

php获取网页标题和内容函数(不包含html标签)_PHP教程

function getPageContent($url) {
//$url='http://www.ttphp.com;
$pageinfo = array();
$pageinfo[content_type] = '';
$pageinfo[charset] = '';
$pageinfo[title] = '';
$pageinfo[description] = '';
$pageinfo[keywords] = '';
$pageinfo[body] = '';
$pageinfo['httpcode'] = 200;
$pageinfo['all'] = '';
$ch = curl_init();
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)");
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER,0);
curl_setopt($ch, CURLOPT_TIMEOUT, 8);
curl_setopt($ch, CURLOPT_FILETIME, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
//curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_URL,$url);
$curl_start = microtime(true);
$store = curl_exec ($ch);
$curl_time = microtime(true) - $curl_start;
if( curl_error($ch) ) {
$pageinfo['httpcode'] = 505; //gate way error
echo 'Curl error: ' . curl_error($ch) ."/n";
return $pageinfo;
}
//print_r(curl_getinfo($ch));
$pageinfo['httpcode'] = curl_getinfo($ch,CURLINFO_HTTP_CODE);
//echo curl_getinfo($ch,CURLINFO_CONTENT_TYPE)."/n";
$pageinfo[content_type] = curl_getinfo($ch,CURLINFO_CONTENT_TYPE);
if(intval($pageinfo['httpcode']) 200 or !preg_match('@text/html@',curl_getinfo($ch,CURLINFO_CONTENT_TYPE) ) ) {
//print_r(curl_getinfo($ch) );
//exit;
return $pageinfo;
}
preg_match('/charset=([^/s/n/r]+)/i',curl_getinfo($ch,CURLINFO_CONTENT_TYPE),$matches); //从header 里取charset
if( trim($matches[1]) ) {
$pageinfo[charset] = trim($matches[1]);
}
//echo $pageinfo[charset];
//exit;
curl_close ($ch);
//echo $store;
//remove javascript
$store = preg_replace("/
$store = preg_replace("//smUi",'',$store);
//remove
使用例子
$a = getPageContent(www.ttphp.com);
print_r($a);

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7342
7342
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29

 Python에서 파일 확장자를 얻는 방법은 무엇입니까?
Sep 08, 2023 pm 01:53 PM
Python에서 파일 확장자를 얻는 방법은 무엇입니까?
Sep 08, 2023 pm 01:53 PM
Python의 파일 확장자는 파일의 형식이나 유형을 나타내기 위해 파일 이름 끝에 추가되는 접미사입니다. 일반적으로 ".txt" 또는 ".py"와 같이 파일 이름 뒤에 마침표가 오는 3~4개의 문자로 구성됩니다. 운영 체제와 프로그램은 파일 확장자를 사용하여 파일 형식과 처리 방법을 결정합니다. 일반 텍스트 파일로 인식됩니다. Python의 파일 확장자는 파일 형식과 데이터를 읽고 쓰는 가장 좋은 방법을 설정하기 때문에 파일을 읽거나 쓸 때 중요합니다. 예를 들어 ".csv" 파일 확장자는 CSV 파일을 읽을 때 사용되는 확장자이고, csv 모듈은 파일을 처리하는 데 사용됩니다. Python에서 파일 확장자를 얻는 알고리즘입니다. Python에서 파일 이름 문자열을 조작합니다.
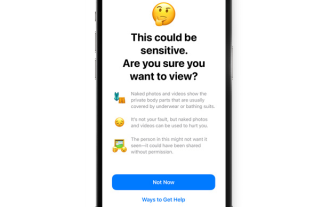 iPhone에서 민감한 콘텐츠 경고를 활성화하고 해당 기능에 대해 알아보는 방법
Sep 22, 2023 pm 12:41 PM
iPhone에서 민감한 콘텐츠 경고를 활성화하고 해당 기능에 대해 알아보는 방법
Sep 22, 2023 pm 12:41 PM
특히 지난 10년 동안 모바일 장치는 친구 및 가족과 콘텐츠를 공유하는 주요 방법이 되었습니다. 접근하기 쉽고 사용하기 쉬운 인터페이스와 실시간으로 이미지 및 비디오를 캡처할 수 있는 기능은 콘텐츠 제작 및 공유를 위한 탁월한 선택입니다. 그러나 악의적인 사용자가 이러한 도구를 악용하여 보기에 적합하지 않고 사용자의 동의가 필요하지 않은 원치 않는 민감한 콘텐츠를 전달하기 쉽습니다. 이러한 일이 발생하지 않도록 iOS17에는 "민감한 콘텐츠 경고"라는 새로운 기능이 도입되었습니다. 이에 대해 살펴보고 iPhone에서 사용하는 방법을 살펴보겠습니다. 새로운 민감한 콘텐츠 경고는 무엇이며 어떻게 작동하나요? 위에서 언급한 것처럼 민감한 콘텐츠 경고는 사용자가 iPhone을 포함한 민감한 콘텐츠를 보지 못하도록 설계된 새로운 개인 정보 보호 및 보안 기능입니다.
