

vev, litellm 및 Agenta를 사용하여 AI 코드 검토 도우미 구축

이 튜토리얼에서는 LLMOps 모범 사례를 사용하여 프로덕션에 즉시 사용 가능한 AI 끌어오기 요청 검토기를 구축하는 방법을 보여줍니다. 여기에서 액세스할 수 있는 최종 애플리케이션은 공개 PR URL을 수락하고 AI 생성 리뷰를 반환합니다.
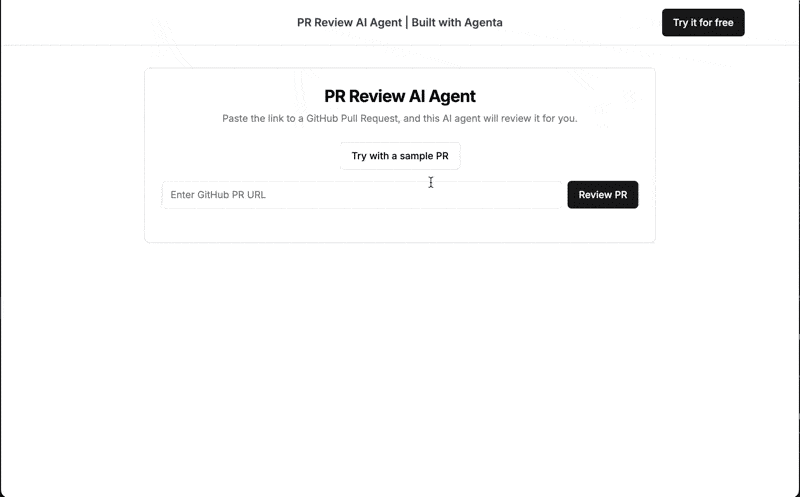
신청 개요
이 튜토리얼에서는 다음 내용을 다룹니다.
- 코드 개발: GitHub에서 PR 차이점을 검색하고 LLM 상호 작용을 위해 LiteLLM을 활용합니다.
- 관찰성: 애플리케이션 모니터링 및 디버깅을 위한 Agenta 구현
- 프롬프트 엔지니어링: Agenta의 플레이그라운드를 사용하여 프롬프트 및 모델 선택을 반복합니다.
- LLM 평가: 신속한 모델 평가를 위해 LLM을 판사로 채용합니다.
- 배포: v0.dev를 사용하여 애플리케이션을 API로 배포하고 간단한 UI를 생성합니다.
핵심 로직
AI 어시스턴트의 워크플로는 간단합니다. PR URL이 주어지면 GitHub에서 차이점을 검색하여 검토를 위해 LLM에 제출합니다.
GitHub diff는 다음을 통해 액세스할 수 있습니다.
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>이 Python 함수는 diff를 가져옵니다.
def get_pr_diff(pr_url):
# ... (Code remains the same)
return response.textLiteLLM은 LLM 상호 작용을 촉진하여 다양한 제공자 간에 일관된 인터페이스를 제공합니다.
prompt_system = """
You are an expert Python developer performing a file-by-file review of a pull request. You have access to the full diff of the file to understand the overall context and structure. However, focus on reviewing only the specific hunk provided.
"""
prompt_user = """
Here is the diff for the file:
{diff}
Please provide a critique of the changes made in this file.
"""
def generate_critique(pr_url: str):
diff = get_pr_diff(pr_url)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.contentAgenta로 관찰성 구현
Agenta는 관찰 가능성을 향상하고 입력, 출력 및 데이터 흐름을 추적하여 더 쉽게 디버깅할 수 있도록 합니다.
Agenta 초기화 및 LiteLLM 콜백 구성:
import agenta as ag ag.init() litellm.callbacks = [ag.callbacks.litellm_handler()]
Agenta 데코레이터를 사용한 도구 기능:
@ag.instrument()
def generate_critique(pr_url: str):
# ... (Code remains the same)
return response.choices[0].message.contentAGENTA_API_KEY 환경 변수(Agenta에서 가져옴)를 설정하고 선택적으로 자체 호스팅을 위해 AGENTA_HOST를 설정합니다.

