chain 는 각 청크의 관련성을 평가하기 위해 Grader LLM을 안내하는 프롬프트로 그레이더 체인을 초기화합니다. _grade 문서 노드는 각 청크를 분석하여 질문과 관련이 있는지 여부를 결정합니다. 각 청크에 대해, 청크가 질문과 관련이 있는지 여부에 따라 " 예 "또는 " 아니오 "을 출력합니다.
웹 및 하이브리드 검색
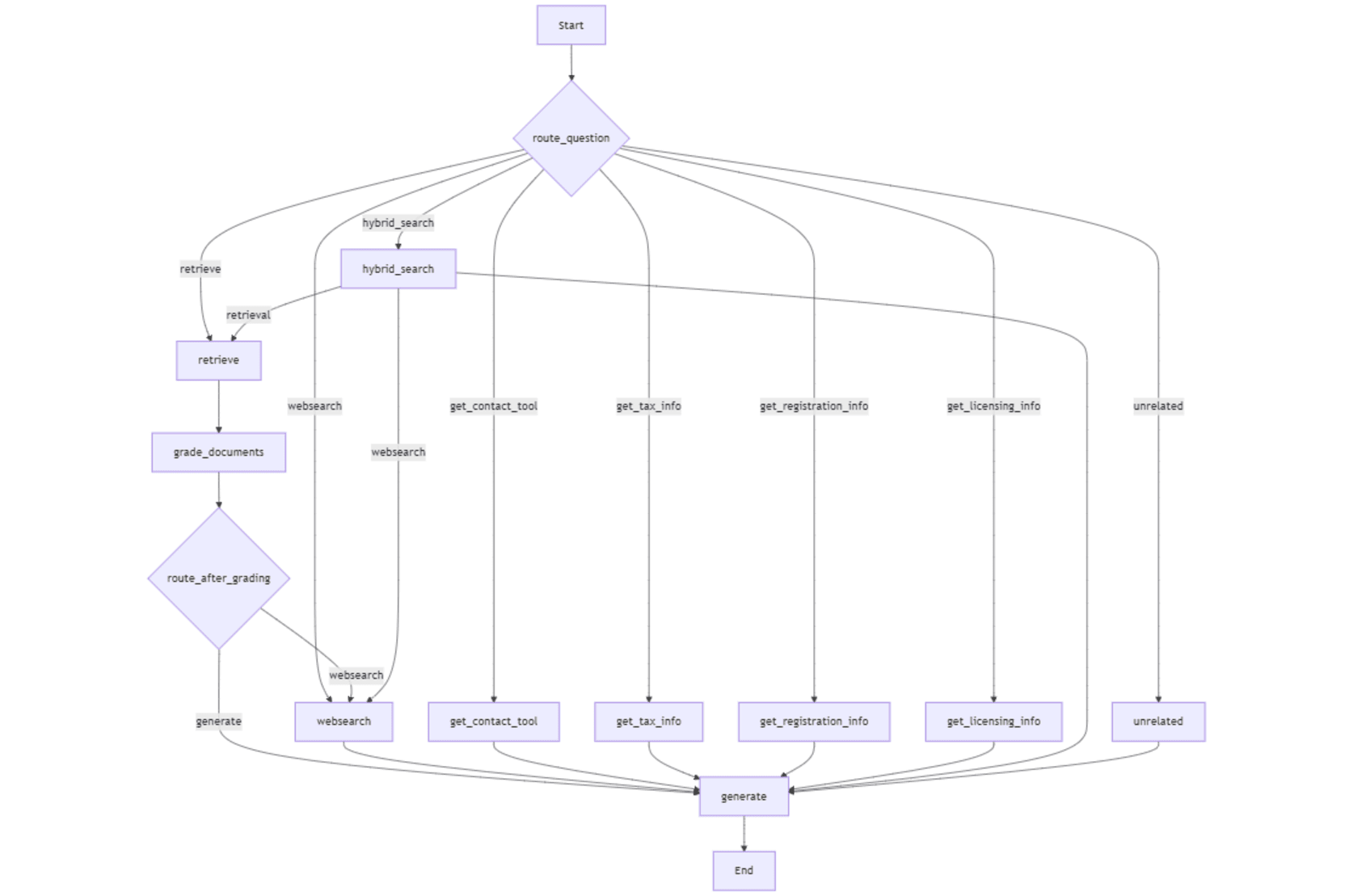
검색 노드는 검색된 정보에서 관련 덩어리가 발견되지 않거나 _route Question node에 의해 직접 관련된 덩어리가 발견되지 않을 때 _route_after 노드에 의해 도달합니다. _internet_search enabled State Flag는 " true "입니다 (선택됨 사용자 인터페이스의 라디오 버튼) 또는 라우터 함수는 쿼리를 _web 검색으로 라우팅하기로 결정합니다.
Tavily Search Engine의 무료 API는 웹 사이트에서 계정을 작성하여 얻을 수 있습니다. 무료 계획은 한 달에 1000 개의 신용 포인트를 제공합니다. Tavily Search 결과는 상태 변수 " document "에 추가 된 다음 상태 변수 " Question ".
