코딩을위한 대형 언어 모델 (LLM)의 빠르게 진화하는 환경은 개발자에게 풍부한 선택을 제공합니다. 이 분석은 Humaneval 및 실제 ELO 점수와 같은 벤치 마크에서 측정 한 코딩 능력에 중점을 둔 공개 API를 통해 액세스 할 수있는 최고 LLM을 비교합니다. 개인 프로젝트를 구축하든 AI를 워크 플로우에 통합하든, 이러한 모델의 강점과 약점을 이해하는 것은 정보에 입각 한 의사 결정에 중요합니다. .
LLM 비교의 도전 :
직접 비교는 빈번한 모델 업데이트 (사소한 모델조차도 성능에 크게 영향을 미치기 때문에), LLM의 고유 한 확률 력으로 인해 일관성이없는 결과를 초래하고 벤치 마크 설계 및보고의 잠재적 편견으로 인해 어렵습니다. 이 분석은 현재 사용 가능한 데이터를 기반으로 한 최상의 비교를 나타냅니다.
평가 지표 : Humaneval 및 Elo 점수 :
이 분석은 두 가지 주요 메트릭을 사용합니다 :
Humaneval : 주어진 요구 사항을 기반으로 코드 정확성 및 기능을 평가하는 벤치 마크. 코드 완료 및 문제 해결 능력을 측정합니다
ELO 점수 (Chatbot Arena-Coding 만 해당) : 인간이 판단한 헤드 투 헤드 LLM 비교에서 파생 된. ELO 점수가 높을수록 상대적인 성능이 우수하다는 것을 나타냅니다. 100 포인트 차이는 고급 모델의 ~ 64% 승리율을 나타냅니다.
성능 개요 :
OpenAi의 모델은 HumaneVal과 Elo 순위를 지속적으로 최고로, 우수한 코딩 기능을 보여줍니다. o1-mini
모델은 놀랍게도 두 메트릭에서 더 큰 o1 - 모델보다 성능이 뛰어납니다. 다른 회사의 최고의 모델은 Openai의 후행이지만 비슷한 성능을 보여줍니다.
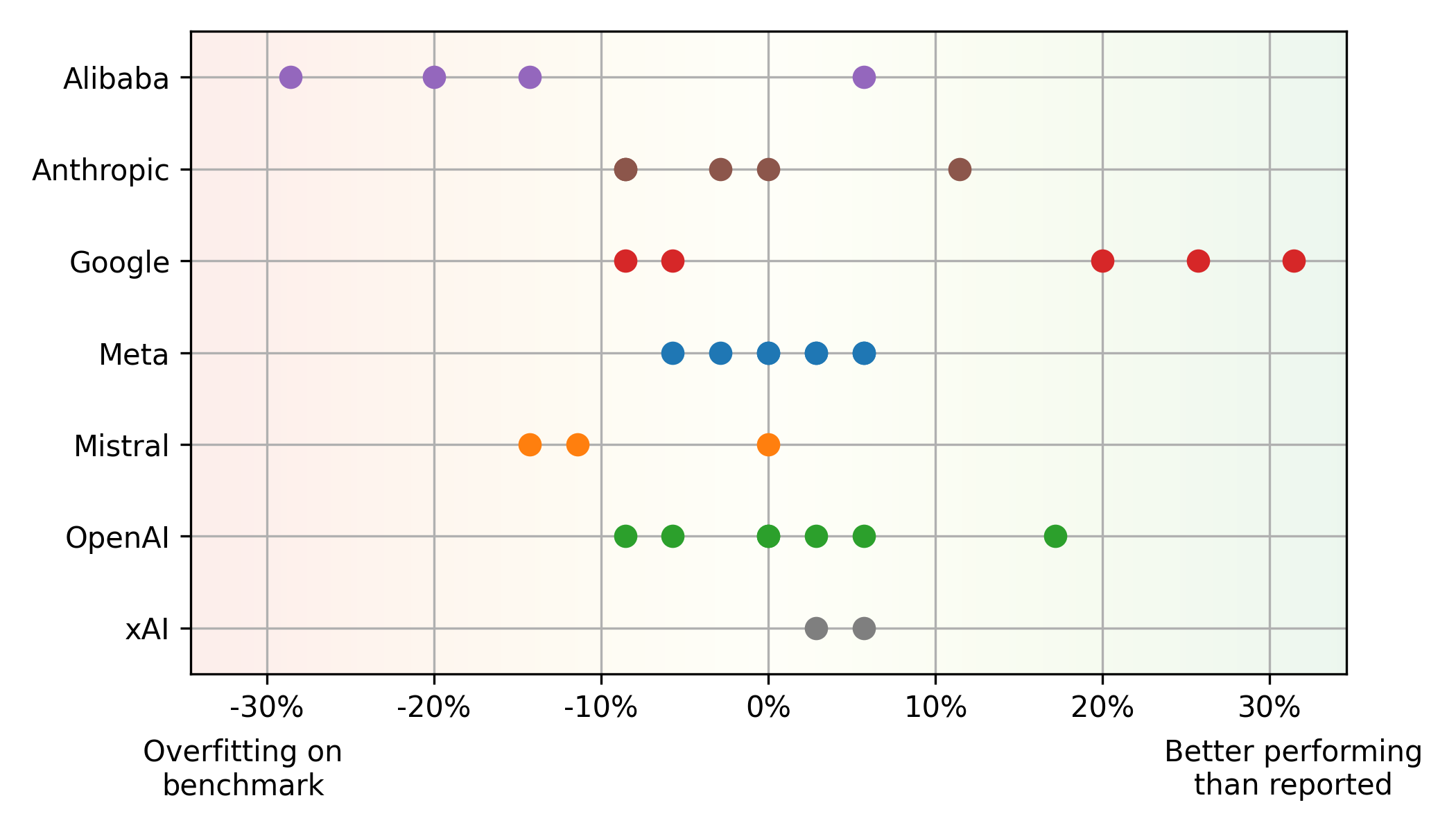
- 벤치 마크 vs. 실제 성능 불일치 :