LLM 놀이터 만들기
Agenta의 사용자 정의 워크플로 기능은 반복 개발을 위한 IDE와 유사한 놀이터를 제공합니다. 다음 코드 조각은 Agenta와의 구성 및 통합을 보여줍니다.
from pydantic import BaseModel, Field
from typing import Annotated
import agenta as ag
import litellm
from agenta.sdk.assets import supported_llm_models
# ... (previous code)
class Config(BaseModel):
system_prompt: str = prompt_system
user_prompt: str = prompt_user
model: Annotated[str, ag.MultipleChoice(choices=supported_llm_models)] = Field(default="gpt-3.5-turbo")
@ag.route("/", config_schema=Config)
@ag.instrument()
def generate_critique(pr_url:str):
diff = get_pr_diff(pr_url)
config = ag.ConfigManager.get_from_route(schema=Config)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.contentAgenta를 통한 서비스 제공 및 평가
- 앱 이름과 API 키를 지정하여
agenta init실행 - 달려
agenta variant serve app.py.
이렇게 하면 엔드투엔드 테스트를 위해 Agenta의 플레이그라운드를 통해 애플리케이션에 액세스할 수 있습니다. 평가에는 LLM 판사가 사용됩니다. 평가자 프롬프트는 다음과 같습니다.
<code>You are an evaluator grading the quality of a PR review. CRITERIA: ... (criteria remain the same) ANSWER ONLY THE SCORE. DO NOT USE MARKDOWN. DO NOT PROVIDE ANYTHING OTHER THAN THE NUMBER</code>
평가자를 위한 사용자 프롬프트:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>
배포 및 프런트엔드
Agenta의 UI를 통해 배포가 수행됩니다.
- 개요 페이지로 이동하세요.
- 선택한 변형 옆에 있는 세 개의 점을 클릭하세요.
- "프로덕션에 배포"를 선택합니다.

빠른 UI 생성을 위해 v0.dev 프런트엔드가 사용되었습니다.
다음 단계 및 결론
향후 개선 사항에는 신속한 개선, 전체 코드 컨텍스트 통합, 대규모 차이 처리 등이 포함됩니다. 이 튜토리얼에서는 Agenta 및 LiteLLM을 사용하여 프로덕션에 즉시 사용 가능한 AI 끌어오기 요청 검토기를 구축, 평가 및 배포하는 방법을 성공적으로 보여줍니다.