하이브리드 검색은 리트리버와 Tavily 검색 및 채워진 " document "상태 변수의 결과를 결합합니다.
도구 호출
이 에이전트 워크 플로에 사용 된 도구는 사전 정의 된 신뢰할 수있는 URL에서 정보를 가져 오는 스크래핑 기능입니다. Tavily와 이러한 도구의 차이점은 Tavily가 다양한 인터넷 검색을 수행하여 다양한 소스의 결과를 가져 오는 것입니다. 반면,이 도구는 Python의 아름다운 수프 웹 스크래핑 라이브러리를 사용하여 신뢰할 수있는 소스 (사전 정의 된 URL)에서 정보를 추출합니다. 이런 식으로, 우리는 특정 쿼리에 관한 정보가 알려진 신뢰할 수있는 소스에서 추출되도록합니다. 또한이 정보 검색은 완전히 자유 롭습니다
여기 _get_tax info 노드가 일부 도우미 함수와 함께 작동하는 방법은 다음과 같습니다. 이 유형의 다른 도구 (노드)도 같은 방식으로 작동합니다. You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
로그인 후 복사
로그인 후 복사
로그인 후 복사
앱을 통해 모델 또는 상태 변수가 변경 될 때마다 __가 트리거됩니다. 구성 요소를 다시 구분하고 업데이트 된 상태를 저장합니다. 이 기능은 또한 다양한 세션 변수를 추적하고 중복 초기화를 방지합니다.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)로그인 후 복사
로그인 후 복사
목록 는 노드를 생성하여 모델을 동적으로 전환하는 동안 모델을 추적하는 데 사용됩니다.
워크 플로 설정
이제 _route question 를 사용하는 그래프 상태, 노드, 조건부 진입 지점이며, 노드 사이의 흐름을 설정하기 위해 가장자리가 정의됩니다. 마지막으로, 워크 플로는 lemelit 인터페이스 내에서 사용하기 위해 실행 파일 app 로 컴파일됩니다. 워크 플로의 조건 입력 점은 _route question 함수를 사용하여 쿼리를 기반으로 워크 플로에서 첫 번째 노드를 선택합니다. 조건부 가장자리 (_workflow.add_conditional edges )는 websearch 로 전환 할 것인지 노드를 생성 할 것인지 _grade 에 기초하여 노드를 생성할지 여부를 설명합니다. 문서 노드. You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
로그인 후 복사
로그인 후 복사
로그인 후 복사
의 간소화 응용 프로그램은 모델 선택, 답변 스타일 및 쿼리 별 도구에 동적 설정을 사용하여 질문과 응답을 표시하는 대화식 인터페이스를 제공합니다. _Initialize rag.py에서 가져온 _initialize
app 함수는 _agentic rag.py, 에서 가져옵니다. 모든 LLM, 임베딩 모델 및 왼쪽 사이드 바에서 선택한 기타 옵션을 포함한 모든 세션 변수를 초기화합니다.
sys.stdout 를 io.stringio 버퍼로 리디렉션하여 캡처됩니다. 그런 다음이 버퍼의 내용은 _text area 구성 요소를 사용하여 디버그 자리 표시기에 표시됩니다.
다음은 Streamlit 인터페이스의 스냅 샷입니다
다음 이미지는 에 의해 생성 된 답변을 보여줍니다. 쿼리 라우터 (_route question )는 리트리버 (벡터 검색)를 호출하고 그레이더 기능은 검색된 모든 청크를 관련으로 찾습니다. 따라서 생성을 통해 답을 생성하기로 한 결정은 노드 노드.
다음 이미지는‘ explanatory 프롬프트 에 지시받은 것처럼, LLM은 더 많은 설명으로 답을 자세히 설명합니다.
다음 이미지는 라우터 트리거링 _get_license
info import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)로그인 후 복사
로그인 후 복사
다음 이미지는 벡터 검색에서 관련 청크가 없을 때 _route_after
노드에 의해 호출 된 웹 검색을 보여줍니다.
 다음 이미지는 sleamlit
다음 이미지는 sleamlit 응용 프로그램에서 선택한 하이브리드 검색 옵션으로 생성 된 응답을 보여줍니다. _route Qustion 노드는 _internet_search enabled 상태 플래그‘ true ’을 찾아 _hybrid 노드 를 찾습니다.
확장 방향
이 응용 프로그램은 여러 방향으로 향상 될 수 있습니다
여러 언어 (예 : 러시아어, 에스토니아, 아랍어 등)의 음성 지원 검색 및 질문 답변
응답의 다른 부분을 선택하고 더 많은 정보 나 설명을 요청합니다.
마지막 메시지 수의 메모리 추가
다른 양식 (예 : 이미지)을 포함하여 답변
브레인 스토밍, 글쓰기 및 아이디어 생성에 더 많은 에이전트를 추가합니다
-
그게 모두입니다! -
기사가 마음에 들면 기사를 박수 치고 (여러 번 - ? ) 댓글을 작성하고 Medium and LinkedIn에서 저를 따르십시오.



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



