php程序优化求建议,执行速度太慢
本帖最后由 zhuzhaodan 于 2013-06-12 18:06:26 编辑
现有
四级词库4000单词txt文档,格式如下
accent n.口音,腔调;重音
acceptable a.可接受的,合意的
acceptance n.接受,验收;承认
access n.接近;通道,入口
accessory n.同谋,从犯;附件
accident n.意外的;事故
accidental a.偶然的;非本质的
现要把英汉分离后分别插入mySQL数据库内,代码如下
<?php<br />
header("Content-type: text/html; charset=utf-8");<br />
$file = dirname(__FILE__)."/siji.txt"; //四级词库文件<br />
if(!file_exists($file)){<br />
echo 'Not exist';<br />
}<br />
else {<br />
$a = array();//存放英汉对照对儿的数组<br />
$lines = file($file);//读取txt到数组,一行为一个英汉对照对<br />
foreach ($lines as $k=>$v){<br />
if(preg_match('/[a-zA-Z]/',$v))//有的行是标题之类的,不是英汉对照,判断后不加到数组a里面<br />
$a[$k] = trim($v);//因为有换行符,去掉<br />
}<br />
$b = array();//2维数组,$b[n][0]为英文,$b[n][1]为释义<br />
foreach($a as $k=>$v){//把a数组的英汉分离,填充到b数组的第二维内<br />
preg_match('/([a-zA-Z]*)\s(.*)/',$v,$matches);//正则英汉分离,matches[1]是英文,matches[2]是释义中文<br />
$b[$k][0] = $matches[1];<br />
$b[$k][1] = $matches[2];<br />
}<br />
$dsn = 'mysql:host=localhost;dbname=test1';<br />
$db = new PDO($dsn,'root','',array(PDO::MYSQL_ATTR_INIT_COMMAND => 'set names utf8'));<br />
foreach($b as $k=>$v){//插入数据库<br />
$db->exec("INSERT INTO siji (en,cn) VALUES ('$v[0]','$v[1]')");//数据库3个字段,id,en是英文,cn是中文<br />
}<br />
<br />
}로그인 후 복사
程序执行时间2分钟左右,求优化建议~我自己感觉正则那部分应该优化不了多少,主要感觉插进数据库这里费时太多,各位高人有方法请不吝赐教,现在程序执行完毕需要
120秒,希望最终优化后能到10秒内,谢谢,4级词库一共才4000对词组,120秒太长了
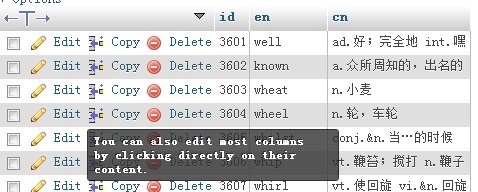
最终效果图:

高人们,因为我比较新手,所以不管从代码上,还是整体思路上都使这个程序运行缓慢,求优化建议,特别是
数据库这里,还有
数组这里,或者有
更好的办法。100分在这里,谢谢!
본 웹사이트의 성명
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.
저자별 최신 기사
-
2025-02-26 03:58:14
-
2025-02-26 03:38:10
-
2025-02-26 03:17:10
-
2025-02-26 02:49:09
-
2025-02-26 01:08:13
-
2025-02-26 00:46:10
-
2025-02-25 23:42:08
-
2025-02-25 22:50:13
-
2025-02-25 21:54:11
-
2025-02-25 20:45:11


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



