
딥 러닝 GPU 벤치 마크는 이미지 인식에서 자연어 처리에 이르기까지 복잡한 문제를 해결하는 방식에 혁명을 일으켰습니다. 그러나 이러한 모델을 교육하는 동안 종종 고성능 GPU에 의존하는 동안 Edge 장치 또는 제한된 하드웨어가있는 시스템과 같은 자원으로 제한된 환경에 효과적으로 배포하면 고유 한 문제가 발생합니다. 널리 이용 가능하고 비용 효율적인 CPU는 종종 그러한 시나리오에서 추론의 백본 역할을합니다. 그러나 CPU에 배포 된 모델이 정확성을 손상시키지 않고 최적의 성능을 제공하도록하려면 어떻게해야합니까?
이 기사는 대기 시간, CPU 활용 및 메모리 활용의 세 가지 중요한 메트릭에 중점을 둔 CPU에서 딥 러닝 모델 추론의 벤치마킹에 뛰어 들었습니다. 스팸 분류 예제를 사용하여 Pytorch, Tensorflow, Jax 및 Onnx 런타임 핸들 추론 워크로드와 같은 인기있는 프레임 워크가 얼마나 인기있는 프레임 워크가 있는지 탐구합니다. 결국, 성능을 측정하고, 배포를 최적화하고, 자원으로 제한 된 환경에서 CPU 기반 추론에 대한 올바른 도구와 프레임 워크를 선택하는 방법에 대한 명확한 이해를 얻을 수 있습니다.
영향 : 최적의 추론 실행은 상당한 금액을 절약하고 다른 워크로드에 대한 리소스를 확보 할 수 있습니다.
이 기사는 Data Science Blogathon 의 일부로 출판되었습니다 .
추론 속도는 기계 학습 애플리케이션의 사용자 경험과 운영 효율성에 필수적입니다. 런타임 최적화는 실행을 간소화하여이를 향상시키는 데 중요한 역할을합니다. Onnx 런타임과 같은 하드웨어에 액세스 된 라이브러리를 사용하면 특정 아키텍처에 맞는 최적화를 활용하여 대기 시간을 줄입니다 (추론 당 시간).
또한 ONNX와 같은 가벼운 모델 형식은 오버 헤드를 최소화하여 더 빠른로드 및 실행을 가능하게합니다. 최적화 된 Runtimes는 병렬 처리를 활용하여 사용 가능한 CPU 코어에 걸쳐 계산을 배포하고 메모리 관리를 개선하여 특히 자원이 제한된 시스템에서 더 나은 성능을 보장합니다. 이 접근법은 정확도를 유지하면서 모델을보다 빠르고 효율적으로 만듭니다.
모델의 성능을 평가하기 위해 세 가지 주요 메트릭에 중점을 둡니다.
이 벤치마킹 연구를 집중하고 실용적으로 유지하기 위해 우리는 다음과 같은 가정을 만들고 몇 가지 경계를 설정했습니다.
이러한 가정은 벤치 마크가 자원 제한 하드웨어와 협력하는 개발자 및 팀과 관련이 있거나 분산 시스템의 복잡성이 추가되지 않으면 서 예측 가능한 성능이 필요한 사람과 관련이 있습니다.
우리는 CPU의 딥 러닝 모델 추론을 벤치마킹하고 최적화하는 데 사용되는 필수 도구와 프레임 워크를 살펴보고, 자원으로 제한된 환경에서 효율적인 실행을위한 기능에 대한 통찰력을 제공합니다.
우리는 아래 구성과 함께 Github Codespace (가상 머신)를 사용하고 있습니다.
사용 된 패키지의 버전은 다음과 같습니다.이 기본은 5 개의 딥 러닝 추론 라이브러리가 포함됩니다 : Tensorflow, Pytorch, Onnx Runtime, Jax 및 OpenVino :
! pip install numpy == 1.26.4 ! PIP 설치 토치 == 2.2.2 ! PIP 설치 TensorFlow == 2.16.2 ! pip install onnx == 1.17.0 ! PIP 설치 ONNXRUNTIME == 1.17.0! PIP 설치 jax == 0.4.30 ! PIP 설치 jaxlib == 0.4.30 ! PIP 설치 OpenVino == 2024.6.0 ! PIP 설치 MATPLOTLIB == 3.9.3 ! PIP 설치 MATPLOTLIB : 3.4.3 ! PIP 설치 베개 : 8.3.2 ! PIP 설치 PSUTIL : 5.8.0
모델 추론은 네트워크 가중치와 입력 데이터간에 몇 가지 행렬 작업을 수행하는 것으로 구성되므로 모델 교육 또는 데이터 세트가 필요하지 않습니다. 이 예제 벤치마킹 프로세스에서 표준 분류 사용 사례를 시뮬레이션했습니다. 이것은 스팸 탐지 및 대출 응용 프로그램 결정 (승인 또는 거부)과 같은 일반적인 이진 분류 작업을 시뮬레이션합니다. 이러한 문제의 이진 특성은 다양한 프레임 워크에서 모델 성능을 비교하는 데 이상적입니다. 이 설정은 실제 시스템을 반영하지만 대규모 데이터 세트 나 미리 훈련 된 모델없이 프레임 워크 전반에 걸쳐 추론 성능에 집중할 수 있습니다.
