

node.js 기본 모듈 http, 웹페이지 분석 도구 cherrio는crawler_node.js를 구현합니다.

1. 서문
크롤러에 대한 예비 탐색이라고 합니다. 실제로는 크롤러와 관련된 타사 라이브러리를 사용하지 않으며 주로 node.js 기본 모듈인 http와 웹페이지 분석 도구인 cherrio를 사용합니다. http를 이용하여 해당 URL 경로에 해당하는 웹페이지 리소스를 직접 얻은 후, cherrio를 이용하여 분석합니다. 여기에는 이해를 돕기 위해 내가 연구한 주요 사례를 입력했습니다. 코딩 과정에서 처음으로 jq로 얻은 객체를 forEach를 사용하여 직접 순회했는데, 이는 jq에 해당 메소드가 없고 js 배열만 호출할 수 있었기 때문입니다.
2. 지식 포인트
①: Superagent는 웹페이지를 캡처하는 도구입니다. 나는 아직 그것을 사용하지 않았습니다.
②: 체리오 웹 분석 도구는 문법이 동일하기 때문에 서버측에서는 jQuery로 이해하시면 됩니다.
렌더링
1. 웹페이지 전체 캡쳐
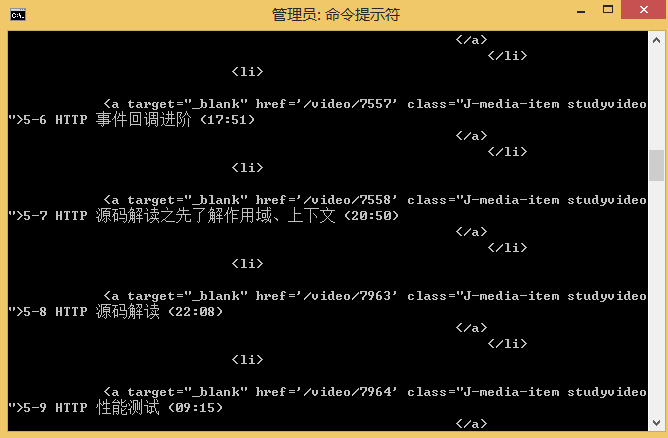
2. 분석된 데이터, 제공된 예시는 사례 구현 예시입니다.
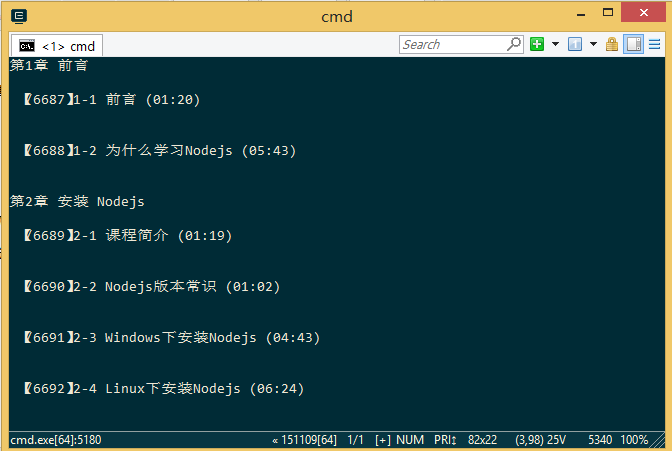
크롤러 초기 소스코드 분석
var http=require('http');
var cheerio=require('cheerio');
var url='http://www.imooc.com/learn/348';
/****************************
打印得到的数据结构
[{
chapterTitle:'',
videos:[{
title:'',
id:''
}]
}]
********************************/
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle=item.chapterTitle;
console.log(chapterTitle+'\n');
item.videos.forEach(function(video){
console.log(' 【'+video.id+'】'+video.title+'\n');
})
});
}
/*************
分析从网页里抓取到的数据
**************/
function filterChapter(html){
var courseData=[];
var $=cheerio.load(html);
var chapters=$('.chapter');
chapters.each(function(item){
var chapter=$(this);
var chapterTitle=chapter.find('strong').text(); //找到章节标题
var videos=chapter.find('.video').children('li');
var chapterData={
chapterTitle:chapterTitle,
videos:[]
};
videos.each(function(item){
var video=$(this).find('.studyvideo');
var title=video.text();
var id=video.attr('href').split('/video')[1];
chapterData.videos.push({
title:title,
id:id
})
})
courseData.push(chapterData);
});
return courseData;
}
http.get(url,function(res){
var html='';
res.on('data',function(data){
html+=data;
})
res.on('end',function(){
var courseData=filterChapter(html);
printCourseInfo(courseData);
})
}).on('error',function(){
console.log('获取课程数据出错');
})
참고:
https://github.com/ alsotang/node-lessons/tree/master/lesson3

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7626
7626
 15
1389
52
89
11
70
19
31
140
15
1389
52
89
11
70
19
31
140

