

고성능 자바스크립트 노트, 데이터 저장 및 접속 성능 최적화_자바스크립트 기술

지역 변수는 함수 내부에 정의된 변수로도 이해될 수 있습니다. 지역 변수에 액세스하는 것은 범위 체인의 첫 번째 변수 개체에 위치하기 때문에 범위 외부에 있는 변수보다 빠릅니다. 이 기사를 읽을 수 있습니다). 변수가 범위 체인에 깊을수록 액세스하는 데 시간이 오래 걸립니다. 전역 변수는 범위 체인의 마지막 변수 개체이기 때문에 항상 가장 느립니다.
각 데이터 유형에 액세스하려면 성능 가격이 필요합니다. 직접 수량 및 지역 변수는 기본적으로 저렴하지만 배열 항목 및 개체 멤버에 액세스하는 비용은 더 비쌉니다. 아래 그림은 다양한 브라우저가 이러한 네 가지 데이터 유형에 대해 200,000개의 작업을 수행하는 데 걸린 시간을 보여줍니다.
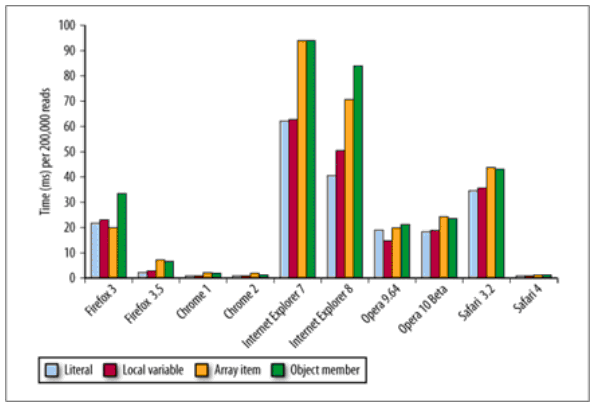
먼저 객체 멤버의 접근 과정을 이해해야 합니다. 실제로 함수는 특수 개체이므로 개체 멤버에 대한 액세스는 함수의 내부 변수에 대한 액세스와 유사합니다. 전자는 프로토타입 체인이고 후자는 범위 체인입니다. 체인 방법의 약간의 차이점이 있습니다.
객체 멤버에는 속성과 메서드가 포함되어 있습니다. 멤버가 함수이면 메서드라고 하고, 그렇지 않으면 속성이라고 합니다.
JavaScript의 객체는 프로토타입(프로토타입 자체가 객체임)을 기반으로 하며 프로토타입은 다른 객체의 기초입니다. Object 객체 또는 기타 JS 내장 객체(var obj=new Object() 또는 var obj={})를 인스턴스화하면 인스턴스 obj의 프로토타입이 브라우저 FF, Safari 및 Chrome에 의해 자동으로 생성됩니다. obj를 전달할 수 있습니다. __proto__ 속성(Object.prototype과 동일)은 이 프로토타입에 액세스할 수 있으며, 각 인스턴스가 프로토타입 개체의 멤버를 공유할 수 있는 것은 바로 이 프로토타입 때문입니다. 예:
var book = {
name:" Javascript Book",
getName = function(){
return this.name;
이 코드에서 book 객체에는 두 개의 전용 멤버, 즉 속성 이름이 있습니다. 그리고 getName 메소드. book 객체는 toString 멤버를 정의하지 않지만 호출 시 오류가 발생하지 않습니다. 이유는 book 객체가 프로토타입 객체의 멤버를 상속하기 때문입니다. 책 객체와 프로토타입의 관계는 다음과 같습니다.
book 객체 멤버 toString에 액세스하는 과정은 다음과 같습니다. book.toString()이 호출되면 백그라운드는 인스턴스 book 자체에서 시작하여 "toString"이라는 멤버를 검색합니다. "toString"이라는 멤버가 책에서 발견되면 검색이 종료됩니다. 그렇지 않으면 __proto__가 가리키는 프로토타입 객체로 검색이 계속됩니다. Object의 프로토타입 객체에서 해당 멤버를 찾을 수 없다는 의미입니다. 한정되지 않은. 이러한 방식으로 book은 프로토타입 객체가 소유한 모든 속성이나 메서드에 액세스할 수 있습니다.
