

Javascript 이미지 처리 - Virtual Edge 소개 및 사용법_javascript 기술

이전 기사에서는 행렬에 몇 가지 일반적인 방법을 추가했습니다. 이 기사에서는 이미지의 가상 가장자리에 대해 설명합니다.
가상 가장자리
가상 가장자리는 특정 매핑 관계에 따라 이미지에 가장자리를 추가하는 것입니다.
그럼 가상 가장자리의 용도는 무엇인가요? 예를 들어, 반사 효과를 쉽게 만들 수 있습니다.

물론 이것은 단지 부작용일 뿐입니다. 가상 가장자리는 이미지 컨볼루션 작업(예: 스무딩 작업)의 특성상 주로 사용됩니다. 컨벌루션 작업에서는 이미지를 확대해야만 모서리를 컨볼루션할 수 있습니다. 이때 이미지를 전처리하고 가상 가장자리를 추가해야 합니다.
직접 말하면 이미지 처리 전 전처리를 한다는 뜻입니다.
Edge 유형
OpenCV 관련 문서의 Edge 설명은 다음과 같습니다.
/*
다양한 테두리 유형, 이미지 경계는 '|'로 표시됩니다.
* BORDER_REPLICATE: aaaaaa|abcdefgh|hhhhhhh
* BORDER_REFLECT: fedcba| abcdefgh|hgfedcb
* BORDER_REFLECT_101: gfedcb|abcdefgh|gfedcba
* BORDER_WRAP: cdefgh|abcdefgh|abcdefg
* BORDER_CONSTANT: iiiiii|abcdefgh|iiiiiii 일부 지정된 'i'
* /
예를 들어 BODER_REFLECT는 특정 픽셀 행 또는 열에 대한 것입니다.
abcdefgh
왼쪽 가상 가장자리는 fedcba에 해당하고 오른쪽은 반사 매핑인 hgfedcb에 해당합니다. . 위 그림은 그림 하단에 BORDER_REFLECT 유형의 가상 가장자리를 추가하여 얻은 것입니다.
그리고 BORDER_CONSTANT는 모든 가장자리가 고정된 값 i를 갖는다는 것을 의미합니다.
구현
BORDER_CONSTANT는 특수하므로 다른 유형과 별도로 처리됩니다.
function copyMakeBorder(__src, __top, __left, __bottom, __right , __borderType, __value){
if(__src.type != "CV_RGBA"){
console.error("지원되지 않는 유형!");
}
if(__borderType = == CV_BORDER_CONSTANT ){
return copyMakeConstBorder_8U(__src, __top, __left, __bottom, __right, __value);
}else{
return copyMakeBorder_8U(__src, __top, __left, __bottom, __right, __borderType); 🎜>}
};
그런 다음 에지 매핑 관계 함수 borderInterpolate를 소개합니다.
if(__p < 0 || __p >= __len){
switch(__borderType){
case CV_BORDER_REPLICATE:
__p = __p < 0 ? 🎜>break ;
case CV_BORDER_REFLECT:
case CV_BORDER_REFLECT_101:
var delta = __borderType == CV_BORDER_REFLECT_101;
if(__len == 1)
return 0; >if( __p __p = -__p - 1 델타;
else
__p = __len - 1 - (__p - __len) -
}while(__p < 0 || __p >= __len)
break;
case CV_BORDER_WRAP:
if(__p < 0)
__p -= ((__p - __len 1) / __len)
if( __p >= __len)
__p %= __len;
break;
case CV_BORDER_CONSTANT:
__p = -1
error(arguments.callee, UNSPPORT_BORDER_TYPE/* {line} */);
}
}
return __p;
}
이 함수의 의미는 특정 라인 또는 원래 길이가 len인 선. 가상 픽셀 p의 열(p는 일반적으로 음수이거나 행의 원래 길이보다 크거나 같은 숫자입니다. 음수는 선의 왼쪽에 있는 픽셀을 나타냅니다. 원래 길이보다 크거나 같은 숫자는 오른쪽의 픽셀을 나타냅니다)가 이 행에 매핑됩니다. CV_BORDER_REPLICATE를 분석해 보겠습니다.
__p = __p < 0 ? 0 : __len - 1
즉, p가 음수인 경우(즉, 왼쪽) 매핑됩니다. 0으로, 그렇지 않으면 len - 1로 매핑됩니다.
그런 다음 copyMakeBorder_8U 함수를 구현합니다.
코드 복사
function copyMakeBorder_8U(__src, __top, __left, __bottom, __right, __borderType){
var i, j;
var 너비 = __src.col,
높이 = __src.row;
var top = __top,
left = __left || __상단,
오른쪽 = __오른쪽 || 왼쪽,
하단 = __bottom || 상단,
dstWidth = 너비 왼쪽 오른쪽,
dstHeight = 높이 상단 하단,
borderType = borderType || CV_BORDER_REFLECT;
var buffer = new ArrayBuffer(dstHeight * dstWidth * 4),
tab = new Uint32Array(왼쪽 오른쪽);
for(i = 0; i tab[i] = borderInterpolate(i - 왼쪽, 너비, __borderType);
