
Apache Iceberg : 향상된 데이터 레이크 관리를위한 최신 테이블 형식
Apache Iceberg는 전통적인 하이브 테이블의 단점을 해결하도록 설계된 최첨단 테이블 형식으로, 우수한 성능, 데이터 일관성 및 확장 성을 제공합니다. 이 기사는 빙산의 진화, 주요 특징 (산 거래, 스키마 진화, 시간 여행), 아키텍처 및 델타 레이크 및 파크와 같은 다른 테이블 형식과의 비교를 탐구합니다. 또한 최신 데이터 호수와의 통합 및 대규모 데이터 관리 및 분석에 미치는 영향도 검토합니다.
2017 년 Netflix (Ryan Blue와 Daniel Weeks의 아이디어)에서 시작된 Apache Iceberg는 Hive 테이블 형식에 내재 된 성능 병목 현상, 일관성 문제 및 제한을 해결하기 위해 만들어졌습니다. 2018 년 Apache Software Foundation에 오픈 소스 및 기증 된이 회사는 빠르게 견인력을 얻었으며 Apple, AWS 및 LinkedIn과 같은 업계 대기업의 기여를 유치했습니다.
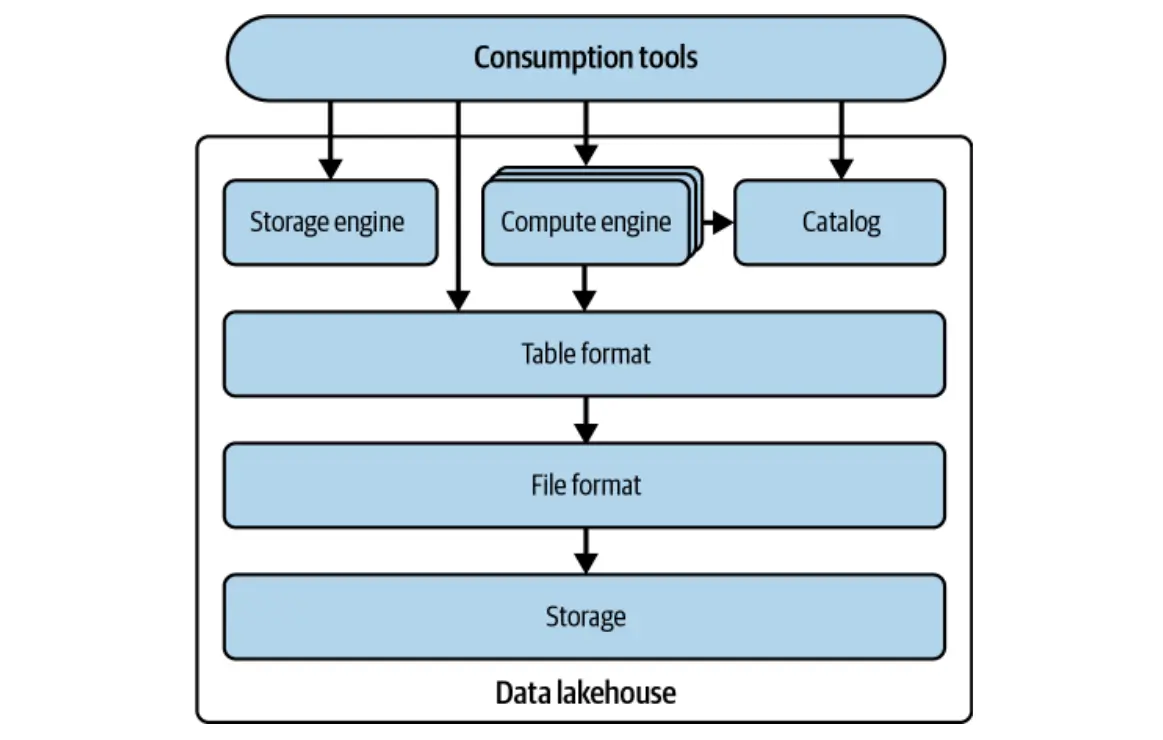
Netflix의 경험은 Hive의 중요한 약점 인 테이블 추적 디렉토리에 대한 의존성을 강조했습니다. 이 접근법은 강력한 일관성, 효율적인 동시성 및 최신 데이터웨어 하우스에서 예상되는 고급 기능에 필요한 세분성이 부족했습니다. 빙산의 발전은 다음에 중점을두고 이러한 한계를 극복하는 것을 목표로했습니다.