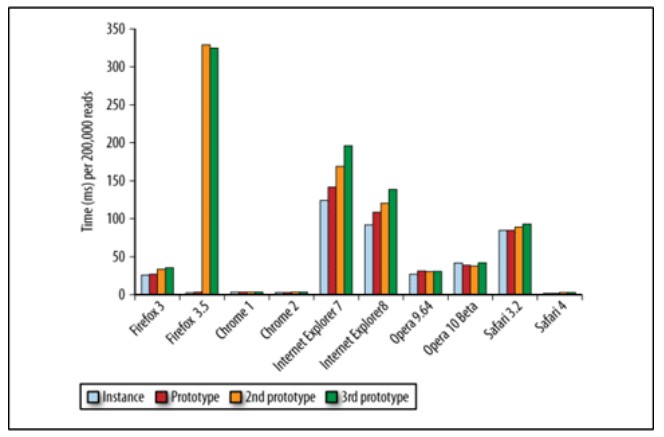
 객체의 또 다른 고급 사용법은 시뮬레이션 클래스와 상속 클래스입니다. 저는 이런 방식으로 사용되는 객체를 객체 클래스라고 부르는 것을 좋아합니다. 객체 클래스 상속은 주로 프로토타입 체인에 의존하여 수행됩니다. 추가 세부 설명이 필요한 지식 포인트가 너무 많습니다. 위의 객체 멤버 검색 과정을 통해 프로토타입 체인이 깊어질수록 객체 멤버에 접근하는 속도는 느려진다. 다음 그림은 프로토타입 체인의 객체 멤버 깊이와 액세스 시간 간의 관계를 보여줍니다.
객체의 또 다른 고급 사용법은 시뮬레이션 클래스와 상속 클래스입니다. 저는 이런 방식으로 사용되는 객체를 객체 클래스라고 부르는 것을 좋아합니다. 객체 클래스 상속은 주로 프로토타입 체인에 의존하여 수행됩니다. 추가 세부 설명이 필요한 지식 포인트가 너무 많습니다. 위의 객체 멤버 검색 과정을 통해 프로토타입 체인이 깊어질수록 객체 멤버에 접근하는 속도는 느려진다. 다음 그림은 프로토타입 체인의 객체 멤버 깊이와 액세스 시간 간의 관계를 보여줍니다.
위 그림에서 알 수 있듯이 프로토타입 체인의 각 계층은 성능 손실을 증가시키므로 객체 멤버 횡단과 같은 작업은 매우 비쌉니다. 일반적으로 사용되며 성능을 많이 소모하는 또 다른 접근 방식은 개체 멤버(예: window.location.href)를 중첩하는 것입니다. 가장 좋은 접근 방식은 클릭 수를 줄이는 것입니다. 예를 들어 location.href는 window.location.href보다 빠릅니다.
 한 문장으로 요약하자면, 프로토타입 체인의 속성이나 메서드가 깊을수록 액세스 속도가 느려집니다. 해결 방법은 자주 사용되는 개체 멤버, 배열 항목 및 범위 외부의 변수를 지역 변수에 저장한 다음 이 지역 변수에 액세스하는 것입니다.
한 문장으로 요약하자면, 프로토타입 체인의 속성이나 메서드가 깊을수록 액세스 속도가 느려집니다. 해결 방법은 자주 사용되는 개체 멤버, 배열 항목 및 범위 외부의 변수를 지역 변수에 저장한 다음 이 지역 변수에 액세스하는 것입니다.

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7364
7364
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 localstorage가 데이터를 성공적으로 저장할 수 없는 이유는 무엇입니까?
Jan 03, 2024 pm 01:41 PM
localstorage가 데이터를 성공적으로 저장할 수 없는 이유는 무엇입니까?