}
for(i = 0; i < right; i ){
tab[i left] = borderInterpolate(width i, width, __borderType);
}
var tempArray, 데이터;
for(i = 0; i tempArray = new Uint32Array(buffer, (i top) * dstWidth * 4, dstWidth);
data = new Uint32Array(__src.buffer, i * 너비 * 4, 너비);
for(j = 0; j tempArray[j] = data[tab[j]];
for(j = 0; j tempArray[j 너비 왼쪽] = data[tab[j 왼쪽]];
tempArray.set(데이터, 왼쪽);
}
var allArray = new Uint32Array(버퍼);
for(i = 0; i j = borderInterpolate(i - top, height, __borderType);
tempArray = new Uint32Array(buffer, i * dstWidth * 4, dstWidth);
tempArray.set(allArray.subarray((j top) * dstWidth, (j top 1) * dstWidth));
}
for(i = 0; i < Bottom; i ){
j = borderInterpolate(i height, height, __borderType);
tempArray = new Uint32Array(buffer, (i 상단 높이) * dstWidth * 4, dstWidth);
tempArray.set(allArray.subarray((j top) * dstWidth, (j top 1) * dstWidth));
}
return new Mat(dstHeight, dstWidth, new Uint8ClampedArray(buffer));
}
这里需要解释下, 边缘的复顺序是:先对每行的左右进行扩話,然后在此基础上进行上下扩試,如图所示。
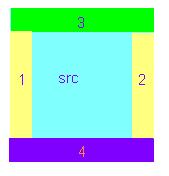
저희는 ArrayBuffer의 특성을 이용하여 ArrayBuffer의 성능을 향상시켰습니다.点了。什么의미思?
比如对于某个image素点: RGBA, 由于某个通道是用无符号8为整数来存储的, 所以实际一个 Image 素点则对应了32位的存储大小, 由于ArrayBuffer 性质,可以将数据转成任意类型来处理,这样우리는 Uint32Array类型,将数据变成每个image素点的数据数组。
那么copyConstBorder_8U就比较容易实现了:
function copyMakeConstBorder_8U(__src, __top, __left, __bottom, __right, __value){
var i, j;
var 너비 = __src.col,
높이 = __src.row;
var top = __top,
left = __left || __상단,
오른쪽 = __오른쪽 || 왼쪽,
하단 = __bottom || 상단,
dstWidth = 너비 왼쪽 오른쪽,
dstHeight = 높이 상단 하단,
value = __value || [0, 0, 0, 255];
var constBuf = new ArrayBuffer(dstWidth * 4),
constArray = new Uint8ClampedArray(constBuf);
버퍼 = new ArrayBuffer(dstHeight * dstWidth * 4);
for(i = 0; i for( j = 0; j constArray[i * 4 j] = value[j];
}
}
constArray = new Uint32Array(constBuf);
var tempArray;
for(i = 0; i tempArray = new Uint32Array(buffer, (i top) * dstWidth * 4, left);
tempArray.set(constArray.subarray(0, 왼쪽));
tempArray = new Uint32Array(buffer, ((i top 1) * dstWidth - right) * 4, right);
tempArray.set(constArray.subarray(0, 오른쪽));
tempArray = new Uint32Array(buffer, ((i top) * dstWidth left) * 4, width);
tempArray.set(new Uint32Array(__src.buffer, i * width * 4, width));
}
for(i = 0; i < top; i ){
tempArray = new Uint32Array(buffer, i * dstWidth * 4, dstWidth);
tempArray.set(constArray);
}
for(i = 0; i < Bottom; i ){
tempArray = new Uint32Array(buffer, (i 상단 높이) * dstWidth * 4, dstWidth);
tempArray.set(constArray);
}
return new Mat(dstHeight, dstWidth, new Uint8ClampedArray(buffer));
}
效果图
CV_BORDER_REPLICATE

CV_BORDER_REFLECT

CV_BORDER_WRAP

CV_BORDER_CONSTANT


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7488
7488
 15
1377
52
77
11
51
19
19
40
15
1377
52
77
11
51
19
19
40

