
Python과 Beautiful Soup으로 웹 스크래핑의 힘 활용: MIDI 음악 예
인터넷은 정보의 보고이지만 전용 API가 없으면 프로그래밍 방식으로 인터넷에 액세스하는 것이 어려울 수 있습니다. Python의 Beautiful Soup 라이브러리는 웹 페이지에서 직접 데이터를 스크랩하고 구문 분석할 수 있는 강력한 솔루션을 제공합니다.
MIDI 데이터를 스크랩하여 클래식 Nintendo 스타일 음악을 생성하기 위한 Magenta 신경망을 훈련함으로써 이에 대해 살펴보겠습니다. VGM(비디오 게임 음악 아카이브)에서 MIDI 파일을 소스로 제공합니다.
환경 설정
Python 3 및 pip가 설치되어 있는지 확인하세요. 종속성을 설치하기 전에 가상 환경을 생성하고 활성화하는 것이 중요합니다.
pip install requests==2.22.0 beautifulsoup4==4.8.1
뷰티플수프 4를 사용하고 있습니다(뷰티풀수프 3는 더 이상 유지되지 않습니다).
요청과 아름다운 수프를 사용한 스크래핑 및 구문 분석
먼저 HTML을 가져와 BeautifulSoup 객체를 생성해 보겠습니다.
import requests from bs4 import BeautifulSoup vgm_url = 'https://www.vgmusic.com/music/console/nintendo/nes/' html_text = requests.get(vgm_url).text soup = BeautifulSoup(html_text, 'html.parser')
soup 개체를 사용하면 HTML을 탐색할 수 있습니다. soup.title은 페이지 제목을 제공합니다. print(soup.get_text()) 모든 텍스트를 표시합니다.
아름다운 수프의 힘을 마스터하세요
find() 및 find_all() 메소드가 필수적입니다. soup.find()는 단일 요소를 타겟팅합니다(예: soup.find(id='banner_ad').text는 배너 광고 텍스트를 가져옴). soup.find_all() 여러 요소를 반복합니다. 예를 들어 다음은 모든 하이퍼링크 URL을 인쇄합니다.
for link in soup.find_all('a'):
print(link.get('href'))find_all()은 정확한 필터링을 위해 정규 표현식이나 태그 속성과 같은 인수를 허용합니다. 고급 기능은 Beautiful Soup 문서를 참조하세요.
HTML 탐색 및 구문 분석
파싱 코드를 작성하기 전에 브라우저에서 렌더링된 HTML을 검사하세요. 각 웹페이지는 고유합니다. 데이터 추출에는 창의성과 실험이 필요한 경우가 많습니다.

우리의 목표는 중복 및 리믹스를 제외한 고유한 MIDI 파일을 다운로드하는 것입니다. 브라우저 개발자 도구(마우스 오른쪽 버튼 클릭, "검사")는 프로그래밍 방식으로 액세스할 HTML 요소를 식별하는 데 도움이 됩니다.
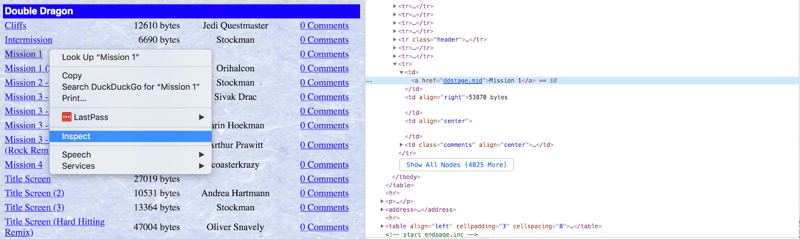
정규식과 함께 find_all()을 사용하여 MIDI 파일이 포함된 링크를 필터링해 보겠습니다(이름에 괄호가 있는 링크 제외).
만들기 nes_midi_scraper.py:
import re
import requests
from bs4 import BeautifulSoup
vgm_url = 'https://www.vgmusic.com/music/console/nintendo/nes/'
html_text = requests.get(vgm_url).text
soup = BeautifulSoup(html_text, 'html.parser')
if __name__ == '__main__':
attrs = {'href': re.compile(r'\.mid$')}
tracks = soup.find_all('a', attrs=attrs, string=re.compile(r'^((?!\().)*$'))
count = 0
for track in tracks:
print(track)
count += 1
print(len(tracks))MIDI 파일을 필터링하고 링크 태그를 인쇄하며 총 개수를 표시합니다. python nes_midi_scraper.py으로 실행하세요.
MIDI 파일 다운로드
이제 필터링된 MIDI 파일을 다운로드해 보겠습니다. download_track에 nes_midi_scraper.py 기능을 추가하세요:
pip install requests==2.22.0 beautifulsoup4==4.8.1
이 기능은 각 트랙을 다운로드하여 고유한 파일 이름으로 저장합니다. 원하는 저장 디렉토리에서 스크립트를 실행하십시오. 약 2230개의 MIDI 파일을 다운로드해야 합니다(웹사이트의 현재 콘텐츠에 따라 다름).

웹의 잠재력 탐구
웹 스크래핑을 통해 방대한 데이터세트를 접할 수 있습니다. 웹페이지 변경으로 인해 코드가 손상될 수 있다는 점을 기억하세요. 스크립트를 최신 상태로 유지하세요. Mido(MIDI 데이터 처리용) 및 Magenta(신경망 훈련용)와 같은 라이브러리를 사용하여 이 기반을 구축하세요.
위 내용은 Beautiful Soup을 사용하여 Python에서 웹 스크래핑 및 HTML 구문 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