Jan 03, 2024 pm 01:41 PM
localstorage에 데이터를 저장하는 것이 항상 실패하는 이유는 무엇입니까? 특정 코드 예제가 필요합니다. 프런트엔드 개발에서는 사용자 경험을 개선하고 후속 데이터 액세스를 용이하게 하기 위해 브라우저 측에 데이터를 저장해야 하는 경우가 많습니다. Localstorage는 클라이언트 측 데이터 저장을 위해 HTML5에서 제공하는 기술로, 페이지를 새로 고치거나 닫은 후 데이터를 저장하고 데이터 지속성을 유지하는 간단한 방법을 제공합니다. 그러나 데이터 저장을 위해 로컬 저장소를 사용할 때 때로는
 MySQL에서 데이터의 다형성 저장 및 다차원 쿼리를 구현하는 방법은 무엇입니까?
Jul 31, 2023 pm 09:12 PM
MySQL에서 데이터의 다형성 저장 및 다차원 쿼리를 구현하는 방법은 무엇입니까?
Jul 31, 2023 pm 09:12 PM
MySQL에서 데이터의 다형성 저장 및 다차원 쿼리를 구현하는 방법은 무엇입니까? 실제 애플리케이션 개발에서 데이터의 다형성 저장 및 다차원 쿼리는 매우 일반적인 요구 사항입니다. 일반적으로 사용되는 관계형 데이터베이스 관리 시스템인 MySQL은 다형성 스토리지 및 다차원 쿼리를 구현하는 다양한 방법을 제공합니다. 이 기사에서는 MySQL을 사용하여 데이터의 다형성 저장 및 다차원 쿼리를 구현하는 방법을 소개하고 해당 코드 예제를 제공하여 독자가 이를 빠르게 이해하고 사용할 수 있도록 돕습니다. 1. 다형성 스토리지(Polymorphic Storage) 다형성 스토리지는 동일한 분야에 서로 다른 유형의 데이터를 저장하는 기술을 말합니다.
 MongoDB에서 데이터의 이미지 저장 및 처리 기능을 구현하는 방법
Sep 22, 2023 am 10:30 AM
MongoDB에서 데이터의 이미지 저장 및 처리 기능을 구현하는 방법
Sep 22, 2023 am 10:30 AM
MongoDB에서 이미지 저장 및 데이터 처리 기능을 구현하는 방법 개요: 최신 데이터 애플리케이션 개발에서 이미지 처리 및 저장은 일반적인 요구 사항입니다. 널리 사용되는 NoSQL 데이터베이스인 MongoDB는 개발자가 해당 플랫폼에서 이미지 저장 및 처리를 구현할 수 있는 기능과 도구를 제공합니다. 이 기사에서는 MongoDB에서 이미지 저장 및 데이터 처리 기능을 구현하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. 이미지 저장: MongoDB에서는 GridFS를 사용할 수 있습니다.
 Aerospike 캐싱 기술에 대해 알아보기
Jun 20, 2023 am 11:28 AM
Aerospike 캐싱 기술에 대해 알아보기
Jun 20, 2023 am 11:28 AM
디지털 시대가 도래하면서 빅데이터는 사회 각계각층에서 없어서는 안 될 필수 요소가 되었습니다. 대용량 데이터 처리를 위한 솔루션으로 캐싱 기술의 중요성이 점점 부각되고 있습니다. Aerospike는 고성능 캐싱 기술입니다. 이 기사에서는 Aerospike 캐싱 기술의 원리, 특성 및 응용 시나리오에 대해 자세히 알아봅니다. 1. Aerospike 캐싱 기술의 원리 Aerospike는 메모리와 플래시 메모리 기반의 Key-Value 데이터베이스를 사용합니다.
