
이 블로그 게시물은 대형 Pytorch 모델을로드하기위한 효율적인 메모리 관리 기술을 탐색합니다. 특히 제한된 GPU 또는 CPU 리소스를 다룰 때 유리합니다. 저자는 torch.save(model.state_dict(), "model.pth") 사용하여 모델을 저장하는 시나리오에 중점을 둡니다. 이 예제는 LLM (Large Language Model)을 사용하지만 기술은 모든 Pytorch 모델에 적용 할 수 있습니다.
효율적인 모델 로딩을위한 주요 전략 :
이 기사는 모델 로딩 중에 메모리 사용량을 최적화하는 몇 가지 방법을 자세히 설명합니다.
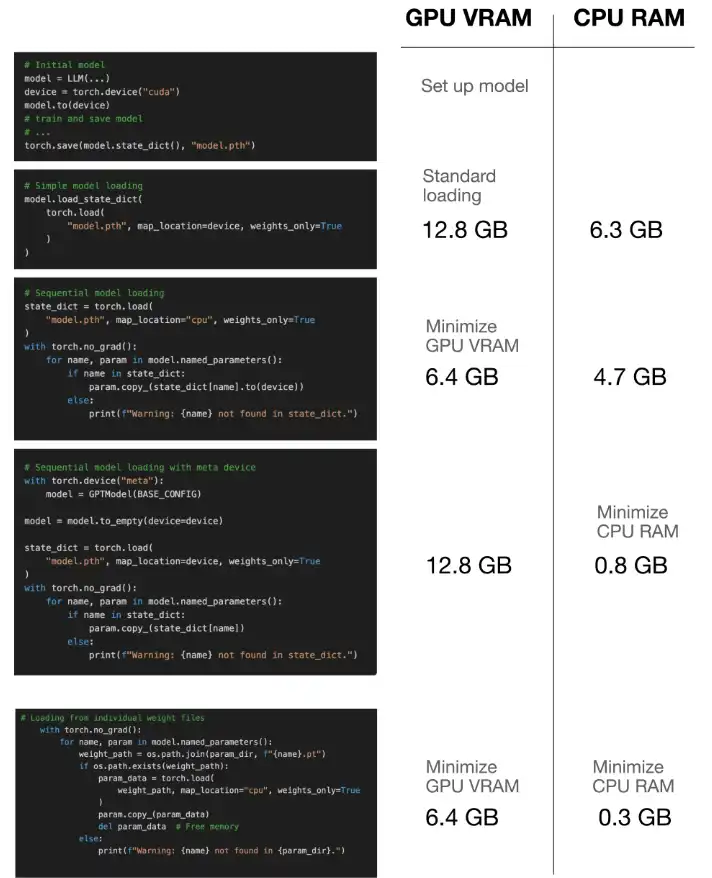
순차적 중량 로딩 : 이 기술은 모델 아키텍처를 GPU에로드 한 다음 CPU 메모리에서 GPU로 개별 가중치를 반복적으로 복사합니다. 이것은 GPU 메모리에서 전체 모델과 가중치의 동시 존재를 방해하여 피크 메모리 소비를 크게 줄입니다.
메타 장치 : Pytorch의 "Meta"장치는 즉각적인 메모리 할당없이 텐서 생성을 가능하게합니다. 모델은 메타 장치에서 초기화 된 다음 GPU로 전송되고 가중치를 GPU에 직접로드하여 CPU 메모리 사용을 최소화합니다. 이것은 CPU RAM이 제한된 시스템에 특히 유용합니다.
mmap=True in torch.load() : 이 옵션은 메모리 매핑 된 파일 I/O를 사용하여 Pytorch가 모든 것을 RAM에로드하지 않고 주문형 디스크에서 직접 모델 데이터를 읽을 수 있습니다. 이것은 제한된 CPU 메모리 및 빠른 디스크 I/O가있는 시스템에 이상적입니다.
개별 체중 절약 및로드 : 매우 제한된 리소스의 최후의 수단으로서,이 기사는 각 모델 매개 변수 (Tensor)를 별도의 파일로 저장할 것을 제안합니다. 로드는 한 번에 하나의 매개 변수가 발생하여 주어진 순간에 메모리 발자국을 최소화합니다. 이것은 I/O 간접비가 증가하는 비용으로 발생합니다.
실제 구현 및 벤치마킹 :
이 게시물은 GPU 및 CPU 메모리 사용을 추적하기위한 유틸리티 기능을 포함하여 각 기술을 보여주는 파이썬 코드 스 니펫을 제공합니다. 이러한 벤치 마크는 각 방법에 의해 달성 된 메모리 절약을 보여줍니다. 저자는 각 접근 방식의 메모리 사용량을 비교하여 메모리 효율성과 잠재적 성능 영향 사이의 상충 관계를 강조합니다.
결론:
이 기사는 특히 대규모 모델에 대한 메모리 효율적인 모델 로딩의 중요성을 강조함으로써 결론을 내립니다. 특정 하드웨어 제한 (CPU RAM, GPU VRAM) 및 I/O 속도를 기반으로 가장 적합한 기술을 선택하는 것이 좋습니다. mmap=True 접근 방식은 일반적으로 제한된 CPU RAM에 대해 선호되는 반면, 개별 중량 로딩은 매우 제한된 환경의 최후의 수단입니다. 순차적 로딩 방법은 많은 시나리오에 대한 균형을 제공합니다.
위 내용은 Pytorch의 메모리 효율적인 모델 무게 로딩의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



