

python 中文乱码问题深入分析

在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下:
1. UNICODE (UTF8-16),C854;
2. UTF-8,E59388;
3. GBK,B9FE。
一、python中的str和unicode
一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢?
在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为
u'\u54c8\u54c8'
而str,是一个字节数组,这个字节数组表示的是对unicode对象编码(可以是utf-8、gbk、cp936、GB2312)后的存储的格式。这里它仅仅是一个字节流,没有其它的含义,如果你想使这个字节流显示的内容有意义,就必须用正确的编码格式,解码显示。
例如: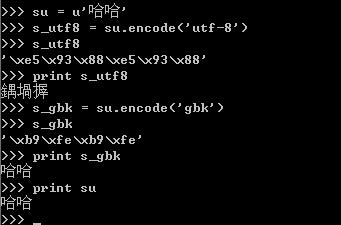
对于unicode对象哈哈进行编码,编码成一个utf-8编码的str-s_utf8,s_utf8就是是一个字节数组,存放的就是'\xe5\x93\x88\xe5\x93\x88',但是这仅仅是一个字节数组,如果你想将它通过print语句输出成哈哈,那你就失望了,为什么呢?
因为print语句它的实现是将要输出的内容传送了操作系统,操作系统会根据系统的编码对输入的字节流进行编码,这就解释了为什么utf-8格式的字符串“哈哈”,输出的是“鍝堝搱”,因为 '\xe5\x93\x88\xe5\x93\x88'用GB2312去解释,其显示的出来就是“鍝堝搱”。这里再强调一下,str记录的是字节数组,只是某种编码的存储格式,至于输出到文件或是打印出来是什么格式,完全取决于其解码的编码将它解码成什么样子。
这里再对print进行一点补充说明:当将一个unicode对象传给print时,在内部会将该unicode对象进行一次转换,转换成本地的默认编码(这仅是个人猜测)
二、str和unicode对象的转换
str和unicode对象的转换,通过encode和decode实现,具体使用如下:
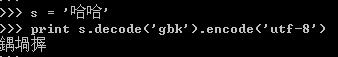
将GBK'哈哈'转换成unicode,然后再转换成UTF8
三、Setdefaultencoding
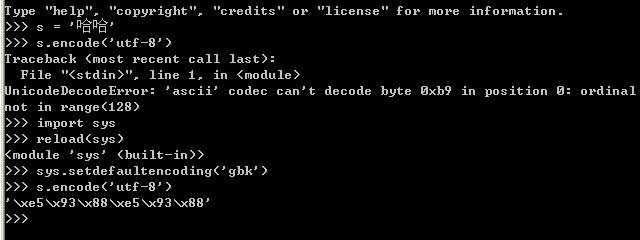
如上图的演示代码所示:
当把s(gbk字符串)直接编码成utf-8的时候,将抛出异常,但是通过调用如下代码:
import sys
reload(sys)
sys.setdefaultencoding('gbk')
后就可以转换成功,为什么呢?在python中str和unicode在编码和解码过程中,如果将一个str直接编码成另一种编码,会先把str解码成unicode,采用的编码为默认编码,一般默认编码是anscii,所以在上面示例代码中第一次转换的时候会出错,当设定当前默认编码为'gbk'后,就不会出错了。
至于reload(sys)是因为Python2.5 初始化后会删除 sys.setdefaultencoding 这个方法,我们需要重新载入。
四、操作不同文件的编码格式的文件
建立一个文件test.txt,文件格式用ANSI,内容为:
abc中文
用python来读取
# coding=gbk
print open("Test.txt").read()
结果:abc中文
把文件格式改成UTF-8:
结果:abc涓枃
显然,这里需要解码:
# coding=gbk
import codecs
print open("Test.txt").read().decode("utf-8")
结果:abc中文
上面的test.txt我是用Editplus来编辑的,但当我用Windows自带的记事本编辑并存成UTF-8格式时,
运行时报错:
Traceback (most recent call last):
File "ChineseTest.py", line 3, in
print open("Test.txt").read().decode("utf-8")
UnicodeEncodeError: 'gbk' codec can't encode character u'\ufeff' in position 0: illegal multibyte sequence
