

什么是中文分词

中文
什么是中文分词?
众所周知,英文是以词为单位的,词和词之间是靠空格隔开,而中文是以字为单位,句子中所有的字连起来才能描述一个意思。例如,英文句子I am a student,用中文则为:“我是一个学生”。计算机可以很简单通过空格知道student是一个单词,但是不能很容易明白“学”、“生”两个字合起来才表示一个词。把中文的汉字序列切分成有意义的词,就是中文分词,有些人也称为切词。我是一个学生,分词的结果是:我是 一个 学生。
目前主流的中文分词算法有:
1、 基于字符串匹配的分词方法
这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下:
1)正向最大匹配法(由左到右的方向);
2)逆向最大匹配法(由右到左的方向);
3)最少切分(使每一句中切出的词数最小)。
还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。但这种精度还远远不能满足实际的需要。实际使用的分词系统,都是把机械分词作为一种初分手段,还需通过利用各种其它的语言信息来进一步提高切分的准确率。
一种方法是改进扫描方式,称为特征扫描或标志切分,优先在待分析字符串中识别和切分出一些带有明显特征的词,以这些词作为断点,可将原字符串分为较小的串再来进机械分词,从而减少匹配的错误率。另一种方法是将分词和词类标注结合起来,利用丰富的词类信息对分词决策提供帮助,并且在标注过程中又反过来对分词结果进行检验、调整,从而极大地提高切分的准确率。
对于机械分词方法,可以建立一个一般的模型,在这方面有专业的学术论文,这里不做详细论述。
2、 基于理解的分词方法
这种分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
3、 基于统计的分词方法
从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。定义两个字的互现信息,计算两个汉字X、Y的相邻共现概率。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。但这种方法也有一定的局限性,会经常抽出一些共现频度高、但并不是词的常用字组,例如“这一”、“之一”、“有的”、“我的”、“许多的”等,并且对常用词的识别精度差,时空开销大。实际应用的统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7741
7741
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 해결 방법: 조직에서 PIN 변경을 요구합니다.
Oct 04, 2023 pm 05:45 PM
해결 방법: 조직에서 PIN 변경을 요구합니다.
Oct 04, 2023 pm 05:45 PM
로그인 화면에 "귀하의 조직에서 PIN 변경을 요구합니다"라는 메시지가 나타납니다. 이는 개인 장치를 제어할 수 있는 조직 기반 계정 설정을 사용하는 컴퓨터에서 PIN 만료 제한에 도달한 경우 발생합니다. 그러나 개인 계정을 사용하여 Windows를 설정하는 경우 이상적으로는 오류 메시지가 나타나지 않습니다. 항상 그런 것은 아니지만. 오류가 발생한 대부분의 사용자는 개인 계정을 사용하여 신고합니다. 조직에서 Windows 11에서 PIN을 변경하도록 요청하는 이유는 무엇입니까? 귀하의 계정이 조직과 연결되어 있을 수 있으므로 이를 확인하는 것이 기본 접근 방식입니다. 도메인 관리자에게 문의하면 도움이 될 수 있습니다! 또한 잘못 구성된 로컬 정책 설정이나 잘못된 레지스트리 키로 인해 오류가 발생할 수 있습니다. 지금 바로
 Windows 11에서 창 테두리 설정을 조정하는 방법: 색상 및 크기 변경
Sep 22, 2023 am 11:37 AM
Windows 11에서 창 테두리 설정을 조정하는 방법: 색상 및 크기 변경
Sep 22, 2023 am 11:37 AM
Windows 11은 신선하고 우아한 디자인을 전면에 내세웠습니다. 현대적인 인터페이스를 통해 창 테두리와 같은 미세한 세부 사항을 개인화하고 변경할 수 있습니다. 이 가이드에서는 Windows 운영 체제에서 자신의 스타일을 반영하는 환경을 만드는 데 도움이 되는 단계별 지침을 설명합니다. 창 테두리 설정을 변경하는 방법은 무엇입니까? +를 눌러 설정 앱을 엽니다. Windows개인 설정으로 이동하여 색상 설정을 클릭합니다. 색상 변경 창 테두리 설정 창 11" Width="643" Height="500" > 제목 표시줄 및 창 테두리에 강조 색상 표시 옵션을 찾아 옆에 있는 스위치를 토글합니다. 시작 메뉴 및 작업 표시줄에 강조 색상을 표시하려면 시작 메뉴와 작업 표시줄에 테마 색상을 표시하려면 시작 메뉴와 작업 표시줄에 테마 표시를 켭니다.