Humaneval과 ELO 점수 사이에는 상당한 불일치가 존재합니다. Mistral의 mistral large 와 같은 일부 모델은 실제 사용량 (잠재적 인 피적)보다 Humaneval에서 더 잘 수행되는 반면, Google의 와 같은 다른 모델은 반대 트렌드를 보여줍니다 ( 벤치 마크의 과소 평가). 이것은 전적으로 벤치 마크에 의존하는 한계를 강조합니다. Alibaba 및 Mistral 모델은 종종 벤치 마크를 과적 해지는 반면, Google의 모델은 공정한 평가에 중점을 두어 과소 평가 된 것으로 보입니다. 메타 모델은 벤치 마크와 실제 성능 사이의 일관된 균형을 보여줍니다. 
균형 균형 성능과 가격 :
Pareto Front (최적의 성능 및 가격 균형)에는 주로 OpenAi (고성능) 및 Google (value for Money) 모델이 있습니다. 클라우드 제공 업체 평균을 기준으로 가격이 책정 된 Meta의 오픈 소스 라마 모델도 경쟁 가치를 보여줍니다.
추가 통찰력 :
LLMS는 지속적으로 성능을 향상시키고 비용 감소. 오픈 소스 모델은 따라 가고 있지만 독점 모델은 지배력을 유지합니다. 사소한 업데이트조차도 성능 및/또는 가격에 큰 영향을 미칩니다
결론 :
코딩 LLM 환경은 역동적입니다. 개발자는 성능과 비용을 모두 고려하여 최신 모델을 정기적으로 평가해야합니다. 벤치 마크의 한계를 이해하고 다양한 평가 메트릭을 우선 순위를 정하는 것은 정보에 입각 한 선택을하는 데 중요합니다. 이 분석은 현재 상태의 스냅 샷을 제공하며,이 빠르게 진화하는 필드에서 앞서 나가려면 지속적인 모니터링이 필수적입니다.
.
위 내용은 2024 년 코딩을위한 LLMS : 가격, 성과 및 최고를위한 전투의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 추가 통찰력 :
추가 통찰력 : 

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