빙산은 디렉토리가 아닌 구조화 된 파일 목록으로 테이블을 추적하여 이러한 과제를 해결합니다. 여러 파일에서 메타 데이터 구조를 정의하는 표준화 된 형식을 제공하며 Spark 및 Flink와 같은 인기있는 엔진과 완벽한 통합을위한 라이브러리를 제공합니다.
빙산의 설계는 기존 스토리지 및 컴퓨팅 엔진과의 호환성을 우선시하여 중대한 변화없이 광범위한 채택을 촉진합니다. 목표는 빙산을 업계 표준으로 설정하여 사용자가 기본 형식에 관계없이 테이블과 상호 작용할 수 있도록하는 것입니다. 많은 데이터 도구는 이제 네이티브 빙산 지원을 제공합니다.
빙산은 단순히 Hive의 한계를 다루는 것을 초월합니다. 데이터 레이크 및 데이터 레이크 하우스 워크로드를 향상시키는 강력한 기능을 소개합니다. 주요 기능은 다음과 같습니다.
빙산은 낙관적 동시성 제어를 사용하여 산성 특성을 보장하여 거래가 완전히 커밋되거나 완전히 롤백되도록 보장합니다. 이것은 데이터 무결성을 유지하면서 충돌을 최소화합니다.
전통적인 데이터 호수와 달리 Iceberg는 전체 테이블을 다시 작성하지 않고 분할 체계를 수정할 수 있습니다. 이를 통해 기존 데이터를 방해하지 않고 효율적인 쿼리 최적화를 보장합니다.
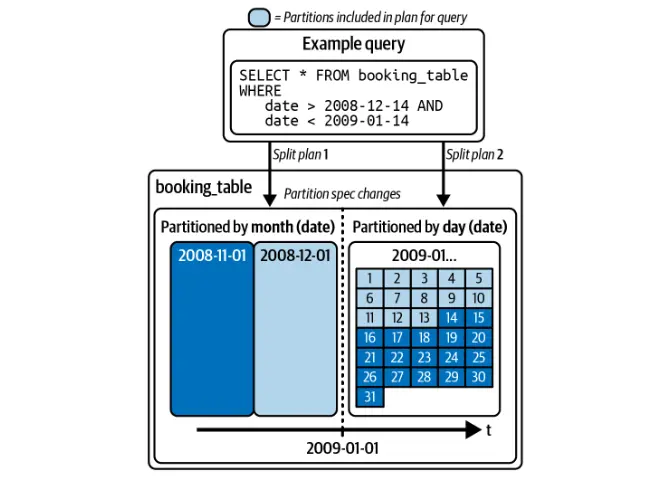
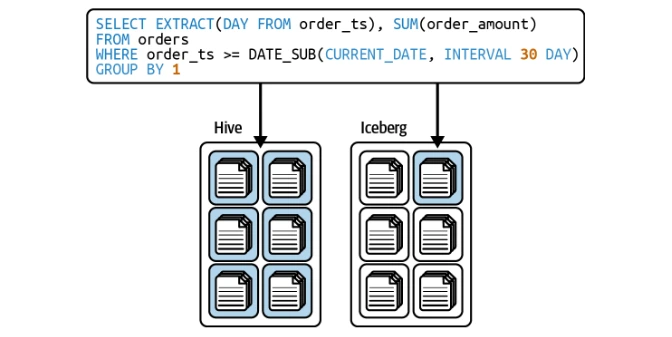
빙산은 분할을 기반으로 쿼리를 자동으로 최적화하여 사용자가 파티션 열을 수동으로 필터링 할 필요가 없습니다.