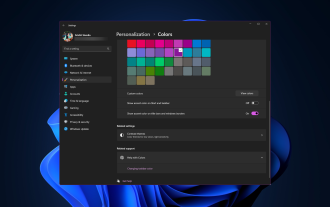 Windows 11에서 제목 표시줄 색상을 변경하는 방법은 무엇입니까?
Sep 14, 2023 pm 03:33 PM
Windows 11에서 제목 표시줄 색상을 변경하는 방법은 무엇입니까?
Sep 14, 2023 pm 03:33 PM
기본적으로 Windows 11의 제목 표시줄 색상은 선택한 어두운/밝은 테마에 따라 다릅니다. 그러나 원하는 색상으로 변경할 수 있습니다. 이 가이드에서는 이를 변경하고 데스크톱 환경을 개인화하여 시각적으로 매력적으로 만드는 세 가지 방법에 대한 단계별 지침을 논의합니다. 활성 창과 비활성 창의 제목 표시줄 색상을 변경할 수 있습니까? 예, 설정 앱을 사용하여 활성 창의 제목 표시줄 색상을 변경하거나 레지스트리 편집기를 사용하여 비활성 창의 제목 표시줄 색상을 변경할 수 있습니다. 이러한 단계를 알아보려면 다음 섹션으로 이동하세요. Windows 11에서 제목 표시줄 색상을 변경하는 방법은 무엇입니까? 1. 설정 앱을 사용하여 +를 눌러 설정 창을 엽니다. Windows"개인 설정"으로 이동한 다음
 Windows 11/10 복구의 OOBELANGUAGE 오류 문제
Jul 16, 2023 pm 03:29 PM
Windows 11/10 복구의 OOBELANGUAGE 오류 문제
Jul 16, 2023 pm 03:29 PM
Windows Installer 페이지에 "OOBELANGUAGE" 문과 함께 "문제가 발생했습니다."가 표시됩니까? 이러한 오류로 인해 Windows 설치가 중단되는 경우가 있습니다. OOBE는 즉시 사용 가능한 경험을 의미합니다. 오류 메시지에서 알 수 있듯이 이는 OOBE 언어 선택과 관련된 문제입니다. 걱정할 필요가 없습니다. OOBE 화면 자체에서 레지스트리를 편집하면 이 문제를 해결할 수 있습니다. 빠른 수정 – 1. OOBE 앱 하단에 있는 “다시 시도” 버튼을 클릭하세요. 그러면 더 이상의 문제 없이 프로세스가 계속됩니다. 2. 전원 버튼을 사용하여 시스템을 강제 종료합니다. 시스템이 다시 시작된 후 OOBE가 계속되어야 합니다. 3. 인터넷에서 시스템 연결을 끊습니다. 오프라인 모드에서 OOBE의 모든 측면을 완료하세요.
 Windows 11에서 작업 표시줄 축소판 미리 보기를 활성화 또는 비활성화하는 방법
Sep 15, 2023 pm 03:57 PM
Windows 11에서 작업 표시줄 축소판 미리 보기를 활성화 또는 비활성화하는 방법
Sep 15, 2023 pm 03:57 PM
작업 표시줄 축소판은 재미있을 수도 있지만 주의를 산만하게 하거나 짜증나게 할 수도 있습니다. 이 영역 위로 얼마나 자주 마우스를 가져가는지 고려하면 실수로 중요한 창을 몇 번 닫았을 수도 있습니다. 또 다른 단점은 더 많은 시스템 리소스를 사용한다는 것입니다. 따라서 리소스 효율성을 높일 수 있는 방법을 찾고 있다면 비활성화하는 방법을 알려드리겠습니다. 그러나 하드웨어 사양이 이를 처리할 수 있고 미리 보기가 마음에 들면 활성화할 수 있습니다. Windows 11에서 작업 표시줄 축소판 미리 보기를 활성화하는 방법은 무엇입니까? 1. 설정 앱을 사용하여 키를 탭하고 설정을 클릭합니다. Windows에서는 시스템을 클릭하고 정보를 선택합니다. 고급 시스템 설정을 클릭합니다. 고급 탭으로 이동하여 성능 아래에서 설정을 선택합니다. "시각 효과"를 선택하세요.
