

Thinkphp 3.2 中词分词 加权搜寻

Thinkphp 3.2 中词分词 加权搜索
原文地址:http://www.cnblogs.com/kekukele/p/4544349.html
前段时间,利用业余时间做了一个磁力搜索的网站Btdog,其中使用到了简单的中文分词与加权搜索,在这里分享给大家,供大家参考。
在我的网站中,中文分词使用的是SCWS分词系统,这个分词系统提供PHP两种使用方式:一种是你可以采用源码安装,具体安装步骤请参考这里;
另外一种是使用其提供的API接口,具体方法参考这里。
下面,我们假设你已经掌握了SCWS的使用,事实上,其使用也非常简单,若你不会其使用,也不影响本文下面的阅读。
SCWS系统中其每个分好的词包括以下属性/键值:
- word 词的内容
- off 该词在未分词文本中的偏移位置
- idf 该词的 IDF 值
- attr 词性 (北大标注格式) 参见这里。
在这里我们重点介绍下分词属性中的idf,这个是我们在我们的分词算法中需要用到的。
IDF全称inverse document frequency(逆向文档频率)是一个词普遍重要性的度量,某一特定词的IDF值,用总文件数除以包含该词的文章数量,再将得到的商取对数(log)。计算公式:IDF = log(D/Dt),D为文章总数,Dt为该词出现的文章数量。IDF的主要思想是:如果包含词条t的文档越少,也就是Dt越小,IDF越大,则说明词条t具有很好的类别区分能力。
我们举例说明下,如 搜索内容 ”复仇者的联盟“,其SCWS的分词结果如下:

可以看出,其分词结果中,关键词”复仇者“的idf为9.06,最具区分能力,而关键词”的“的idf值为0,基本没有区分能力,”联盟“的idf为4.34也具有较强的区别能力。因此,我们在我们的分词搜索中,可以简单地使用idf值作为加权排序的依据。
在scws分词系统中,其idf的取值为0-10,因此在我们下面给出的算法中,我们把内容全文匹配的权重设为10,即最大。其他分词后关键词的权重值设为其idf值,然后根据权重大小将结果逆序排列。这要我们就实现了简单的中文分词加权排序。核心代码具体如下:
<em id="__mceDel"><em id="__mceDel"> [email protected]:需要分词的内容<em id="__mceDel"> <br>//Return:mysql查询条件字符串,加权排序字符串,关键词</em> <br> <span style="color: #0000ff;">private</span> <span style="color: #0000ff;">function</span> split_words(<span style="color: #800080;">$text</span><span style="color: #000000;">){ </span><span style="color: #800080;">$split_words</span> =<span style="color: #000000;"> scws_new(); </span><span style="color: #800080;">$split_words</span>->set_charset('utf-8'<span style="color: #000000;">); </span><span style="color: #800080;">$split_words</span>->set_ignore(<span style="color: #0000ff;">true</span><span style="color: #000000;">); </span><span style="color: #800080;">$split_words</span>->set_dict('/usr/local/scws/etc/dict.utf8.xdb'<span style="color: #000000;">); </span><span style="color: #800080;">$split_words</span>->set_rule('/usr/local/scws/etc/rules.utf8.ini'<span style="color: #000000;">); </span><span style="color: #800080;">$split_words</span>->send_text(<span style="color: #800080;">$text</span><span style="color: #000000;">); </span><span style="color: #800080;">$weight</span>=10<span style="color: #000000;">; </span><span style="color: #800080;">$condition</span>['where'] = "name LIKE '%".<span style="color: #800080;">$text</span>."%'"<span style="color: #000000;">; </span><span style="color: #800080;">$condition</span>['order'] = "(CASE WHEN name LIKE '%".