

PHP 长稿子分页 手动插入分页标签

PHP 长文章分页 手动插入分页标签
<?php $contents = $rs['content']; function conpage($contents) { $pagesss='#page#'; //设定分页标签 $a=strpos($contents,$pagesss); if($a){ $con=explode($pagesss,$contents); $cons=count($con); @$p = ceil($_GET['p']); if(!$p||$p<0) $p=1; $url=$_SERVER["REQUEST_URI"]; $parse_url=parse_url($url); $url_query=$parse_url["query"]; if($url_query){ $url_query=ereg_replace("(^|&)p=$p","",$url_query); $url=str_replace($parse_url["query"],$url_query,$url); if($url_query) $url.="&p"; else $url.="p"; }else { $url.="?p"; } if($cons<=1) return false;//只有一页时不显示分页 $pagenav="<div class=\"lyztpage\">"; for($i=1;$i'.$p.''; }else{ $pagenav.="<a href="%24url=%24i">$i</a>"; } } $pagenav.=""; return $con[$p-1].$pagenav; }else{ return $contents; } } echo conpage($contents); ?>
핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7360
7360
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 Jul 25, 2023 am 09:05 AM
Jul 25, 2023 am 09:05 AM
PHP 기능 소개 - get_headers(): URL의 응답 헤더 정보 얻기 개요: PHP 개발에서는 웹 페이지나 원격 리소스의 응답 헤더 정보를 얻어야 하는 경우가 많습니다. PHP 함수 get_headers()를 사용하면 대상 URL의 응답 헤더 정보를 쉽게 얻고 이를 배열 형식으로 반환할 수 있습니다. 이 기사에서는 get_headers() 함수의 사용법을 소개하고 관련 코드 예제를 제공합니다. get_headers() 함수 사용법: get_header
 몇 단계만으로 Steam ID를 얻는 방법은 무엇입니까?
May 08, 2023 pm 11:43 PM
몇 단계만으로 Steam ID를 얻는 방법은 무엇입니까?
May 08, 2023 pm 11:43 PM
요즘에는 게임을 좋아하는 많은 Windows 사용자들이 Steam 클라이언트에 접속하여 좋은 게임을 검색하고 다운로드하여 플레이할 수 있습니다. 그러나 많은 사용자의 프로필이 정확히 동일한 이름을 가질 수 있으므로 프로필을 찾거나 Steam 프로필을 다른 제3자 계정에 연결하거나 Steam 포럼에 가입하여 콘텐츠를 공유하기가 어렵습니다. 프로필에는 고유한 17자리 ID가 할당되며, 이는 동일하게 유지되며 사용자가 언제든지 변경할 수 없는 반면, 사용자 이름이나 맞춤 URL은 변경할 수 있습니다. 그럼에도 불구하고 일부 사용자는 자신의 Steamid를 모르므로 이를 아는 것이 중요합니다. 계정의 Steamid를 찾는 방법을 모르더라도 당황하지 마세요. 이 기사에서는
 e의 NameResolutionError(self.host, self, e) 이유와 해결 방법
Mar 01, 2024 pm 01:20 PM
e의 NameResolutionError(self.host, self, e) 이유와 해결 방법
Mar 01, 2024 pm 01:20 PM
오류의 원인은 urllib3 라이브러리의 예외 유형인 NameResolutionError(self.host,self,e)frome입니다. 이 오류의 원인은 DNS 확인에 실패했기 때문입니다. 해결을 찾을 수 없습니다. 이는 입력한 URL 주소가 정확하지 않거나 DNS 서버를 일시적으로 사용할 수 없기 때문에 발생할 수 있습니다. 이 오류를 해결하는 방법 이 오류를 해결하는 방법은 여러 가지가 있습니다. 입력한 URL 주소가 올바른지 확인하고 액세스할 수 있는지 확인하십시오. DNS 서버를 사용할 수 있는지 확인하십시오. 명령줄에서 "ping" 명령을 사용해 볼 수 있습니다. DNS 서버를 사용할 수 있는지 테스트하려면 프록시 뒤에 있는 경우 호스트 이름 대신 IP 주소를 사용하여 웹사이트에 액세스해 보세요.
