
이 자습서에서는 간단한 영화 데이터 세트를 사용하여 NoSQL용 Azure Cosmos DB에서 벡터 검색을 빠르게 구현하는 방법을 보여줍니다. 이 애플리케이션은 Python, TypeScript, .NET 및 Java로 제공되며 설정, 데이터 로드 및 유사성 검색 쿼리에 대한 단계별 지침을 제공합니다.
벡터 데이터베이스는 데이터의 고차원 수학적 표현인 벡터 임베딩을 저장하고 관리하는 데 탁월합니다. 각 차원은 데이터 특성을 반영하며 잠재적으로 수만 개에 달할 수 있습니다. 이 공간에서 벡터의 위치는 그 특성을 나타냅니다. 이 기술은 단어, 구문, 문서, 이미지, 오디오를 포함한 다양한 데이터 유형을 벡터화하여 유사성 검색, 다중 모드 검색, 추천 엔진, 대규모 언어 모델(LLM)과 같은 애플리케이션을 가능하게 합니다.
전제 조건:
text-embedding-ada-002 Azure OpenAI 서비스 리소스입니다(Azure AI Foundry 포털을 통해 액세스 가능). 이 모델은 텍스트 임베딩을 제공합니다.NoSQL용 Azure Cosmos DB에서 벡터 데이터베이스 구성:
기능 활성화: 이 단계는 일회성 단계입니다. Azure Cosmos DB 내에서 벡터 인덱싱 및 검색을 명시적으로 활성화합니다.

데이터베이스 및 컨테이너 생성: movies_db 파티션 키를 사용하여 데이터베이스(예: movies)와 컨테이너(예: /id)를 생성합니다.
정책 생성: 컨테이너에 대한 벡터 삽입 정책과 인덱싱 정책을 구성합니다. 이 예에서는 아래에 표시된 설정을 사용합니다. 여기에서는 Azure Portal을 통한 수동 구성이 사용되지만 프로그래밍 방식도 사용할 수 있습니다.
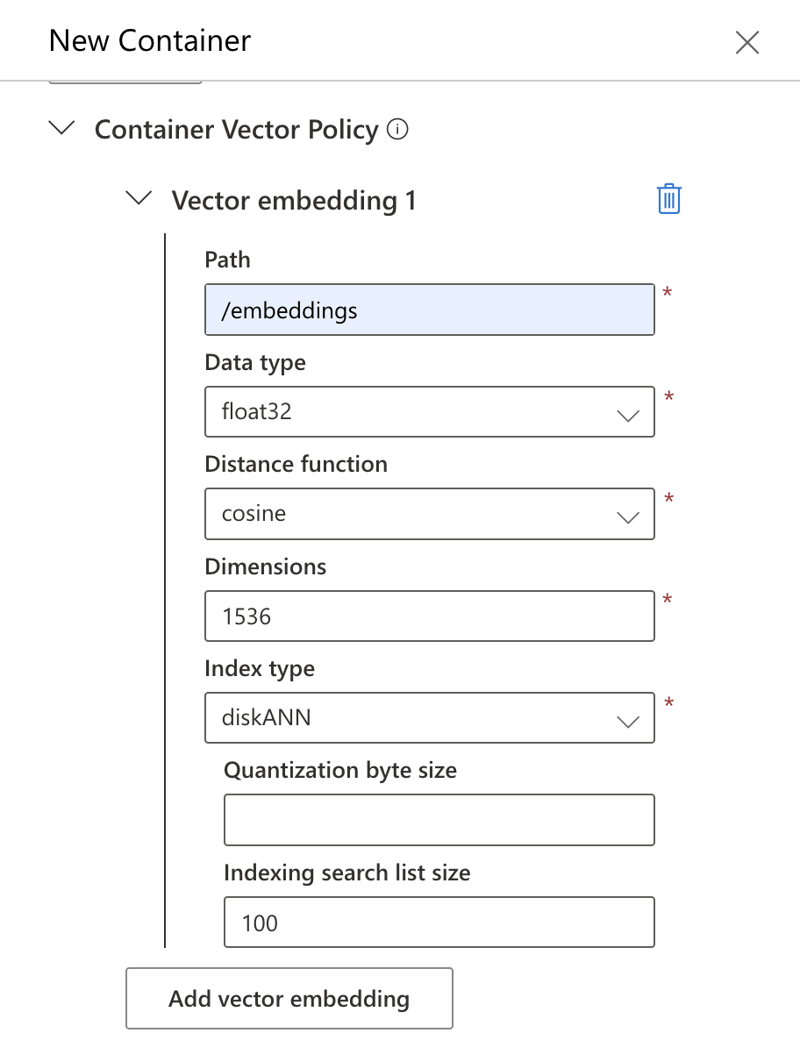
인덱스 유형 참고: 이 예에서는 diskANN 모델과 일치하는 차원이 1536인 text-embedding-ada-002 인덱스 유형을 사용합니다. 적응 가능하지만 인덱스 유형을 변경하려면 임베딩 모델을 새로운 차원에 맞게 조정해야 합니다.
Azure Cosmos DB에 데이터 로드:
샘플 movies.json 파일은 영화 데이터를 제공합니다. 프로세스에는 다음이 포함됩니다.
typeScript :
export COSMOS_DB_CONNECTION_STRING="" export DATABASE_NAME="" export CONTAINER_NAME="" export AZURE_OPENAI_ENDPOINT="" export AZURE_OPENAI_KEY="" export AZURE_OPENAI_VERSION="2024-10-21" export EMBEDDINGS_MODEL="text-embedding-ada-002"
<🎜 🎜> <🎜 🎜> <<> .NET :
git clone https://github.com/abhirockzz/cosmosdb-vector-search-python-typescript-java-dotnet cd cosmosdb-vector-search-python-typescript-java-dotnet
Azure Cosmos db에서 데이터 확인 :
cd python; python3 -m venv .venv; source .venv/bin/activate; pip install -r requirements.txt; python load.py
cd typescript; npm install; npm run build; npm run load Python : cd java; mvn clean install; java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar load cd dotnet; dotnet restore; dotnet run load 닫는 노트 :
위 내용은 Azure Cosmos DB에서 벡터 검색 시작하기의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