샘플 작업에는 일련의 입력 기능을 기반으로 주어진 샘플이 스팸인지 아닌지 (대출 승인 또는 거부)를 예측하는 것이 포함됩니다. 이 바이너리 분류 문제는 계산적으로 효율적이며, 다중 클래스 분류 작업의 복잡성없이 추론 성능에 대한 집중된 분석을 가능하게합니다.
실제 이메일 데이터를 시뮬레이션하기 위해 무작위로 입력을 생성했습니다. 이러한 임베딩은 스팸 필터로 처리 될 수 있지만 외부 데이터 세트가 필요하지 않은 데이터 유형을 모방합니다. 이 시뮬레이션 된 입력 데이터를 사용하면 특정 외부 데이터 세트에 의존하지 않고 벤치마킹을 허용하므로 모델 추론 시간, 메모리 사용 및 CPU 성능을 테스트하는 데 이상적입니다. 또는 이미지 분류, NLP 작업 또는 기타 딥 러닝 작업을 사용 하여이 벤치마킹 프로세스를 수행 할 수 있습니다.
모델 선택은 프로파일 링 프로세스에서 얻은 추론 성능과 통찰력에 직접적인 영향을 미치기 때문에 벤치마킹의 중요한 단계입니다. 이전 섹션에서 언급했듯이,이 벤치마킹 연구의 경우, 우리는 표준 분류 사용 사례를 선택했는데, 여기에는 주어진 이메일이 스팸인지 여부를 식별하는 것이 포함됩니다. 이 작업은 계산적으로 효율적이지만 프레임 워크 전체에서 비교하기위한 의미있는 결과를 제공하는 간단한 2 등 분류 문제입니다.
분류 작업의 모델은 이진 분류 (스팸 대 스팸)를 위해 설계된 피드 포워드 신경망 (FNN)입니다. 다음 레이어로 구성됩니다.
self.fc1 = torch.nn.linear (200,128)
self.fc2 = Torch.nn.linear (128, 64) self.fc3 = torch.nn.linear (64, 32) self.fc4 = torch.nn.linear (32, 16) self.fc5 = Torch.nn.linear (16, 8) self.fc6 = Torch.nn.linear (8, 1)
self.sigmoid = torch.nn.sigmoid ()
이 모델은 간단하지만 분류 작업에 효과적입니다.
사용 사례에서 벤치마킹에 사용되는 모델 아키텍처 다이어그램은 다음과 같습니다.