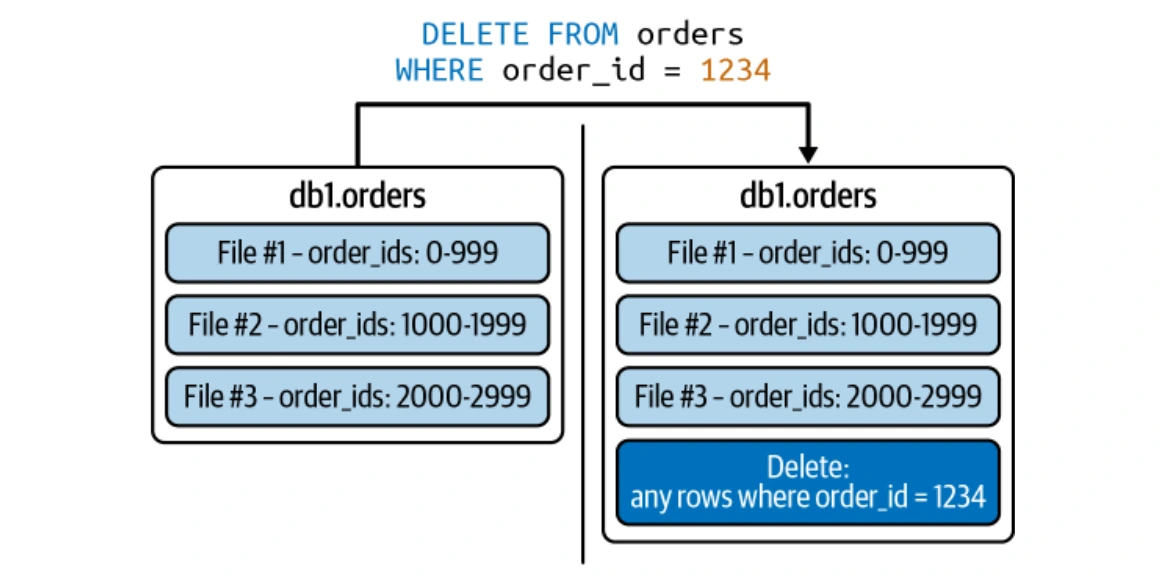
빙산은 효율적인 행 수준 업데이트를 위해 COP (Copy-on-Write) 및 MOR (Merge-on-Read) 전략을 모두 지원합니다.
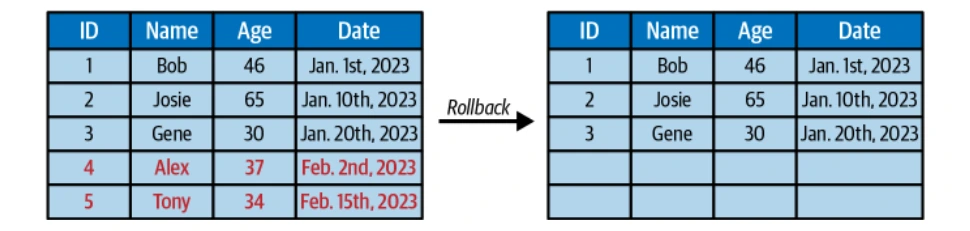
Iceberg의 불변의 스냅 샷은 시간 여행 쿼리와 이전 테이블 상태로 롤백하는 기능을 가능하게합니다.

빙산은 데이터 재 작성없이 스키마 수정 (열을 추가, 제거 또는 변경)을 지원하여 유연성과 호환성을 보장합니다.
이 섹션에서는 빙산의 건축과 하이브의 한계를 극복하는 방법을 살펴 봅니다.
