 Apify 플랫폼에서 호스팅되며 별도의 설정 없이 바로 사용할 수 있습니다.
지금 시작하려면 Apify로 이동하여 "무료로 사용해 보기"를 클릭하세요.

감정 분석을 위한 대상 검토 사용
이제 Target.com 리뷰 및 평점 데이터가 있으므로 이 데이터를 이해해야 합니다. 이러한 리뷰 및 평가 데이터는 특정 제품이나 서비스에 대한 고객의 의견에 대한 귀중한 통찰력을 제공할 수 있습니다. 이러한 리뷰를 분석하면 일반적인 칭찬과 불만 사항을 파악하고, 고객 만족도를 측정하고, 향후 행동을 예측하고, 이러한 리뷰를 실행 가능한 통찰력으로 전환할 수 있습니다.
주요 고객을 더 잘 이해하고 마케팅 및 제품 전략을 개선할 방법을 모색하는 마케팅 전문가 또는 사업주로서. 다음은 이 데이터를 실행 가능한 통찰력으로 변환하여 마케팅 활동을 최적화하고, 제품 전략을 개선하고, 고객 참여를 높일 수 있는 몇 가지 방법입니다.
- 제품 개선: 일반적인 고객 불만 사항이나 칭찬을 파악하여 제품 기능을 미세 조정합니다.
- 고객 서비스 개선: 부정적인 리뷰를 조기에 감지하여 문제를 해결하고 고객 만족도를 유지합니다.
- 마케팅 캠페인 최적화: 긍정적인 피드백에서 얻은 통찰력을 활용하여 개인화되고 타겟팅된 캠페인을 만듭니다.
ScraperAPI를 사용하여 대규모 리뷰 데이터를 대규모로 수집하면 감정 분석을 자동화하고 확장하여 더 나은 의사결정과 성장을 지원할 수 있습니다.
스크래핑 타겟 제품 리뷰에 대한 FAQ
Target.com 제품 페이지를 긁는 것이 합법적입니까?
예, 제품 평가, 리뷰 등 공개적으로 사용 가능한 정보를 얻기 위해 Target.com을 이용하는 것은 합법입니다. 하지만 이러한 공개 정보에는 여전히 개인 정보가 포함될 수 있다는 점을 기억하는 것이 중요합니다.
저희는 웹 스크래핑의 법적 측면과 윤리적 고려사항에 대한 블로그 게시물을 작성했습니다. 자세한 내용은 여기에서 확인하세요.
Target.com은 스크레이퍼를 차단합니까?
예, Target.com은 자동 스크레이퍼를 차단하기 위해 다양한 스크래핑 방지 조치를 구현합니다. 여기에는 IP 차단, 속도 제한, CAPTCHA 챌린지가 포함되며 모두 스크레이퍼나 봇의 과도한 자동 요청을 감지하고 중지하도록 설계되었습니다.
Target.com에 의해 차단되는 것을 어떻게 방지합니까?
Target.com의 차단을 피하려면 요청 속도를 늦추고, 사용자 에이전트를 교체하고, CAPTCHA 해결 기술을 사용하고, 반복적이거나 빈도가 높은 요청을 피해야 합니다. 이러한 방법을 프록시와 결합하면 탐지 가능성을 줄이는 데 도움이 될 수 있습니다.
또한 이러한 Target.com 제한 사항을 우회하려면 Target Scraper API 또는 Scraping API와 같은 전용 스크레이퍼를 사용하는 것도 고려해 보세요.
Target.com을 스크랩하려면 프록시를 사용해야 합니까?
예, Target.com을 효과적으로 스크랩하려면 프록시를 사용하는 것이 필수적입니다. 프록시는 여러 IP 주소에 요청을 분산시켜 차단 가능성을 최소화하는 데 도움이 됩니다. ScraperAPI 프록시는 귀하의 IP를 숨기므로 스크래핑 방지 시스템이 귀하의 활동을 감지하기가 더 어려워집니다.
마무리
이 기사에서는 Python, Selenium을 사용하여 Target.com 등급 및 리뷰 스크레이퍼를 구축하고 ScraperAPI를 사용하여 Target.com의 스크래핑 방지 메커니즘을 효과적으로 우회하고 IP 금지를 방지하고 스크래핑 성능을 향상시키는 방법을 배웠습니다.
이 도구를 사용하면 귀중한 고객 피드백을 효율적이고 안정적으로 수집할 수 있습니다.
이 데이터를 수집한 후 다음 단계는 감정 분석을 사용하여 주요 통찰력을 찾는 것입니다. 고객 리뷰를 분석함으로써 기업은 제품의 강점을 파악하고 문제점을 해결하며 마케팅 전략을 최적화하여 고객 요구 사항을 더욱 효과적으로 충족할 수 있습니다.
대규모 데이터 수집을 위해 Target Scraper API를 사용하면 리뷰를 지속적으로 모니터링하고 고객 감정을 한발 앞서 이해할 수 있으므로 제품 개발을 개선하고 보다 타겟화된 마케팅 캠페인을 만들 수 있습니다.
지금 ScraperAPI를 사용해 원활하게 대규모 데이터를 추출하거나 Cloud Target.com 리뷰 Scraper를 사용해 보세요!