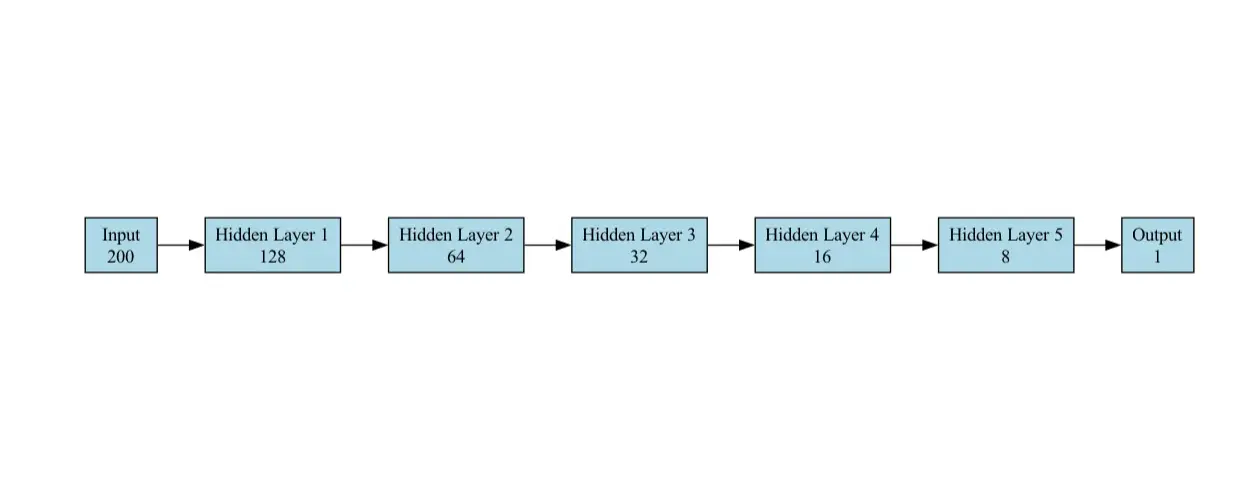
이 워크 플로우는 분류 작업을 사용하여 다중 딥 러닝 프레임 워크 (Tensorflow, Pytorch, Onx, Jax 및 OpenVino)의 추론 성능을 비교하는 것을 목표로합니다. 작업에는 무작위로 생성 된 입력 데이터를 사용하고 각 프레임 워크를 벤치마킹하여 예측에 걸리는 평균 시간을 측정하는 것이 포함됩니다.
딥 러닝 모델 벤치마킹을 시작하려면 먼저 원활한 통합 및 성능 평가를 가능하게하는 필수 파이썬 패키지를 가져와야합니다.
수입 시간 OS 가져 오기 Numpy를 NP로 가져옵니다 토치 수입 텐서 플로우를 tf로 가져옵니다 Tensorflow.keras 가져 오기 입력 onnxruntime을 ort로 가져옵니다 matplotlib.pyplot을 plt로 가져옵니다 PIL 가져 오기 이미지에서 PSUTIL을 수입하십시오 Jax를 가져옵니다 jax.numpy를 JNP로 가져옵니다 OpenVino.Runtime 가져 오기 코어에서 CSV 가져 오기
os.environ [ "cuda_visible_devices"] = "-1" # gpu 비활성화 os.environ [ "TF_CPP_MIN_LOG_LEVEL"] = "3"#SUPPRESS TENSORFLOW LOG
이 단계에서는 스팸 분류를위한 입력 데이터를 무작위로 생성합니다.
Numpy를 사용하여 Randome 데이터를 생성하여 모델의 입력 기능 역할을합니다.
#Generate 더미 데이터 input_data = np.random.rand (1000, 200) .astype (np.float32)
이 단계에서는 Netwrok 아키텍처를 정의하거나 각 딥 러닝 프레임 워크 (Tensorflow, Pytorch, Onnx, Jax 및 Openvino)에서 모델을 설정합니다. 각 프레임 워크에는 모델을로드하고 추론을 위해 설정하기위한 특정 방법이 필요합니다.
클래스 pytorchmodel (torch.nn.module) :
def __init __ (self) :
Super (pytorchmodel, self) .__ init __ ()
self.fc1 = torch.nn.linear (200, 128)
self.fc2 = Torch.nn.linear (128, 64)
self.fc3 = torch.nn.linear (64, 32)
self.fc4 = torch.nn.linear (32, 16)
self.fc5 = Torch.nn.linear (16, 8)
self.fc6 = Torch.nn.linear (8, 1)
self.sigmoid = torch.nn.sigmoid ()
def forward (self, x) :
x = 토치. relu (self.fc1 (x))
x = 토치. relu (self.fc2 (x))
x = 토치. relu (self.fc3 (x))
x = 토치. relu (self.fc4 (x))
x = 토치. relu (self.fc5 (x))
x = self.sigmoid (self.fc6 (x))
반환 x
# Pytorch 모델을 만듭니다
pytorch_model = pytorchmodel () Tensorflow_model = tf.keras.sequential ([[
입력 (shape = (200,)),
tf.keras.layers.dense (128, Activation = 'Relu'),
tf.keras.layers.dense (64, Activation = 'Relu'),
tf.keras.layers.dense (32, Activation = 'Relu'),
tf.keras.layers.dense (16, Activation = 'Relu'),
tf.keras.layers.dense (8, activation = 'Relu'),
tf.keras.layers.dense (1, activation = 'sigmoid')
])))
Tensorflow_model.compile () def jax_model (x) :
x = jax.nn.relu (jnp.dot (x, jnp.ones ((200, 128)))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((128, 64)))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((64, 32)))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((32, 16)))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((16, 8)))))
x = jax.nn.sigmoid (jnp.dot (x, jnp.ones ((8, 1))))
반환 x # pytorch 모델을 Onx로 변환합니다
Dummy_Input = Torch.randn (1, 200)
onnx_model_path = "model.onnx"
Torch.onnx.export (
pytorch_model,
dummy_input,
onnx_model_path,
Export_params = true,
opset_version = 11,
input_names = [ 'input'],
output_names = [ 'output'],
Dynamic_axes = { 'input': {0 : 'batch_size'}, 'output': {0 : 'batch_size'}}
))
onnx_session = ort.inferencessession (onnx_model_path)# OpenVino 모델 정의 core = core () OpenVino_Model = Core.Read_Model (Model = "Model.onnx") compiled_model = core.compile_model (OpenVino_Model, device_name = "CPU")
이 기능은 Predict_Function, Input_Data 및 NUM_RUNS의 세 가지 인수를 통해 다른 프레임 워크에서 벤치마킹 테스트를 실행합니다. 기본적으로 1,000 회 실행하지만 요구 사항에 따라 증가 할 수 있습니다.