 Windows 11의 디스플레이 크기 조정 가이드
Sep 19, 2023 pm 06:45 PM
Windows 11의 디스플레이 크기 조정 가이드
Sep 19, 2023 pm 06:45 PM
Windows 11의 디스플레이 크기 조정과 관련하여 우리 모두는 서로 다른 선호도를 가지고 있습니다. 큰 아이콘을 좋아하는 사람도 있고, 작은 아이콘을 좋아하는 사람도 있습니다. 그러나 올바른 크기 조정이 중요하다는 점에는 모두가 동의합니다. 잘못된 글꼴 크기 조정이나 이미지의 과도한 크기 조정은 작업 시 생산성을 저하시킬 수 있으므로 시스템 기능을 최대한 활용하려면 이를 사용자 정의하는 방법을 알아야 합니다. Custom Zoom의 장점: 화면의 텍스트를 읽기 어려운 사람들에게 유용한 기능입니다. 한 번에 화면에서 더 많은 것을 볼 수 있도록 도와줍니다. 특정 모니터 및 응용 프로그램에만 적용되는 사용자 정의 확장 프로필을 생성할 수 있습니다. 저사양 하드웨어의 성능을 향상시키는 데 도움이 될 수 있습니다. 이를 통해 화면의 내용을 더 효과적으로 제어할 수 있습니다. 윈도우 11을 사용하는 방법
 Windows 11에서 밝기를 조정하는 10가지 방법
Dec 18, 2023 pm 02:21 PM
Windows 11에서 밝기를 조정하는 10가지 방법
Dec 18, 2023 pm 02:21 PM
화면 밝기는 최신 컴퓨팅 장치를 사용할 때 필수적인 부분이며, 특히 화면을 장시간 볼 때 더욱 그렇습니다. 눈의 피로를 줄이고, 가독성을 높이며, 콘텐츠를 쉽고 효율적으로 보는 데 도움이 됩니다. 그러나 설정에 따라 밝기 관리가 어려울 수 있으며, 특히 새로운 UI 변경이 적용된 Windows 11에서는 더욱 그렇습니다. 밝기를 조정하는 데 문제가 있는 경우 Windows 11에서 밝기를 관리하는 모든 방법은 다음과 같습니다. Windows 11에서 밝기를 변경하는 방법 [10가지 설명] 단일 모니터 사용자는 다음 방법을 사용하여 Windows 11에서 밝기를 조정할 수 있습니다. 여기에는 단일 모니터를 사용하는 데스크탑 시스템과 노트북이 포함됩니다. 시작하자. 방법 1: 알림 센터 사용 알림 센터에 액세스할 수 있습니다.
 Windows Server에서 활성화 오류 코드 0xc004f069를 수정하는 방법
Jul 22, 2023 am 09:49 AM
Windows Server에서 활성화 오류 코드 0xc004f069를 수정하는 방법
Jul 22, 2023 am 09:49 AM
Windows의 정품 인증 프로세스에서 갑자기 이 오류 코드 0xc004f069가 포함된 오류 메시지가 표시되는 경우가 있습니다. 활성화 프로세스가 온라인으로 진행되더라도 Windows Server를 실행하는 일부 이전 시스템에서 이 문제가 발생할 수 있습니다. 이러한 초기 점검을 수행하고 시스템 활성화에 도움이 되지 않으면 기본 해결 방법으로 이동하여 문제를 해결하십시오. 해결 방법 - 오류 메시지와 활성화 창을 닫습니다. 그런 다음 컴퓨터를 다시 시작하십시오. Windows 정품 인증 프로세스를 처음부터 다시 시도하세요. 수정 1 – 터미널에서 활성화 cmd 터미널에서 Windows Server Edition 시스템을 활성화합니다. 1단계 – Windows Server 버전 확인 현재 사용하고 있는 W 종류를 확인해야 합니다.