더 많은 튜토리얼과 훌륭한 콘텐츠를 보려면 Twitter(X) @eunit99를 팔로우하세요
위 내용은 Python으로 Target.com 리뷰를 긁는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Python vs. C : 학습 곡선 및 사용 편의성
Apr 19, 2025 am 12:20 AM
Python vs. C : 학습 곡선 및 사용 편의성
Apr 19, 2025 am 12:20 AM
Python은 배우고 사용하기 쉽고 C는 더 강력하지만 복잡합니다. 1. Python Syntax는 간결하며 초보자에게 적합합니다. 동적 타이핑 및 자동 메모리 관리를 사용하면 사용하기 쉽지만 런타임 오류가 발생할 수 있습니다. 2.C는 고성능 응용 프로그램에 적합한 저수준 제어 및 고급 기능을 제공하지만 학습 임계 값이 높고 수동 메모리 및 유형 안전 관리가 필요합니다.
 Python 학습 : 2 시간의 일일 연구가 충분합니까?
Apr 18, 2025 am 12:22 AM
Python 학습 : 2 시간의 일일 연구가 충분합니까?
Apr 18, 2025 am 12:22 AM
하루에 2 시간 동안 파이썬을 배우는 것으로 충분합니까? 목표와 학습 방법에 따라 다릅니다. 1) 명확한 학습 계획을 개발, 2) 적절한 학습 자원 및 방법을 선택하고 3) 실습 연습 및 검토 및 통합 연습 및 검토 및 통합,이 기간 동안 Python의 기본 지식과 고급 기능을 점차적으로 마스터 할 수 있습니다.
 Python vs. C : 성능과 효율성 탐색
Apr 18, 2025 am 12:20 AM
Python vs. C : 성능과 효율성 탐색
Apr 18, 2025 am 12:20 AM
Python은 개발 효율에서 C보다 낫지 만 C는 실행 성능이 높습니다. 1. Python의 간결한 구문 및 풍부한 라이브러리는 개발 효율성을 향상시킵니다. 2.C의 컴파일 유형 특성 및 하드웨어 제어는 실행 성능을 향상시킵니다. 선택할 때는 프로젝트 요구에 따라 개발 속도 및 실행 효율성을 평가해야합니다.
 Python vs. C : 주요 차이점 이해
Apr 21, 2025 am 12:18 AM
Python vs. C : 주요 차이점 이해
Apr 21, 2025 am 12:18 AM
Python과 C는 각각 고유 한 장점이 있으며 선택은 프로젝트 요구 사항을 기반으로해야합니다. 1) Python은 간결한 구문 및 동적 타이핑으로 인해 빠른 개발 및 데이터 처리에 적합합니다. 2) C는 정적 타이핑 및 수동 메모리 관리로 인해 고성능 및 시스템 프로그래밍에 적합합니다.
 Python Standard Library의 일부는 무엇입니까? 목록 또는 배열은 무엇입니까?
Apr 27, 2025 am 12:03 AM
Python Standard Library의 일부는 무엇입니까? 목록 또는 배열은 무엇입니까?
Apr 27, 2025 am 12:03 AM
Pythonlistsarepartoftsandardlardlibrary, whileraysarenot.listsarebuilt-in, 다재다능하고, 수집 할 수있는 반면, arraysarreprovidedByTearRaymoduledlesscommonlyusedDuetolimitedFunctionality.
 파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬은 자동화, 스크립팅 및 작업 관리가 탁월합니다. 1) 자동화 : 파일 백업은 OS 및 Shutil과 같은 표준 라이브러리를 통해 실현됩니다. 2) 스크립트 쓰기 : PSUTIL 라이브러리를 사용하여 시스템 리소스를 모니터링합니다. 3) 작업 관리 : 일정 라이브러리를 사용하여 작업을 예약하십시오. Python의 사용 편의성과 풍부한 라이브러리 지원으로 인해 이러한 영역에서 선호하는 도구가됩니다.
 과학 컴퓨팅을위한 파이썬 : 상세한 모양
Apr 19, 2025 am 12:15 AM
과학 컴퓨팅을위한 파이썬 : 상세한 모양
Apr 19, 2025 am 12:15 AM
과학 컴퓨팅에서 Python의 응용 프로그램에는 데이터 분석, 머신 러닝, 수치 시뮬레이션 및 시각화가 포함됩니다. 1.numpy는 효율적인 다차원 배열 및 수학적 함수를 제공합니다. 2. Scipy는 Numpy 기능을 확장하고 최적화 및 선형 대수 도구를 제공합니다. 3. 팬더는 데이터 처리 및 분석에 사용됩니다. 4. matplotlib는 다양한 그래프와 시각적 결과를 생성하는 데 사용됩니다.
 웹 개발을위한 파이썬 : 주요 응용 프로그램
Apr 18, 2025 am 12:20 AM
웹 개발을위한 파이썬 : 주요 응용 프로그램
Apr 18, 2025 am 12:20 AM
웹 개발에서 Python의 주요 응용 프로그램에는 Django 및 Flask 프레임 워크 사용, API 개발, 데이터 분석 및 시각화, 머신 러닝 및 AI 및 성능 최적화가 포함됩니다. 1. Django 및 Flask 프레임 워크 : Django는 복잡한 응용 분야의 빠른 개발에 적합하며 플라스크는 소형 또는 고도로 맞춤형 프로젝트에 적합합니다. 2. API 개발 : Flask 또는 DjangorestFramework를 사용하여 RESTFULAPI를 구축하십시오. 3. 데이터 분석 및 시각화 : Python을 사용하여 데이터를 처리하고 웹 인터페이스를 통해 표시합니다. 4. 머신 러닝 및 AI : 파이썬은 지능형 웹 애플리케이션을 구축하는 데 사용됩니다. 5. 성능 최적화 : 비동기 프로그래밍, 캐싱 및 코드를 통해 최적화