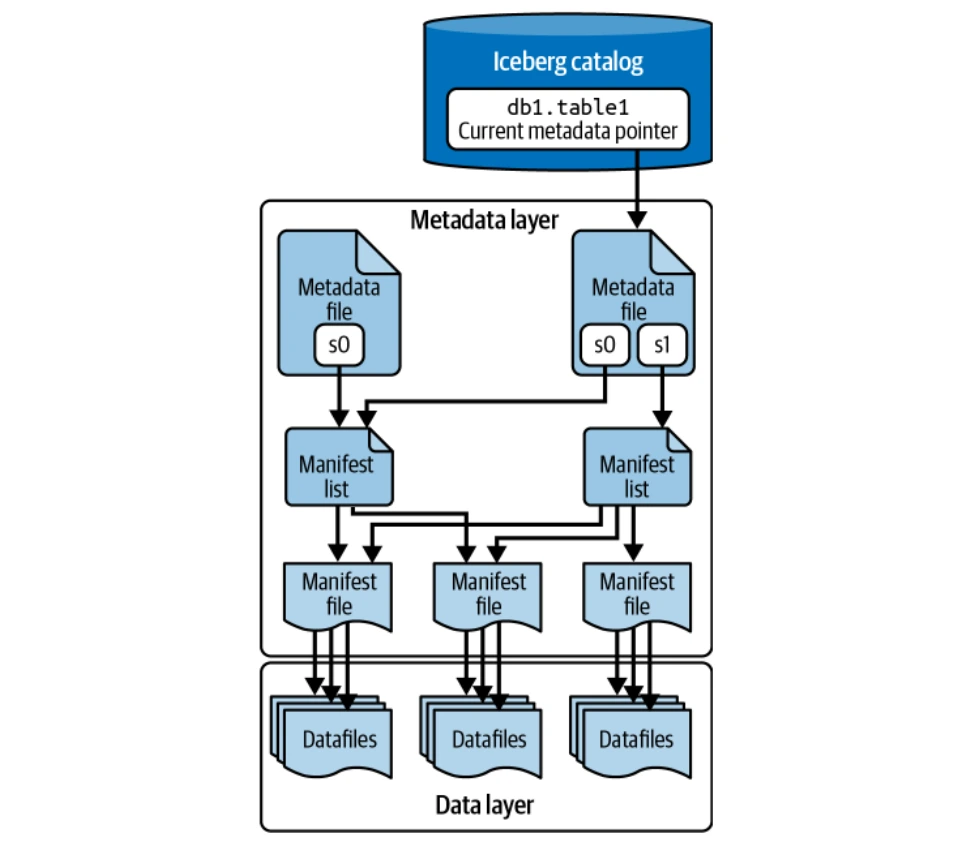
데이터 계층은 실제 테이블 데이터 (데이터 파일 및 파일 삭제)를 저장합니다. 분산 파일 시스템 (HDFS, S3 등)에서 호스팅되며 여러 파일 형식 (Parquet, ORC, AVRO)을 지원합니다. 파르켓은 일반적으로 원주민 저장에 선호됩니다.


이 레이어는 모든 메타 데이터 파일을 트리 구조로 관리하고 데이터 파일 및 작업을 추적합니다. 주요 구성 요소에는 매니페스트 파일, 매니페스트 목록 및 메타 데이터 파일이 포함됩니다. Puffin Files는 쿼리 최적화를 위해 고급 통계 및 인덱스를 저장합니다.
카탈로그는 중앙 레지스트리 역할을하여 각 테이블의 현재 메타 데이터 파일의 위치를 제공하여 모든 독자 및 작가에게 일관된 액세스를 보장합니다. 다양한 백엔드는 빙산 카탈로그 (Hadoop 카탈로그, 하이브 전이, Nessie 카탈로그, AWS 접착제 카탈로그) 역할을 할 수 있습니다.
Iceberg, Parquet, Orc 및 Delta Lake는 대규모 데이터 처리에 자주 사용됩니다. 빙산은 파일 형식 인 파크 및 오크와 달리 트랜잭션 보증 및 메타 데이터 최적화를 제공하는 테이블 형식으로 구별됩니다. Delta Lake와 비교할 때 Iceberg는 스키마 및 파티션 진화에 탁월합니다.
Apache Iceberg는 Data Lake Management에 대한 강력하고 확장 가능하며 사용자 친화적 인 접근 방식을 제공합니다. 이 기능은 대규모 데이터를 처리하는 조직에 매력적인 솔루션이됩니다.
Q1. 아파치 빙산이란 무엇입니까? A. 데이터 레이크 성능, 일관성 및 확장 성을 향상시키는 현대적인 오픈 소스 테이블 형식.
Q2. 아파치 빙산이 필요한 이유는 무엇입니까? A. 메타 데이터 처리 및 거래 기능에서 Hive의 한계를 극복합니다.
Q3. 빙산은 스키마 진화를 어떻게 처리합니까? A. 전체 테이블 재 작성 없이도 스키마 변경을 지원합니다.
Q4. 빙산의 파티션 진화는 무엇입니까? A. 과거 데이터를 다시 작성하지 않고 분할 체계 수정.
Q5. 빙산은 산 거래를 어떻게 지원합니까? A. 낙관적 동시성 제어를 통해 원자 업데이트를 보장합니다.
위 내용은 아파치 빙산 테이블을 사용하는 방법?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