 360 탐색으로 열리도록 Microsoft Edge 브라우저를 변경하는 방법 - 360 탐색으로 열기를 변경하는 방법
Mar 04, 2024 pm 01:50 PM
360 탐색으로 열리도록 Microsoft Edge 브라우저를 변경하는 방법 - 360 탐색으로 열기를 변경하는 방법
Mar 04, 2024 pm 01:50 PM
Microsoft Edge 브라우저에서 360 탐색 페이지를 여는 페이지를 변경하는 방법은 실제로 매우 간단하므로 이제 Microsoft Edge에서 360 탐색 페이지를 여는 페이지를 변경하는 방법을 공유하겠습니다. 브라우저가 필요한 친구가 모두를 도울 수 있기를 바랍니다. Microsoft Edge 브라우저를 엽니다. 아래와 같은 페이지가 보입니다. 오른쪽 상단에 있는 점 3개 아이콘을 클릭하세요. '설정'을 클릭하세요. 설정 페이지의 왼쪽 열에서 "시작 시"를 클릭하세요. 오른쪽 열의 그림에 표시된 세 지점을 클릭한 다음("새 탭 열기"를 클릭하지 마세요), 편집을 클릭하고 URL을 "0"(또는 기타 의미 없는 숫자)으로 변경하세요. 그런 다음 "저장"을 클릭하세요. 다음으로 '를 선택하세요.
 Google 보안 코드를 받을 수 있는 곳
Mar 30, 2024 am 11:11 AM
Google 보안 코드를 받을 수 있는 곳
Mar 30, 2024 am 11:11 AM
Google OTP는 사용자 계정의 보안을 보호하기 위해 사용되는 도구로, 그 핵심은 동적 인증 코드를 생성하는 데 사용되는 중요한 정보입니다. Google OTP의 키를 잊어버렸고 보안 코드를 통해서만 확인할 수 있는 경우, 이 웹사이트의 편집자가 Google 보안 코드를 얻을 수 있는 위치에 대한 자세한 소개를 제공할 것입니다. 더 많은 정보를 알고 계시다면 아래 내용을 계속 읽어주세요! 먼저 전화 설정을 열고 설정 페이지로 들어갑니다. 페이지를 아래로 스크롤하여 Google을 찾으세요. Google 페이지로 이동하여 Google 계정을 클릭하세요. 계정 페이지에 들어가서 인증 코드 아래에 있는 보기를 클릭하세요. 비밀번호를 입력하거나 지문을 사용하여 신원을 확인하세요. Google 보안 코드를 받고 보안 코드를 사용하여 Google 신원을 확인하세요.
 간단한 JavaScript 튜토리얼: HTTP 상태 코드를 얻는 방법
Jan 05, 2024 pm 06:08 PM
간단한 JavaScript 튜토리얼: HTTP 상태 코드를 얻는 방법
Jan 05, 2024 pm 06:08 PM
JavaScript 튜토리얼: HTTP 상태 코드를 얻는 방법, 특정 코드 예제가 필요합니다. 서문: 웹 개발에서는 서버와의 데이터 상호 작용이 종종 포함됩니다. 서버와 통신할 때 반환된 HTTP 상태 코드를 가져와서 작업의 성공 여부를 확인하고 다양한 상태 코드에 따라 해당 처리를 수행해야 하는 경우가 많습니다. 이 기사에서는 JavaScript를 사용하여 HTTP 상태 코드를 얻는 방법과 몇 가지 실용적인 코드 예제를 제공합니다. XMLHttpRequest 사용
 Realme 12 Pro에 듀얼 SIM을 설치하는 방법은 무엇입니까?