<span style="color: #800080;">$text</span>."%' THEN <span style="color: #800080;">$weight</span> ELSE 0 END)"<span style="color: #000000;">; //设置全文匹配最大权重</span> <span style="color: #0000ff;">while</span> (<span style="color: #800080;">$words_result</span> = <span style="color: #800080;">$split_words</span>-><span style="color: #000000;">get_result()) { </span><span style="color: #0000ff;">foreach</span>(<span style="color: #800080;">$words_result</span> <span style="color: #0000ff;">as</span> <span style="color: #800080;">$word_arr</span><span style="color: #000000;">){</span> <span style="color: #800080;">$condition</span>['where'] .= " OR name LIKE '%".<span style="color: #800080;">$word_arr</span>['word']."%'"<span style="color: #000000;">;<br> //设置分词后关键词的权重为其idf的值<br></span> <span style="color: #800080;">$condition</span>['order'] .= " + (CASE WHEN name LIKE '%".<span style="color: #800080;">$word_arr</span>['word']."%' THEN ".<span style="color: #800080;">$word_arr</span>['idf']." ELSE 0 END)"<span style="color: #000000;">; </span> <span style="color: #800080;">$condition</span>['keywords'][<span style="color: #800080;">$cnt</span>++] = <span style="color: #800080;">$word_arr</span>['word'<span style="color: #000000;">]; } } </span><span style="color: #800080;">$split_words</span>-><span style="color: #000000;">close(); </span><span style="color: #0000ff;">return</span> <span style="color: #800080;">$condition</span><span style="color: #000000;">; }</span></em></em>当然,更复杂的分词还要考虑词的词频TF,不过即使简单的这样,我们也基本能达到比较好的效果了,具体效果,大家可以到http://btdog.com.cn体验下。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7711
7711
 15
1640
14
1394
52
1288
25
1232
29
15
1640
14
1394
52
1288
25
1232
29

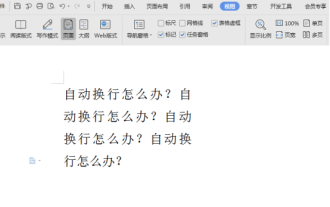 단어 자동 줄 바꿈을 취소하는 방법
Mar 19, 2024 pm 10:16 PM
단어 자동 줄 바꿈을 취소하는 방법
Mar 19, 2024 pm 10:16 PM
Word 문서의 내용을 편집할 때 줄이 자동으로 줄바꿈될 수 있습니다. 이때 조정이 이루어지지 않으면 편집에 큰 영향을 미치고 사람들이 무슨 일이 일어나고 있는 걸까요? 사실, 눈금자의 문제입니다. 아래에서는 단어 자동 줄 바꿈을 취소하는 방법에 대한 해결 방법을 소개하겠습니다. 여러분에게 도움이 되기를 바랍니다! Word 문서를 열고 텍스트를 입력한 후 복사하여 붙여넣으려고 하면 텍스트가 새 줄로 건너뛸 수 있습니다. 이 경우 이 문제를 해결하려면 설정을 조정해야 합니다. 2. 이 문제를 해결하려면 먼저 이 문제의 원인을 알아야 합니다. 이때 도구 모음 아래에서 보기를 클릭합니다. 3. 그런 다음 아래의 "눈금자" 옵션을 클릭하세요. 4. 이때 여러 개의 원뿔형 마커가 있는 문서 위에 눈금자가 나타나는 것을 볼 수 있습니다.
 Word에서 눈금자를 표시하는 방법과 눈금자 조작 방법을 자세히 설명합니다!
Mar 20, 2024 am 10:46 AM
Word에서 눈금자를 표시하는 방법과 눈금자 조작 방법을 자세히 설명합니다!