原来,某些软件,如notepad,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF 0xBB 0xBF,即BOM)。
因此我们在读取时需要自己去掉这些字符,python中的codecs module定义了这个常量:
# coding=gbk
import codecs
data = open("Test.txt").read()
if data[:3] == codecs.BOM_UTF8:
data = data[3:]
print data.decode("utf-8")
结果:abc中文
五、文件的编码格式和编码声明的作用
源文件的编码格式对字符串的声明有什么作用呢?这个问题困扰一直困扰了我好久,现在终于有点眉目了,文件的编码格式决定了在该源文件中声明的字符串的编码格式,例如:
str = '哈哈'
print repr(str)
a.如果文件格式为utf-8,则str的值为:'\xe5\x93\x88\xe5\x93\x88'(哈哈的utf-8编码)
b.如果文件格式为gbk,则str的值为:'\xb9\xfe\xb9\xfe'(哈哈的gbk编码)
在第一节已经说过,python中的字符串,只是一个字节数组,所以当把a情况的str输出到gbk编码的控制台时,就将显示为乱码:鍝堝搱;而当把b情况下的str输出utf-8编码的控制台时,也将显示乱码的问题,是什么也没有,也许'\xb9\xfe\xb9\xfe'用utf-8解码显示,就是空白吧。>_
说完文件格式,现在来谈谈编码声明的作用吧,每个文件在最上面的地方,都会用# coding=gbk 类似的语句声明一下编码,但是这个声明到底有什么用呢?到止前为止,我觉得它的作用也就是三个:
#coding:gbk
ss = u'哈哈'
print repr(ss)
print 'ss:%s' % ss
将这个些代码保存成一个utf-8文本,运行,你认为会输出什么呢?大家第一感觉肯定输出的肯定是:
u'\u54c8\u54c8'
ss:哈哈
但是实际上输出是:
u'\u935d\u581d\u6431'
ss:鍝堝搱
为什么会这样,这时候,就是编码声明在作怪了,在运行ss = u'哈哈'的时候,整个过程可以分为以下几步:
1) 获取'哈哈'的编码:由文件编码格式确定,为'\xe5\x93\x88\xe5\x93\x88'(哈哈的utf-8编码形式)
2) 转成 unicode编码的时候,在这个转换的过程中,对于'\xe5\x93\x88\xe5\x93\x88'的解码,不是用utf-8解码,而是用声明编码处指定的编码GBK,将'\xe5\x93\x88\xe5\x93\x88'按GBK解码,得到就是''鍝堝搱'',这三个字的unicode编码就是u'\u935d\u581d\u6431',至止可以解释为什么print repr(ss)输出的是u'\u935d\u581d\u6431' 了。
好了,这里有点绕,我们来分析下一个示例:
#-*- coding:utf-8 -*-
ss = u'哈哈'
print repr(ss)
print 'ss:%s' % ss
将这个示例这次保存成GBK编码形式,运行结果,竟然是:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xb9 in position 0: unexpected code byte
这里为什么会有utf8解码错误呢?想想上个示例也明白了,转换第一步,因为文件编码是GBK,得到的是'哈哈'编码是GBK的编码'\xb9\xfe\xb9\xfe',当进行第二步,转换成 unicode的时候,会用UTF8对'\xb9\xfe\xb9\xfe'进行解码,而大家查utf-8的编码表会发现,utf8编码表(关于UTF- 8解释可参见字符编码笔记:ASCII、UTF-8、UNICODE)中根本不存在,所以会报上述错误。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7319
7319
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 램프 아키텍처에서 Node.js 또는 Python 서비스를 효율적으로 통합하는 방법은 무엇입니까?
Apr 01, 2025 pm 02:48 PM
램프 아키텍처에서 Node.js 또는 Python 서비스를 효율적으로 통합하는 방법은 무엇입니까?