DEF Benchmark_Model (predict_function, input_data, num_runs = 1000) :
start_time = time.time ()
process = psutil.process (os.getpid ())
cpu_usage = []
memory_usage = []
_ in range (num_runs) :
predict_function (input_data)
cpu_usage.append (process.cpu_percent ())
memory_usage.append (process.memory_info (). rss)
end_time = time.time ()
avg_latency = (end_time -start_time) / num_runs
avg_cpu = np.mean (cpu_usage)
avg_memory = np.mean (memory_usage) / (1024 * 1024) # MB로 변환
avg_latency, avg_cpu, avg_memory를 반환하십시오이제 모델을로드 했으므로 이제 각 프레임 워크의 성능을 벤치마킹해야합니다. 벤치마킹 프로세스는 생성 된 입력 데이터에 대한 추론을 수행합니다.
# 벤치 마크 Pytorch 모델
def pytorch_predict (input_data) :
pytorch_model (Torch.tensor (input_data))
pytorch_latency, pytorch_cpu, pytorch_memory = benchmark_model (lambda x : pytorch_predict (x), input_data) # 벤치 마크 TensorFlow 모델
def tensorflow_predict (input_data) :
TensorFlow_Model (input_data)
Tensorflow_latency, tensorflow_cpu, tensorflow_memory = benchmark_model (Lambda x : Tensorflow_predict (x), input_data) # 벤치 마크 JAX 모델
def jax_predict (input_data) :
jax_model (jnp.array (input_data))
jax_latency, jax_cpu, jax_memory = benchmark_model (lambda x : jax_predict (x), input_data) # 벤치 마크 onx 모델
def onnx_predict (input_data) :
# 배치의 프로세스 입력
IN 범위 (input_data.shape [0])의 경우 :
Single_Input = input_data [i : i 1] # 단일 입력 추출
onnx_session.run (none, {onnx_session.get_inputs () [0] .name : single_input})
onnx_latency, onnx_cpu, onnx_memory = benchmark_model (lambda x : onnx_predict (x), input_data) # 벤치 마크 OpenVino 모델
def OpenVino_Predict (input_data) :
# 배치의 프로세스 입력
IN 범위 (input_data.shape [0])의 경우 :
Single_Input = input_data [i : i 1] # 단일 입력 추출
compiled_model.infer_new_request ({0 : single_input})
OpenVino_Latency, OpenVino_CPU, OpenVino_Memory = Benchmark_Model (Lambda X : OpenVino_predict (X), Input_Data)
여기에서는 이전에 언급 된 딥 러닝 프레임 워크의 성능 벤치마킹 결과에 대해 논의합니다. 대기 시간, CPU 사용 및 메모리 사용량을 비교합니다. 빠른 비교를 위해 테이블 데이터와 플롯을 포함 시켰습니다.