 이미지 처리 작업에서 Wasserstein 거리가 어떻게 사용되나요?
Jan 23, 2024 am 10:39 AM
이미지 처리 작업에서 Wasserstein 거리가 어떻게 사용되나요?
Jan 23, 2024 am 10:39 AM
EMD(EarthMover's Distance)라고도 알려진 Wasserstein 거리는 두 확률 분포 간의 차이를 측정하는 데 사용되는 측정 기준입니다. 전통적인 KL 분기 또는 JS 분기와 비교하여 Wasserstein 거리는 분포 간의 구조적 정보를 고려하므로 많은 이미지 처리 작업에서 더 나은 성능을 나타냅니다. 두 배포판 간의 최소 운송 비용을 계산함으로써 Wasserstein 거리는 한 배포판을 다른 배포판으로 변환하는 데 필요한 최소 작업량을 측정할 수 있습니다. 이 측정항목은 분포 간의 기하학적 차이를 포착할 수 있으므로 이미지 생성 및 스타일 전송과 같은 작업에서 중요한 역할을 합니다. 따라서 Wasserstein 거리가 개념이 됩니다.
 Vision Transformer(VIT) 모델의 작동 원리 및 특성에 대한 심층 분석
Jan 23, 2024 am 08:30 AM
Vision Transformer(VIT) 모델의 작동 원리 및 특성에 대한 심층 분석
Jan 23, 2024 am 08:30 AM
VisionTransformer(VIT)는 Google에서 제안하는 Transformer 기반의 이미지 분류 모델입니다. 기존 CNN 모델과 달리 VIT는 이미지를 시퀀스로 표현하고 이미지의 클래스 레이블을 예측하여 이미지 구조를 학습합니다. 이를 달성하기 위해 VIT는 입력 이미지를 여러 패치로 나누고 채널을 통해 각 패치의 픽셀을 연결한 다음 선형 투영을 수행하여 원하는 입력 크기를 얻습니다. 마지막으로 각 패치는 단일 벡터로 평면화되어 입력 시퀀스를 형성합니다. Transformer의 self-attention 메커니즘을 통해 VIT는 서로 다른 패치 간의 관계를 캡처하고 효과적인 특징 추출 및 분류 예측을 수행할 수 있습니다. 이 직렬화된 이미지 표현은
 AI 기술을 활용해 오래된 사진을 복원하는 방법(예제 및 코드 분석 포함)
Jan 24, 2024 pm 09:57 PM
AI 기술을 활용해 오래된 사진을 복원하는 방법(예제 및 코드 분석 포함)
Jan 24, 2024 pm 09:57 PM
오래된 사진 복원은 인공 지능 기술을 사용하여 오래된 사진을 복구, 향상 및 개선하는 방법입니다. 컴퓨터 비전과 머신러닝 알고리즘을 사용하는 이 기술은 오래된 사진의 손상과 결함을 자동으로 식별하고 복구하여 사진을 더 선명하고 자연스럽고 사실적으로 보이게 합니다. 오래된 사진 복원의 기술 원칙은 주로 다음과 같은 측면을 포함합니다: 1. 이미지 노이즈 제거 및 향상 오래된 사진을 복원할 때 먼저 노이즈를 제거하고 향상시켜야 합니다. 평균 필터링, 가우시안 필터링, 양방향 필터링 등과 같은 이미지 처리 알고리즘 및 필터를 사용하여 노이즈 및 색 반점 문제를 해결하여 사진 품질을 향상시킬 수 있습니다. 2. 이미지 복원 및 수리 오래된 사진에는 긁힘, 균열, 퇴색 등 일부 결함 및 손상이 있을 수 있습니다. 이러한 문제는 이미지 복원 및 복구 알고리즘으로 해결될 수 있습니다.
 영상 초해상도 재구성에 AI 기술 적용
Jan 23, 2024 am 08:06 AM
영상 초해상도 재구성에 AI 기술 적용
Jan 23, 2024 am 08:06 AM
초해상도 이미지 재구성은 CNN(Convolutional Neural Network), GAN(Generative Adversarial Network)과 같은 딥러닝 기술을 사용하여 저해상도 이미지에서 고해상도 이미지를 생성하는 프로세스입니다. 이 방법의 목표는 저해상도 이미지를 고해상도 이미지로 변환하여 이미지의 품질과 디테일을 향상시키는 것입니다. 이 기술은 의료영상, 감시카메라, 위성영상 등 다양한 분야에 폭넓게 활용되고 있다. 초고해상도 영상 재구성을 통해 보다 선명하고 세밀한 영상을 얻을 수 있어 영상 속 대상과 특징을 보다 정확하게 분석하고 식별하는 데 도움이 됩니다. 재구성 방법 초해상도 영상 재구성 방법은 일반적으로 보간 기반 방법과 딥러닝 기반 방법의 두 가지 범주로 나눌 수 있습니다. 1) 보간 기반 방법 보간 기반 초해상 영상 재구성