Mar 20, 2024 am 10:46 AM
우리는 Word를 사용할 때 내용을 더 아름답게 편집하기 위해 눈금자를 사용하는 경우가 많습니다. Word의 눈금자에는 문서의 페이지 여백, 단락 들여쓰기, 탭 등을 표시하고 조정하는 데 사용되는 가로 눈금자와 세로 눈금자가 포함되어 있다는 것을 알아야 합니다. 그렇다면 Word에서 눈금자를 어떻게 표시합니까? 다음으로 눈금자 표시 설정 방법을 가르쳐 드리겠습니다. 도움이 필요한 학생들은 빨리 모아야 합니다! 단계는 다음과 같습니다: 1. 먼저 단어 눈금자를 불러와야 합니다. 기본 단어 문서에는 단어 눈금자가 표시되지 않습니다. 단어에서는 [보기] 버튼만 클릭하면 됩니다. 2. 그런 다음 [Ruler] 옵션을 찾아 확인합니다. 이런 식으로 단어 눈금자를 조정할 수 있습니다! 예 혹은 아니오
 Word 문서에 자필 서명을 추가하는 방법
Mar 20, 2024 pm 08:56 PM
Word 문서에 자필 서명을 추가하는 방법
Mar 20, 2024 pm 08:56 PM
Word 문서는 강력한 기능으로 인해 널리 사용됩니다. Word에는 그림, 표 등 다양한 형식을 삽입할 수 있을 뿐만 아니라, 이제 많은 파일의 무결성과 신뢰성을 위해 문서 끝에 수동 서명이 필요합니다. 복잡한 문제를 해결하는 방법 오늘은 워드 문서에 자필 서명을 추가하는 방법을 가르쳐 드리겠습니다. 스캐너, 카메라 또는 휴대폰을 사용하여 자필 서명을 스캔하거나 사진을 찍은 다음 PS 또는 기타 이미지 편집 소프트웨어를 사용하여 이미지에서 필요한 자르기를 수행합니다. 2. 필기 서명을 삽입하려는 Word 문서에서 "삽입 - 그림 - 파일에서"를 선택하고 잘린 필기 서명을 선택합니다. 3. 필기 서명 사진을 더블 클릭(또는 사진을 마우스 오른쪽 버튼으로 클릭하고 "그림 형식 설정" 선택)하면 "그림 형식 설정" 팝업이 나타납니다.
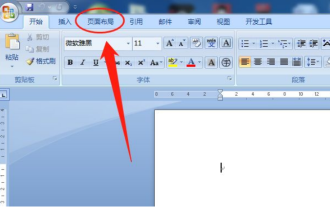 Word의 페이지 여백을 설정하는 방법
Mar 19, 2024 pm 10:00 PM
Word의 페이지 여백을 설정하는 방법
Mar 19, 2024 pm 10:00 PM
사무용 소프트웨어 중 Word는 가장 일반적으로 사용되는 소프트웨어 중 하나입니다. 우리가 작성하는 텍스트 문서는 일반적으로 Word로 작동됩니다. 일부 문서는 필요에 따라 인쇄하기 전에 레이아웃을 설정해야 합니다. . 더 나은 결과를 만들어냅니다. 그래서 질문은 Word에서 페이지 여백을 어떻게 설정합니까? 여러분의 궁금증을 해결하는 데 도움이 되는 구체적인 강좌 설명이 준비되어 있습니다. 1. 새 워드 문서를 열거나 생성한 후 메뉴바에서 "페이지 레이아웃" 메뉴를 클릭하세요. 2. "페이지 설정" 옵션의 "여백" 버튼을 클릭하세요. 3. 목록에서 일반적으로 사용되는 페이지 여백을 선택합니다. 4. 목록에 적합한 여백이 없으면 "사용자 정의 여백"을 클릭하십시오. 5. "페이지 설정" 대화 상자가 나타나면 각각 "여백" 옵션을 입력합니다.
 단어의 음영 설정은 어디에 있습니까?
Mar 20, 2024 am 08:16 AM
단어의 음영 설정은 어디에 있습니까?