 Java에서 URL 인코딩 및 디코딩을 사용하는 방법
May 08, 2023 pm 05:46 PM
Java에서 URL 인코딩 및 디코딩을 사용하는 방법
May 08, 2023 pm 05:46 PM
url을 사용하여 java.net.URLDecoder.decode(url, 디코딩 형식) 클래스 decoder.decoding 인코딩 및 디코딩 방법을 인코딩 및 디코딩합니다. 일반 문자열로 변환하는 URLEncoder.decode(url, 인코딩 형식)는 일반 문자열을 지정된 형식의 문자열로 변환합니다. packagecom.zixue.springbootmybatis.test;importjava.io.UnsupportedEncodingException;importjava.net.URLDecoder;importjava.net. URL인코더
 HTML과 URL의 차이점은 무엇입니까
Mar 06, 2024 pm 03:06 PM
HTML과 URL의 차이점은 무엇입니까
Mar 06, 2024 pm 03:06 PM
차이점: 1. 정의가 다릅니다. url은 균일한 리소스 위치 지정자이고 html은 하이퍼텍스트 마크업 언어입니다. 2. html에는 여러 개의 URL이 있을 수 있지만 하나의 url에는 단 하나의 html 페이지만 존재할 수 있습니다. 웹 페이지이고 url은 웹 사이트 주소를 나타냅니다.
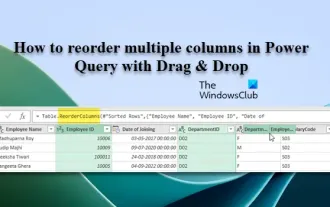 끌어서 놓기를 통해 파워 쿼리에서 여러 열의 순서를 바꾸는 방법
Mar 14, 2024 am 10:55 AM
끌어서 놓기를 통해 파워 쿼리에서 여러 열의 순서를 바꾸는 방법
Mar 14, 2024 am 10:55 AM
이 문서에서는 끌어서 놓기를 통해 PowerQuery에서 여러 열의 순서를 바꾸는 방법을 보여줍니다. 다양한 소스에서 데이터를 가져올 때 열의 순서가 원하는 순서가 아닌 경우가 많습니다. 열을 다시 정렬하면 분석 또는 보고 요구 사항에 맞는 논리적 순서로 열을 정렬할 수 있을 뿐만 아니라 데이터의 가독성이 향상되고 필터링, 정렬, 계산 수행 등의 작업 속도가 빨라집니다. Excel에서 여러 열을 다시 정렬하는 방법은 무엇입니까? Excel에서 열을 재정렬하는 방법에는 여러 가지가 있습니다. 열 머리글을 선택하고 원하는 위치로 끌기만 하면 됩니다. 그러나 이 접근 방식은 많은 열이 포함된 대규모 테이블을 처리할 때 번거로울 수 있습니다. 열을 보다 효율적으로 다시 정렬하려면 향상된 쿼리 편집기를 사용할 수 있습니다. 쿼리 개선
 Scrapy 최적화 팁: 중복 URL 크롤링을 줄이고 효율성을 높이는 방법
Jun 22, 2023 pm 01:57 PM
Scrapy 최적화 팁: 중복 URL 크롤링을 줄이고 효율성을 높이는 방법
Jun 22, 2023 pm 01:57 PM
Scrapy는 인터넷에서 대량의 데이터를 얻는 데 사용할 수 있는 강력한 Python 크롤러 프레임워크입니다. 그러나 Scrapy를 개발할 때 중복된 URL을 크롤링하는 문제에 자주 직면하게 되는데, 이는 많은 시간과 자원을 낭비하고 효율성에 영향을 미칩니다. 이 기사에서는 중복 URL의 크롤링을 줄이고 Scrapy 크롤러의 효율성을 향상시키는 몇 가지 Scrapy 최적화 기술을 소개합니다. 1. Scrapy 크롤러의 start_urls 및 allowed_domains 속성을 사용하여
 SpringBoot 다중 컨트롤러에 URL 접두사를 추가하는 방법
May 12, 2023 pm 06:37 PM
SpringBoot 다중 컨트롤러에 URL 접두사를 추가하는 방법
May 12, 2023 pm 06:37 PM
서문 어떤 경우에는 서비스 컨트롤러의 접두사가 일관됩니다. 예를 들어 모든 URL의 접두사는 /context-path/api/v1이고 일부 URL에는 통합 접두사를 추가해야 합니다. 가능한 해결책은 서비스의 context-path를 수정하고 api/v1을 context-path에 추가하는 것입니다. 전역 접두사를 수정하면 위의 문제를 해결할 수 있지만 URL에 여러 접두사가 있는 경우 단점이 있습니다. URL에는 접두사가 필요합니다. api/v2인 경우 서비스의 일부 정적 리소스에 api/v1을 추가하지 않으려면 구별할 수 없습니다. 다음은 사용자 정의 주석을 사용하여 특정 URL 접두어를 균일하게 추가합니다. 하나,