| 뼈대 | 대기 시간 (MS) | 상대 대기 시간 (pytorch vs. pytorch) |
| Pytorch | 1.26 | 1.0 (기준선) |
| 텐서 플로 | 6.61 | ~ 5.25 × |
| Jax | 3.15 | ~ 2.50 × |
| onx | 14.75 | ~ 11.72 × |
| OpenVino | 144.84 | ~ 115 × |
통찰력 :
| 뼈대 | CPU 사용 (%) | 상대 CPU 사용량 1 |
| Pytorch | 99.79 | ~ 1.00 |
| 텐서 플로 | 112.26 | ~ 1.13 |
| Jax | 130.03 | ~ 1.31 |
| onx | 99.58 | ~ 1.00 |
| OpenVino | 99.32 | 1.00 (기준선) |
통찰력 :
| 뼈대 | 메모리 (MB) | 상대 메모리 사용 (Pytorch vs. Pytorch) |
| Pytorch | ~ 959.69 | 1.0 (기준선) |
| 텐서 플로 | ~ 969.72 | ~ 1.01 × |
| Jax | ~ 1033.63 | ~ 1.08 × |
| onx | ~ 1033.82 | ~ 1.08 × |
| OpenVino | ~ 1040.80 | ~ 1.08–1.09 × |
통찰력 :
딥 러닝 프레임 워크의 성능을 비교하는 플롯은 다음과 같습니다.

이 기사에서는 스팸 분류 작업을 참조로 사용하는 저명한 딥 러닝 프레임 워크 (Tensorflow, Pytorch, Onx, Jax 및 OpenVino)의 추론 성능을 평가하기위한 포괄적 인 벤치마킹 워크 플로우를 제시했습니다. 대기 시간, CPU 사용 및 메모리 소비와 같은 주요 메트릭을 분석함으로써 결과는 프레임 워크 간의 상충 관계와 다양한 배포 시나리오에 대한 적합성을 강조했습니다.
Pytorch는 가장 균형 잡힌 성능을 보여 주면서 낮은 대기 시간과 효율적인 메모리 사용이 뛰어나며 실시간 예측 및 권장 시스템과 같은 대기 시간에 민감한 응용 프로그램에 이상적입니다. Tensorflow는 자원 소비가 약간 높은 중간 지상 솔루션을 제공했습니다. JAX는 높은 계산 처리량을 보여 주었지만 CPU 활용이 증가하는 비용으로 자원으로 제한된 환경의 제한 요소가 될 수 있습니다. 한편, Onx와 OpenVino는 대기 시간이 지연되었으며 OpenVino의 성능은 특히 하드웨어 가속이 없기 때문에 방해가되었습니다.
이러한 결과는 배치 요구와 프레임 워크 선택을 정렬하는 것의 중요성을 강조합니다. 속도, 자원 효율성 또는 특정 하드웨어 최적화에 관계없이 실제 환경에서 효과적인 모델 배포에는 트레이드 오프 이해가 필수적입니다.
A. Pytorch의 동적 계산 그래프 및 효율적인 실행 파이프 라인을 통해 낮은 격렬한 추론 (1.26ms)을 허용하여 권장 시스템 및 실시간 예측과 같은 응용 프로그램에 적합합니다.
Q2. 이 연구에서 OpenVino의 성능에 어떤 영향을 미쳤습니까?A. OpenVino의 최적화는 인텔 하드웨어 용으로 설계되었습니다. 이러한 가속이 없으면 대기 시간 (144.84ms)과 메모리 사용량 (1040.8MB)은 다른 프레임 워크에 비해 경쟁이 덜했습니다.
Q3. 자원으로 제한된 환경을위한 프레임 워크를 어떻게 선택합니까?A. CPU 전용 설정의 경우 Pytorch가 가장 효율적입니다. Tensorflow는 중간 정도의 워크로드를위한 강력한 대안입니다. 더 높은 CPU 활용도가 허용되지 않는 한 JAX와 같은 프레임 워크를 피하십시오.
Q4. 하드웨어는 프레임 워크 성능에서 어떤 역할을합니까?A. 프레임 워크 성능은 하드웨어 호환성에 크게 의존합니다. 예를 들어, OpenVino는 하드웨어 별 최적화를 통해 Intel CPU에서 탁월한 반면 Pytorch 및 Tensorflow는 다양한 설정에서 일관되게 성능을 발휘합니다.
Q5. 벤치마킹 결과가 복잡한 모델이나 작업과 다를 수 있습니까?A. 예, 이러한 결과는 간단한 이진 분류 작업을 반영합니다. 성능은 RESNET과 같은 복잡한 아키텍처 또는 NLP 또는 다른 작업과 같은 작업에 따라 다를 수 있으며, 이러한 프레임 워크는 특수 최적화를 활용할 수 있습니다.
이 기사에 표시된 미디어는 분석 Vidhya가 소유하지 않으며 저자의 재량에 따라 사용됩니다.
위 내용은 딥 러닝 CPU 벤치 마크의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