 Java 개발: 이미지 인식 및 처리 구현 방법
Sep 21, 2023 am 08:39 AM
Java 개발: 이미지 인식 및 처리 구현 방법
Sep 21, 2023 am 08:39 AM
Java 개발: 이미지 인식 및 처리에 대한 실용 가이드 개요: 컴퓨터 비전 및 인공 지능의 급속한 발전으로 인해 이미지 인식 및 처리는 다양한 분야에서 중요한 역할을 합니다. 이 기사에서는 Java 언어를 사용하여 이미지 인식 및 처리를 구현하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. 1. 이미지 인식의 기본 원리 이미지 인식은 컴퓨터 기술을 사용하여 이미지를 분석하고 이해하여 이미지에 있는 개체, 특징 또는 내용을 식별하는 것을 말합니다. 이미지 인식을 수행하기 전에 그림과 같이 몇 가지 기본적인 이미지 처리 기술을 이해해야 합니다.
 PHP 연구 노트: 얼굴 인식 및 이미지 처리
Oct 08, 2023 am 11:33 AM
PHP 연구 노트: 얼굴 인식 및 이미지 처리
Oct 08, 2023 am 11:33 AM
PHP 연구 노트: 얼굴 인식 및 이미지 처리 서문: 인공 지능 기술의 발전으로 얼굴 인식 및 이미지 처리가 화두가 되었습니다. 실제 응용 분야에서 얼굴 인식 및 이미지 처리는 주로 보안 모니터링, 얼굴 잠금 해제, 카드 비교 등에 사용됩니다. 일반적으로 사용되는 서버측 스크립팅 언어인 PHP는 얼굴 인식 및 이미지 처리와 관련된 기능을 구현하는 데에도 사용할 수 있습니다. 이 기사에서는 구체적인 코드 예제를 통해 PHP의 얼굴 인식 및 이미지 처리 과정을 안내합니다. 1. PHP의 얼굴 인식 얼굴 인식은
 C# 개발 시 이미지 처리 및 그래픽 인터페이스 디자인 문제를 처리하는 방법
Oct 08, 2023 pm 07:06 PM
C# 개발 시 이미지 처리 및 그래픽 인터페이스 디자인 문제를 처리하는 방법
Oct 08, 2023 pm 07:06 PM
C# 개발에서 이미지 처리 및 그래픽 인터페이스 디자인 문제를 처리하려면 특정 코드 예제가 필요합니다. 소개: 최신 소프트웨어 개발에서는 이미지 처리 및 그래픽 인터페이스 디자인이 일반적인 요구 사항입니다. 범용 고급 프로그래밍 언어인 C#은 강력한 이미지 처리 및 그래픽 인터페이스 디자인 기능을 갖추고 있습니다. 이 기사는 C#을 기반으로 하며 이미지 처리 및 그래픽 인터페이스 디자인 문제를 처리하는 방법을 논의하고 자세한 코드 예제를 제공합니다. 1. 이미지 처리 문제: 이미지 읽기 및 표시: C#에서는 이미지 읽기 및 표시가 기본 작업입니다. 사용할 수 있습니다.N
 SIFT(척도 불변 특징) 알고리즘
Jan 22, 2024 pm 05:09 PM
SIFT(척도 불변 특징) 알고리즘
Jan 22, 2024 pm 05:09 PM
SIFT(Scale Invariant Feature Transform) 알고리즘은 이미지 처리 및 컴퓨터 비전 분야에서 사용되는 특징 추출 알고리즘입니다. 이 알고리즘은 컴퓨터 비전 시스템의 객체 인식 및 일치 성능을 향상시키기 위해 1999년에 제안되었습니다. SIFT 알고리즘은 강력하고 정확하며 이미지 인식, 3차원 재구성, 표적 탐지, 비디오 추적 및 기타 분야에서 널리 사용됩니다. 여러 스케일 공간에서 키포인트를 감지하고 키포인트 주변의 로컬 특징 설명자를 추출하여 스케일 불변성을 달성합니다. SIFT 알고리즘의 주요 단계에는 스케일 공간 구성, 핵심 포인트 탐지, 핵심 포인트 위치 지정, 방향 할당 및 특징 설명자 생성이 포함됩니다. 이러한 단계를 통해 SIFT 알고리즘은 강력하고 고유한 특징을 추출하여 효율적인 이미지 처리를 달성할 수 있습니다.