Mar 18, 2024 pm 02:10 PM
Realme 12 Pro에 듀얼 SIM을 설치하는 방법은 무엇입니까?
Mar 18, 2024 pm 02:10 PM
국내 휴대폰의 일반적인 작동은 매우 유사하지만 일부 세부 사항에는 여전히 약간의 차이가 있습니다. 예를 들어 휴대폰 모델 및 제조업체에 따라 듀얼 SIM 설치 방법이 다를 수 있습니다. 신형 휴대폰인 Erzhenwo 12Pro도 듀얼심 듀얼 대기를 지원하는데, 이 휴대폰에 듀얼심을 어떻게 설치해야 할까요? Realme 12Pro에 듀얼 SIM을 설치하는 방법은 무엇입니까? 설치하기 전에 휴대폰을 끄는 것을 잊지 마십시오. 1단계: SIM 카드 트레이 찾기: 휴대폰의 SIM 카드 트레이를 찾습니다. 일반적으로 Realme 12 Pro에서는 SIM 카드 트레이가 휴대폰 측면이나 상단에 있습니다. 2단계: 첫 번째 SIM 카드를 삽입합니다. 전용 SIM 카드 핀이나 작은 물체를 사용하여 SIM 카드 트레이의 슬롯에 삽입합니다. 그런 다음 첫 번째 SIM 카드를 조심스럽게 삽입합니다.
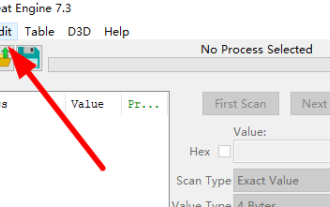 중국어로 치트 엔진을 설정하는 방법은 무엇입니까? 치트 엔진 설정 중국어 방식
Mar 13, 2024 pm 04:49 PM
중국어로 치트 엔진을 설정하는 방법은 무엇입니까? 치트 엔진 설정 중국어 방식
Mar 13, 2024 pm 04:49 PM
CheatEngine은 게임의 메모리를 편집하고 수정할 수 있는 게임 편집기입니다. 그러나 기본 언어는 중국어가 아니므로 많은 친구들에게 불편을 줍니다. 그렇다면 CheatEngine에서 중국어를 설정하는 방법은 무엇입니까? 오늘은 에디터가 CheatEngine에서 중국어를 설정하는 방법에 대해 자세히 소개하겠습니다. 도움이 되셨으면 좋겠습니다. 설정 방법 1: 1. 두 번 클릭하여 소프트웨어를 열고 왼쪽 상단에 있는 "편집"을 클릭합니다. 2. 그런 다음 아래 옵션 목록에서 "설정"을 클릭하세요. 3. 열리는 창의 왼쪽 열에서 "언어"를 클릭하세요.
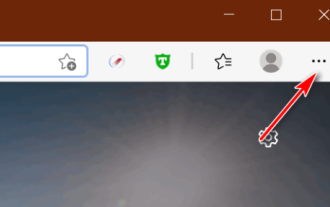 Microsoft Edge에서 다운로드 버튼을 설정하는 위치 - Microsoft Edge에서 다운로드 버튼을 설정하는 방법
Mar 06, 2024 am 11:49 AM
Microsoft Edge에서 다운로드 버튼을 설정하는 위치 - Microsoft Edge에서 다운로드 버튼을 설정하는 방법
Mar 06, 2024 am 11:49 AM
다운로드 버튼을 표시하도록 Microsoft Edge가 어디에 설정되어 있는지 알고 계시나요? 아래에서 편집기를 통해 다운로드 버튼을 표시하도록 설정하는 방법을 알려드리겠습니다. 1단계: 먼저 Microsoft Edge Browser를 열고 아래 그림과 같이 오른쪽 상단에 있는 [...] 로고를 클릭합니다. 2단계: 그런 다음 아래 그림과 같이 팝업 메뉴에서 [설정]을 클릭합니다. 3단계: 그런 다음 아래 그림과 같이 인터페이스 왼쪽에 있는 [모양]을 클릭합니다. 4단계: 마지막으로 [다운로드 버튼 표시] 오른쪽에 있는 버튼을 클릭하면 아래 그림과 같이 회색에서 파란색으로 변경됩니다. 위는 편집기가 Microsoft Edge에서 다운로드 버튼을 설정하는 방법을 제공하는 곳입니다.