위 내용은 vev, litellm 및 Agenta를 사용하여 AI 코드 검토 도우미 구축의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Python vs. C : 학습 곡선 및 사용 편의성
Apr 19, 2025 am 12:20 AM
Python vs. C : 학습 곡선 및 사용 편의성
Apr 19, 2025 am 12:20 AM
Python은 배우고 사용하기 쉽고 C는 더 강력하지만 복잡합니다. 1. Python Syntax는 간결하며 초보자에게 적합합니다. 동적 타이핑 및 자동 메모리 관리를 사용하면 사용하기 쉽지만 런타임 오류가 발생할 수 있습니다. 2.C는 고성능 응용 프로그램에 적합한 저수준 제어 및 고급 기능을 제공하지만 학습 임계 값이 높고 수동 메모리 및 유형 안전 관리가 필요합니다.
 파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
제한된 시간에 Python 학습 효율을 극대화하려면 Python의 DateTime, Time 및 Schedule 모듈을 사용할 수 있습니다. 1. DateTime 모듈은 학습 시간을 기록하고 계획하는 데 사용됩니다. 2. 시간 모듈은 학습과 휴식 시간을 설정하는 데 도움이됩니다. 3. 일정 모듈은 주간 학습 작업을 자동으로 배열합니다.
 Python vs. C : 성능과 효율성 탐색
Apr 18, 2025 am 12:20 AM
Python vs. C : 성능과 효율성 탐색
Apr 18, 2025 am 12:20 AM
Python은 개발 효율에서 C보다 낫지 만 C는 실행 성능이 높습니다. 1. Python의 간결한 구문 및 풍부한 라이브러리는 개발 효율성을 향상시킵니다. 2.C의 컴파일 유형 특성 및 하드웨어 제어는 실행 성능을 향상시킵니다. 선택할 때는 프로젝트 요구에 따라 개발 속도 및 실행 효율성을 평가해야합니다.
 Python 학습 : 2 시간의 일일 연구가 충분합니까?
Apr 18, 2025 am 12:22 AM
Python 학습 : 2 시간의 일일 연구가 충분합니까?
Apr 18, 2025 am 12:22 AM
하루에 2 시간 동안 파이썬을 배우는 것으로 충분합니까? 목표와 학습 방법에 따라 다릅니다. 1) 명확한 학습 계획을 개발, 2) 적절한 학습 자원 및 방법을 선택하고 3) 실습 연습 및 검토 및 통합 연습 및 검토 및 통합,이 기간 동안 Python의 기본 지식과 고급 기능을 점차적으로 마스터 할 수 있습니다.
 Python Standard Library의 일부는 무엇입니까? 목록 또는 배열은 무엇입니까?
Apr 27, 2025 am 12:03 AM
Python Standard Library의 일부는 무엇입니까? 목록 또는 배열은 무엇입니까?
Apr 27, 2025 am 12:03 AM
Pythonlistsarepartoftsandardlardlibrary, whileraysarenot.listsarebuilt-in, 다재다능하고, 수집 할 수있는 반면, arraysarreprovidedByTearRaymoduledlesscommonlyusedDuetolimitedFunctionality.
 Python vs. C : 주요 차이점 이해
Apr 21, 2025 am 12:18 AM
Python vs. C : 주요 차이점 이해
Apr 21, 2025 am 12:18 AM
Python과 C는 각각 고유 한 장점이 있으며 선택은 프로젝트 요구 사항을 기반으로해야합니다. 1) Python은 간결한 구문 및 동적 타이핑으로 인해 빠른 개발 및 데이터 처리에 적합합니다. 2) C는 정적 타이핑 및 수동 메모리 관리로 인해 고성능 및 시스템 프로그래밍에 적합합니다.
 파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬은 자동화, 스크립팅 및 작업 관리가 탁월합니다. 1) 자동화 : 파일 백업은 OS 및 Shutil과 같은 표준 라이브러리를 통해 실현됩니다. 2) 스크립트 쓰기 : PSUTIL 라이브러리를 사용하여 시스템 리소스를 모니터링합니다. 3) 작업 관리 : 일정 라이브러리를 사용하여 작업을 예약하십시오. Python의 사용 편의성과 풍부한 라이브러리 지원으로 인해 이러한 영역에서 선호하는 도구가됩니다.
 웹 개발을위한 파이썬 : 주요 응용 프로그램
Apr 18, 2025 am 12:20 AM
웹 개발을위한 파이썬 : 주요 응용 프로그램
Apr 18, 2025 am 12:20 AM
웹 개발에서 Python의 주요 응용 프로그램에는 Django 및 Flask 프레임 워크 사용, API 개발, 데이터 분석 및 시각화, 머신 러닝 및 AI 및 성능 최적화가 포함됩니다. 1. Django 및 Flask 프레임 워크 : Django는 복잡한 응용 분야의 빠른 개발에 적합하며 플라스크는 소형 또는 고도로 맞춤형 프로젝트에 적합합니다. 2. API 개발 : Flask 또는 DjangorestFramework를 사용하여 RESTFULAPI를 구축하십시오. 3. 데이터 분석 및 시각화 : Python을 사용하여 데이터를 처리하고 웹 인터페이스를 통해 표시합니다. 4. 머신 러닝 및 AI : 파이썬은 지능형 웹 애플리케이션을 구축하는 데 사용됩니다. 5. 성능 최적화 : 비동기 프로그래밍, 캐싱 및 코드를 통해 최적화