 프론트 엔드 열 용지 영수증에 대한 차량 코드 인쇄를 만나면 어떻게해야합니까?
Apr 04, 2025 pm 02:42 PM
프론트 엔드 열 용지 영수증에 대한 차량 코드 인쇄를 만나면 어떻게해야합니까?
Apr 04, 2025 pm 02:42 PM
프론트 엔드 개발시 프론트 엔드 열지대 티켓 인쇄를위한 자주 묻는 질문과 솔루션, 티켓 인쇄는 일반적인 요구 사항입니다. 그러나 많은 개발자들이 구현하고 있습니다 ...
 누가 더 많은 파이썬이나 자바 스크립트를 지불합니까?
Apr 04, 2025 am 12:09 AM
누가 더 많은 파이썬이나 자바 스크립트를 지불합니까?
Apr 04, 2025 am 12:09 AM
기술 및 산업 요구에 따라 Python 및 JavaScript 개발자에 대한 절대 급여는 없습니다. 1. 파이썬은 데이터 과학 및 기계 학습에서 더 많은 비용을 지불 할 수 있습니다. 2. JavaScript는 프론트 엔드 및 풀 스택 개발에 큰 수요가 있으며 급여도 상당합니다. 3. 영향 요인에는 경험, 지리적 위치, 회사 규모 및 특정 기술이 포함됩니다.
 Demystifying JavaScript : 그것이하는 일과 중요한 이유
Apr 09, 2025 am 12:07 AM
Demystifying JavaScript : 그것이하는 일과 중요한 이유
Apr 09, 2025 am 12:07 AM
JavaScript는 현대 웹 개발의 초석이며 주요 기능에는 이벤트 중심 프로그래밍, 동적 컨텐츠 생성 및 비동기 프로그래밍이 포함됩니다. 1) 이벤트 중심 프로그래밍을 사용하면 사용자 작업에 따라 웹 페이지가 동적으로 변경 될 수 있습니다. 2) 동적 컨텐츠 생성을 사용하면 조건에 따라 페이지 컨텐츠를 조정할 수 있습니다. 3) 비동기 프로그래밍은 사용자 인터페이스가 차단되지 않도록합니다. JavaScript는 웹 상호 작용, 단일 페이지 응용 프로그램 및 서버 측 개발에 널리 사용되며 사용자 경험 및 크로스 플랫폼 개발의 유연성을 크게 향상시킵니다.
 JavaScript를 사용하여 동일한 ID와 동일한 ID로 배열 요소를 하나의 객체로 병합하는 방법은 무엇입니까?
Apr 04, 2025 pm 05:09 PM
JavaScript를 사용하여 동일한 ID와 동일한 ID로 배열 요소를 하나의 객체로 병합하는 방법은 무엇입니까?
Apr 04, 2025 pm 05:09 PM
동일한 ID로 배열 요소를 JavaScript의 하나의 객체로 병합하는 방법은 무엇입니까? 데이터를 처리 할 때 종종 동일한 ID를 가질 필요가 있습니다 ...
 Console.log 출력 결과의 차이 : 두 통화가 다른 이유는 무엇입니까?
Apr 04, 2025 pm 05:12 PM
Console.log 출력 결과의 차이 : 두 통화가 다른 이유는 무엇입니까?
Apr 04, 2025 pm 05:12 PM
Console.log 출력의 차이의 근본 원인에 대한 심층적 인 논의. 이 기사에서는 Console.log 함수의 출력 결과의 차이점을 코드에서 분석하고 그에 따른 이유를 설명합니다. � ...
 Shiseido의 공식 웹 사이트와 같은 시차 스크롤 및 요소 애니메이션 효과를 달성하는 방법은 무엇입니까?
또는:
Shiseido의 공식 웹 사이트와 같은 페이지 스크롤과 함께 애니메이션 효과를 어떻게 달성 할 수 있습니까?
Apr 04, 2025 pm 05:36 PM
Shiseido의 공식 웹 사이트와 같은 시차 스크롤 및 요소 애니메이션 효과를 달성하는 방법은 무엇입니까?
또는:
Shiseido의 공식 웹 사이트와 같은 페이지 스크롤과 함께 애니메이션 효과를 어떻게 달성 할 수 있습니까?
Apr 04, 2025 pm 05:36 PM
이 기사에서 시차 스크롤 및 요소 애니메이션 효과 실현에 대한 토론은 Shiseido 공식 웹 사이트 (https://www.shiseido.co.jp/sb/wonderland/)와 유사하게 달성하는 방법을 살펴볼 것입니다.
 JavaScript는 배우기가 어렵습니까?
Apr 03, 2025 am 12:20 AM
JavaScript는 배우기가 어렵습니까?
Apr 03, 2025 am 12:20 AM
JavaScript를 배우는 것은 어렵지 않지만 어려운 일입니다. 1) 변수, 데이터 유형, 기능 등과 같은 기본 개념을 이해합니다. 2) 마스터 비동기 프로그래밍 및 이벤트 루프를 통해이를 구현하십시오. 3) DOM 운영을 사용하고 비동기 요청을 처리합니다. 4) 일반적인 실수를 피하고 디버깅 기술을 사용하십시오. 5) 성능을 최적화하고 모범 사례를 따르십시오.
 프론트 엔드 개발에서 VSCODE와 유사한 패널 드래그 앤 드롭 조정 기능을 구현하는 방법은 무엇입니까?
Apr 04, 2025 pm 02:06 PM
프론트 엔드 개발에서 VSCODE와 유사한 패널 드래그 앤 드롭 조정 기능을 구현하는 방법은 무엇입니까?
Apr 04, 2025 pm 02:06 PM
프론트 엔드에서 VSCODE와 같은 패널 드래그 앤 드롭 조정 기능의 구현을 탐색하십시오. 프론트 엔드 개발에서 VSCODE와 같은 구현 방법 ...
