
이 기사는 새로운 양식에 적응하는 것 (코드 생성에 대한 코덱스의 적응)에 적응하고 (InstructGPT에 의해 입증 된 바와 같이) 모델을 인간 선호도와 정렬하는 두 가지 주요 미세 조정 과제를 강조합니다. 둘 다 데이터 수집, 모델 아키텍처, 객관적인 기능 및 평가 지표를 신중하게 고려해야합니다.
Codex : 코드 생성을위한 미세 조정  이 기사는 코드 생성을 평가하기위한 Bleu 점수와 같은 전통적인 메트릭의 부적합성을 강조합니다. "기능적 정확성"과 pass@k
이 기사는 코드 생성을 평가하기위한 Bleu 점수와 같은 전통적인 메트릭의 부적합성을 강조합니다. "기능적 정확성"과 pass@k
.
instructgpt and chatgpt : 인간 선호도와 정렬
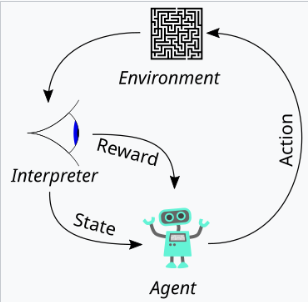
이 기사는 정렬을 도움, 정직 및 무해함을 나타내는 모델로 정의합니다. 이러한 특성이 어떻게 지시 다음, 환각율 및 편견/독성과 같은 측정 가능한 측면으로 변환되는지 설명합니다. 인간 피드백 (RLHF)의 강화 학습을 사용하는 것은 세 가지 단계를 설명하는데, 즉 인간 피드백 수집, 보상 모델 교육 및 PPO (Proximal Policy Optimization)를 사용하여 정책 최적화라는 세 가지 단계를 간략하게 설명합니다. 이 기사는 인간 피드백 수집 프로세스에서 데이터 품질 관리의 중요성을 강조합니다. 결과를 보여주는 결과는 instructgpt의 개선 된 정렬, 환각 감소 및 성능 회귀 완화가 제시됩니다.
요약 및 모범 사례 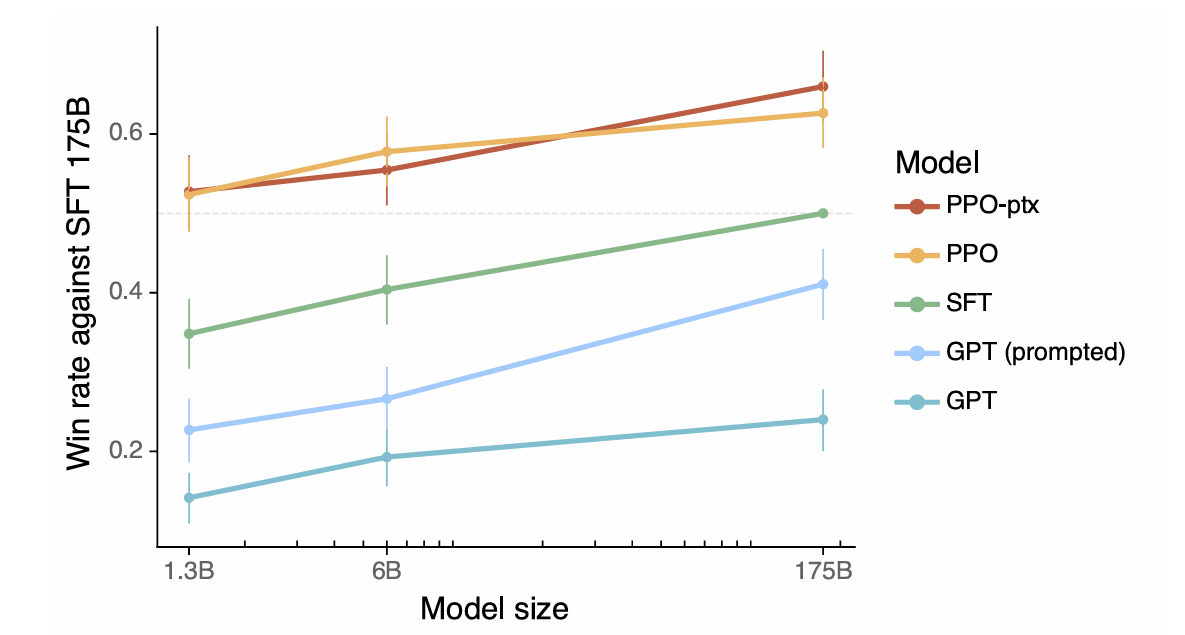 이 기사는 원하는 동작 정의, 성능 평가, 데이터 수집 및 청소, 모델 아키텍처 조정 및 잠재적 부정적인 결과 완화를 포함하여 미세 조정 LLM에 대한 주요 고려 사항을 요약함으로써 결론을 내립니다. 그것은 하이퍼 파라미터 튜닝의 신중한 고려를 장려하고 미세 조정 과정의 반복적 특성을 강조합니다.
이 기사는 원하는 동작 정의, 성능 평가, 데이터 수집 및 청소, 모델 아키텍처 조정 및 잠재적 부정적인 결과 완화를 포함하여 미세 조정 LLM에 대한 주요 고려 사항을 요약함으로써 결론을 내립니다. 그것은 하이퍼 파라미터 튜닝의 신중한 고려를 장려하고 미세 조정 과정의 반복적 특성을 강조합니다.
위 내용은 Chatgpt의 진화 이해 : Part 3- Codex 및 InstructGpt의 통찰력의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