Apr 01, 2025 pm 02:48 PM
많은 웹 사이트 개발자는 램프 아키텍처에서 Node.js 또는 Python 서비스를 통합하는 문제에 직면 해 있습니다. 기존 램프 (Linux Apache MySQL PHP) 아키텍처 웹 사이트 요구 사항 ...
 SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까?
Apr 01, 2025 pm 04:03 PM
SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까?
Apr 01, 2025 pm 04:03 PM
SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까? 토론 Data Crawler에 Scapy Crawler를 사용하는 법을 배울 때 종종 ...
 Python Cross-Platform 데스크탑 응용 프로그램 개발 : 어떤 GUI 라이브러리가 가장 적합합니까?
Apr 01, 2025 pm 05:24 PM
Python Cross-Platform 데스크탑 응용 프로그램 개발 : 어떤 GUI 라이브러리가 가장 적합합니까?
Apr 01, 2025 pm 05:24 PM
Python 크로스 플랫폼 데스크톱 응용 프로그램 개발 라이브러리 선택 많은 Python 개발자가 Windows 및 Linux 시스템 모두에서 실행할 수있는 데스크탑 응용 프로그램을 개발하고자합니다 ...
 Python Process Pool이 동시 TCP 요청을 처리하고 클라이언트가 막히게하는 이유는 무엇입니까?
Apr 01, 2025 pm 04:09 PM
Python Process Pool이 동시 TCP 요청을 처리하고 클라이언트가 막히게하는 이유는 무엇입니까?
Apr 01, 2025 pm 04:09 PM
Python Process Pool은 클라이언트가 갇히게하는 동시 TCP 요청을 처리합니다. 네트워크 프로그래밍에 Python을 사용하는 경우 동시 TCP 요청을 효율적으로 처리하는 것이 중요합니다. ...
 Python functools.partial 객체가 내부적으로 캡슐화 한 원래 함수를 보는 방법?
Apr 01, 2025 pm 04:15 PM
Python functools.partial 객체가 내부적으로 캡슐화 한 원래 함수를 보는 방법?
Apr 01, 2025 pm 04:15 PM
functools.partial in Python의 파이썬 funcTools.partial 객체의 시청 방법을 깊이 탐구하십시오 ...
 파이썬 모래시 그래프 그리기 : 가변적 인 정의되지 않은 오류를 피하는 방법?
Apr 01, 2025 pm 06:27 PM
파이썬 모래시 그래프 그리기 : 가변적 인 정의되지 않은 오류를 피하는 방법?
Apr 01, 2025 pm 06:27 PM
Python : 모래 시계 그래픽 도면 및 입력 검증을 시작 하기이 기사는 모래 시계 그래픽 드로잉 프로그램에서 Python 초보자가 발생하는 변수 정의 문제를 해결합니다. 암호...
 정확한 흰색 원형 영역을 찾기 위해 파이썬에서 고해상도 이미지의 처리를 최적화하는 방법은 무엇입니까?
Apr 01, 2025 pm 06:12 PM
정확한 흰색 원형 영역을 찾기 위해 파이썬에서 고해상도 이미지의 처리를 최적화하는 방법은 무엇입니까?
Apr 01, 2025 pm 06:12 PM
흰색 영역을 찾기 위해 파이썬에서 고해상도 이미지를 처리하는 방법은 무엇입니까? 9000x7000 픽셀의 고해상도 사진 처리, 두 가지 그림을 정확하게 찾는 방법 ...
 파이썬에서 대형 제품 데이터 세트를 효율적으로 계산하고 정렬하는 방법은 무엇입니까?
Apr 01, 2025 pm 08:03 PM
파이썬에서 대형 제품 데이터 세트를 효율적으로 계산하고 정렬하는 방법은 무엇입니까?
Apr 01, 2025 pm 08:03 PM
데이터 변환 및 통계 : 대규모 데이터 세트의 효율적인 처리이 기사는 제품 정보가 포함 된 데이터 목록을 다른 사람으로 변환하는 방법을 자세히 소개합니다 ...
