
이 튜토리얼에서는 NLTK (Natural Language Toolkit)라는 NLP를위한 흥미로운 Python 플랫폼을 안내해 드리겠습니다. 이 플랫폼에서 작업하는 방법을보기 전에 NLTK가 무엇인지 먼저 알려 드리겠습니다.
NLTK 란 무엇입니까?NLTK (Natural Language Toolkit)는 텍스트 분석을 위해 프로그램을 구축하는 데 사용되는 플랫폼입니다. 이 플랫폼은 2001 년 펜실베이니아 대학교 (University of Pennsylvania)의 계산 언어학 과정과 함께 Steven Bird와 Edward Loper가 원래 발표했습니다. Python을 사용한 자연 언어 처리라는 플랫폼을위한 책이 첨부되어 있습니다.
NLTK를 설치하는 것은 매우 간단합니다. 나는 Wind 출력 : 출력에서 알 수 있듯이 구두점 마크도 단어로 간주됩니다.
자신의 텍스트에서 단어를 제거 할 수있는 방법은 무엇입니까? 아래의 예는이 작업을 수행 할 수있는 방법을 보여줍니다.
위의 스크립트의 출력은 다음과 같습니다. 따라서 word_tokenize () 기능은 다음과 같습니다.<ize> <blockquote> 검색 이외의 구두점을 분할하기 위해 문자열을 토큰 화 </blockquote> <h3> 다음 텍스트 파일을 가지고 있다고 가정 해 봅시다 (Dropbox에서 텍스트 파일을 다운로드). 우리는 라는 단어를 찾고 싶습니다. 다음과 같이 NLTK 플랫폼을 사용하여 간단히 수행 할 수 있습니다. </h3>이 경우 다음 출력을 얻을 수 있습니다. <p> <code>language
"Python is a very high-level programming language. Python is interpreted."<br>
프로그램을 처음 실행했을 때 다음 오류가 발생했을 때 콘솔 사용을 인코딩하는 것과 관련이있는 것 같습니다. 위키 백과에서 언급 한 바와 같이 . 1971 년 Michael S. Hart에 의해 설립되었으며 가장 오래된 디지털 도서관입니다. 컬렉션의 대부분의 항목은 공개 도메인 북의 전체 텍스트입니다. 이 프로젝트는 거의 모든 컴퓨터에서 사용할 수있는 오래 지속되는 개방형 형식으로 가능한 한 무료로이를 만들려고합니다. 2015 년 10 월 3 일 현재 Project Gutenberg는 컬렉션에서 50,000 개의 항목에 도달했습니다.
nltk에는 Project Gutenberg의 작은 텍스트가 포함되어 있습니다. Project Gutenberg의 포함 된 파일을 보려면 다음을 수행합니다.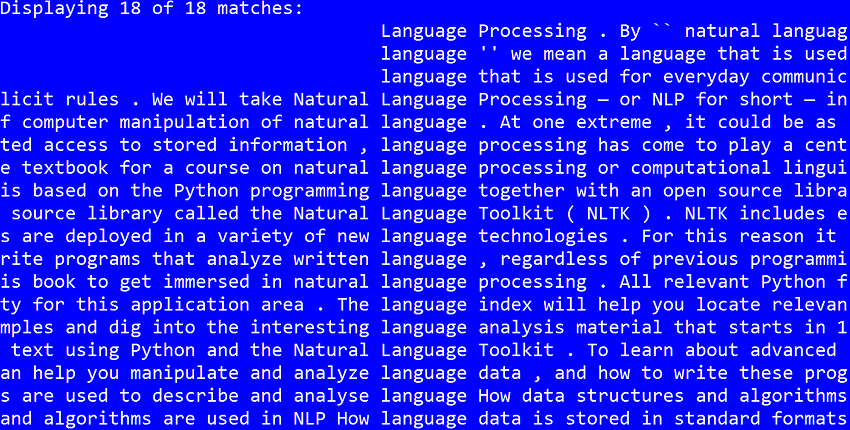 위의 스크립트의 출력은 다음과 같습니다.
위의 스크립트의 출력은 다음과 같습니다. concordance() 텍스트 파일에 대한 단어 수를 찾으려면 다음을 수행 할 수 있습니다. . language nltk.Text 결론
이 튜토리얼에서 볼 수 있듯이 NLTK 플랫폼은 NLP (Natural Language Processing) 작업을위한 강력한 도구를 제공합니다. 이 튜토리얼에서 표면 만 긁 혔습니다. 다른 NLP 작업에 NLTK를 사용하는 데 더 깊이 들어가려면 NLTK의 동반 된 책 : Python을 사용한 자연 언어 처리를 참조하십시오.
이 게시물은 Esther Vaati의 기여로 업데이트되었습니다. Esther는 Envato Tuts의 소프트웨어 개발자이자 작가입니다.위 내용은 NLTK (Natural Language Toolkit) 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