Mar 20, 2024 am 08:16 AM
우리는 사무용으로 워드를 자주 사용하는데, 워드에서 음영 설정이 어디에 있는지 아시나요? 오늘은 구체적인 단계를 여러분과 공유하겠습니다. 와서 살펴보세요, 친구들! 1. 먼저 워드 문서를 열고, 텍스트 단락 정보 중 음영 처리가 필요한 단락을 선택한 후 툴바의 [시작] 버튼을 클릭해 단락 영역을 찾아 오른쪽 드롭다운 버튼을 클릭합니다. (아래 그림의 빨간색 원과 같이) ). 2. 드롭다운 박스 버튼을 클릭한 후, 팝업 메뉴 옵션에서 [테두리 및 음영] 옵션을 클릭하세요(아래 그림의 빨간색 원 참조). 3. 팝업된 [테두리 및 음영] 대화 상자에서 [음영] 옵션을 클릭하세요(아래 그림의 빨간색 원 참조). 4. 채워진 열에서 색상을 선택하십시오
 단어로 점선을 그리는 방법
Mar 19, 2024 pm 10:25 PM
단어로 점선을 그리는 방법
Mar 19, 2024 pm 10:25 PM
Word는 우리 사무실에서 자주 사용하는 소프트웨어입니다. 예를 들어, 큰 기사의 경우 내부 검색 기능을 사용하여 전체 텍스트의 특정 단어가 잘못되었는지 확인할 수 있습니다. , 직접 교체할 수 있도록 문서를 하나씩 변경하고, 문서를 상사에게 제출할 때 문서를 아름답게 꾸미는 등의 작업을 수행할 수 있습니다. 아래에서 편집자가 그림을 그리는 단계를 알려드리겠습니다. Word에서 점선을 함께 배워보세요! 1. 먼저 아래 그림과 같이 컴퓨터에서 document라는 단어를 엽니다. 2. 그런 다음 아래 그림의 빨간색 원에 표시된 대로 문서에 텍스트 문자열을 입력합니다. 3. 다음으로 및 키를 누릅니다. [ctrl+A] 길게 누르기 아래 그림의 빨간색 원과 같이 모든 텍스트를 선택합니다. 4. 메뉴바 상단의 [시작]을 클릭합니다.
 Word에서 아래쪽 화살표를 삭제하는 특정 단계!
Mar 19, 2024 pm 08:50 PM
Word에서 아래쪽 화살표를 삭제하는 특정 단계!
Mar 19, 2024 pm 08:50 PM
일상적인 사무에서 웹사이트의 텍스트 한 부분을 복사해 워드에 직접 붙여넣으면 [아래쪽 화살표]가 보이는 경우가 종종 있는데, 이 [아래쪽 화살표]를 선택하면 삭제할 수 있는데, 너무 많으면 삭제할 수 있다. 그런 기호가 있는데, 화살표를 모두 삭제하는 빠른 방법이 있나요? 그래서 오늘은 Word에서 아래쪽 화살표를 삭제하는 구체적인 단계를 알려드리겠습니다! 우선, Word의 [아래쪽 화살표]는 실제로 [수동 줄 바꿈]을 나타냅니다. 아래 그림과 같이 [아래쪽 화살표]를 모두 [단락 표시] 기호로 바꿀 수 있습니다. 2. 그런 다음 메뉴 모음에서 [찾기 및 바꾸기] 옵션을 선택합니다(아래 그림의 빨간색 원 참조). 3. 그런 다음 [바꾸기] 명령을 클릭하면 팝업 상자가 나타나는데, [특수 기호]를 클릭하세요.
 Word에서 표를 그리는 방법
Mar 19, 2024 pm 11:50 PM
Word에서 표를 그리는 방법
Mar 19, 2024 pm 11:50 PM
Word는 WPS에 비해 매우 강력한 사무용 소프트웨어입니다. 특히 문서 설명이 너무 복잡한 경우에는 일반적으로 Word를 사용하는 것이 더 안전합니다. 그러므로 사회에 들어오면 말을 사용하는 요령을 배워야 합니다. 얼마 전 사촌이 이런 질문을 하더군요. 다른 사람들이 워드를 사용하면서 표를 그리는 모습을 자주 보는데, 꽤 고급스러운 느낌이 듭니다. 그땐 웃겼는데, 실제로는 3단계만 거치면 워드에서 표를 그리는 법을 아시나요? 1. 워드를 열고 표를 삽입할 위치를 선택한 후 상단 메뉴 바에서 "삽입" 옵션을 찾습니다. 2. "테이블" 옵션을 클릭하면 조밀하게 채워진 작은 큐브가 나타납니다.