 대규모 AI 모델 시대, 새로운 데이터 저장 기반으로 교육, 과학 연구의 디지털 지능 전환 촉진
Jul 21, 2023 pm 09:53 PM
대규모 AI 모델 시대, 새로운 데이터 저장 기반으로 교육, 과학 연구의 디지털 지능 전환 촉진
Jul 21, 2023 pm 09:53 PM
AIGC(Generative AI)는 일반 인공지능(AI)의 새로운 시대를 열었습니다. 대형 모델을 중심으로 한 경쟁은 더욱 치열해졌습니다. 컴퓨팅 인프라가 경쟁의 주요 초점이 되었으며, 권력의 각성은 점점 더 업계의 합의가 되었습니다. 새로운 시대에는 대규모 모델이 단일 양식에서 다중 양식으로 이동하고 매개변수 및 교육 데이터 세트의 크기가 기하급수적으로 증가하며 동시에 대규모 비정형 데이터에는 고성능 혼합 로드 기능의 지원이 필요합니다. 데이터 집약적 새로운 패러다임이 인기를 얻고 있으며, 슈퍼컴퓨팅, 고성능 컴퓨팅(HPC)과 같은 애플리케이션 시나리오가 점점 더 심화되고 있습니다. 기존 데이터 스토리지 기반은 계속해서 업그레이드되는 요구 사항을 더 이상 충족할 수 없습니다. 컴퓨팅 파워, 알고리즘, 데이터가 인공지능 발전을 이끄는 '트로이카'라면, 외부 환경의 거대한 변화 속에서 이 세 가지가 시급히 역동성을 되찾아야 한다.
 Redis와 Golang 간의 상호 작용: 빠른 데이터 저장 및 검색을 달성하는 방법
Jul 30, 2023 pm 05:18 PM
Redis와 Golang 간의 상호 작용: 빠른 데이터 저장 및 검색을 달성하는 방법
Jul 30, 2023 pm 05:18 PM
Redis와 Golang의 상호 작용: 빠른 데이터 저장 및 검색을 달성하는 방법 소개: 인터넷의 급속한 발전으로 인해 데이터 저장 및 검색은 다양한 응용 분야에서 중요한 요구 사항이 되었습니다. 이러한 맥락에서 Redis는 중요한 데이터 저장 미들웨어가 되었으며 Golang은 효율적인 성능과 사용 편의성으로 인해 점점 더 많은 개발자의 선택이 되었습니다. 이 기사에서는 독자들에게 Redis를 통해 Golang과 상호 작용하여 빠른 데이터 저장 및 검색을 달성하는 방법을 소개합니다. 1.다시
 dat 파일은 어떤 유형의 파일입니까?
Feb 19, 2024 am 11:32 AM
dat 파일은 어떤 유형의 파일입니까?
Feb 19, 2024 am 11:32 AM
dat 파일은 다양한 유형의 데이터를 저장하는 데 사용할 수 있는 범용 데이터 파일 형식입니다. dat 파일에는 텍스트, 이미지, 오디오 및 비디오와 같은 다양한 데이터 형식이 포함될 수 있습니다. 다양한 응용 프로그램과 운영 체제에서 널리 사용됩니다. dat 파일은 일반적으로 텍스트가 아닌 바이트 단위로 데이터를 저장하는 바이너리 파일입니다. 이는 dat 파일을 수정하거나 해당 내용을 텍스트 편집기를 통해 직접 볼 수 없음을 의미합니다. 대신 dat 파일의 데이터를 처리하고 구문 분석하려면 특정 소프트웨어나 도구가 필요합니다. 디
 효율적인 데이터 압축 및 데이터 저장을 위해 C++를 사용하는 방법은 무엇입니까?
Aug 25, 2023 am 10:24 AM
효율적인 데이터 압축 및 데이터 저장을 위해 C++를 사용하는 방법은 무엇입니까?
Aug 25, 2023 am 10:24 AM
효율적인 데이터 압축 및 데이터 저장을 위해 C++를 사용하는 방법은 무엇입니까? 서문: 데이터 양이 증가함에 따라 데이터 압축 및 데이터 저장의 중요성이 점점 커지고 있습니다. C++에는 효율적인 데이터 압축 및 저장을 달성하는 방법이 많이 있습니다. 이 기사에서는 C++의 몇 가지 일반적인 데이터 압축 알고리즘과 데이터 저장 기술을 소개하고 해당 코드 예제를 제공합니다. 1. 데이터 압축 알고리즘 1.1 허프만 코딩 기반의 압축 알고리즘 허프만 코딩은 가변 길이 코딩 기반의 데이터 압축 알고리즘이다. 이는 더 높은 빈도의 문자를 쌍으로 연결하여 수행됩니다.
