

Python模拟登陆淘宝并统计淘宝消费情况的代码实例分享

支付宝十年账单上的数字有点吓人,但它统计的项目太多,只是想看看到底单纯在淘宝上支出了多少,于是写了段脚本,统计任意时间段淘宝订单的消费情况,看那结果其实在淘宝上我还是相当节约的说。
脚本的主要工作是模拟了浏览器登录,解析“已买到的宝贝”页面以获得指定的订单及宝贝信息。
使用方法见代码或执行命令加参数-h,另外需要BeautifulSoup4支持,BeautifulSoup的官方项目列表页:https://www.crummy.com/software/BeautifulSoup/bs4/download/
首先来说一下代码使用方法:
python taobao.py -u USERNAME -p PASSWORD -s START-DATE -e END-DATE --verbose
所有参数均可选,如:
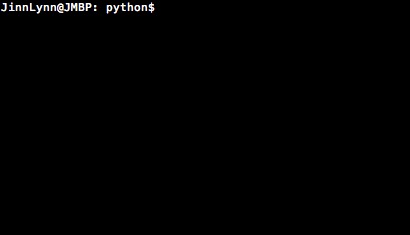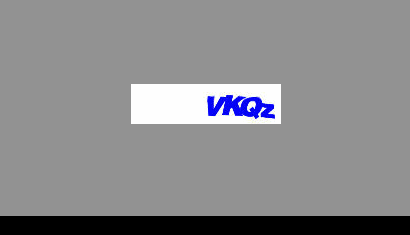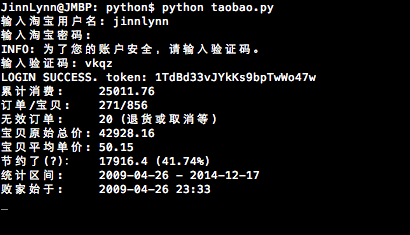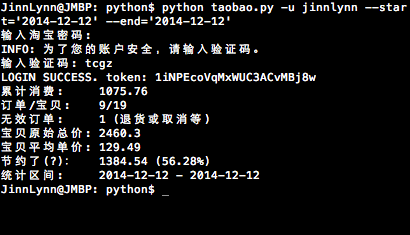
python taobao.py -u jinnlynn
统计用户jinnlynn所有订单的情况
python taobao.py -s 2014-12-12 -e 2014-12-12
统计用户(用户名在命令执行时会要求输入)在2014-12-12当天的订单情况
python taobao.py --verbose
这样就可以统计并输出订单明细。
好了,说了这么多我们就来看代码吧:
from __future__ import unicode_literals, print_function, absolute_import, division
import urllib
import urllib2
import urlparse
import cookielib
import re
import sys
import os
import json
import subprocess
import argparse
import platform
from getpass import getpass
from datetime import datetime
from pprint import pprint
try:
from bs4 import BeautifulSoup
except ImportError:
sys.exit('BeautifulSoup4 missing.')
__version__ = '1.0.0'
__author__ = 'JinnLynn'
__copyright__ = 'Copyright (c) 2014 JinnLynn'
__license__ = 'The MIT License'
HEADERS = {
'x-requestted-with' : 'XMLHttpRequest',
'Accept-Language' : 'zh-cn',
'Accept-Encoding' : 'gzip, deflate',
'ContentType' : 'application/x-www-form-urlencoded; chartset=UTF-8',
'Cache-Control' : 'no-cache',
'User-Agent' :'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.38 Safari/537.36',
'Connection' : 'Keep-Alive'
}
DEFAULT_POST_DATA = {
'TPL_username' : '', #用户名
'TPL_password' : '', #密码
'TPL_checkcode' : '',
'need_check_code' : 'false',
'callback' : '0', # 有值返回JSON
}
# 无效订单状态
INVALID_ORDER_STATES = [
'CREATE_CLOSED_OF_TAOBAO', # 取消
'TRADE_CLOSED', # 订单关闭
]
LOGIN_URL = 'https://login.taobao.com/member/login.jhtml'
RAW_IMPUT_ENCODING = 'gbk' if platform.system() == 'Windows' else 'utf-8'
def _request(url, data, method='POST'):
if data:
data = urllib.urlencode(data)
if method == 'GET':
if data:
url = '{}?{}'.format(url, data)
data = None
# print(url)
# print(data)
req = urllib2.Request(url, data, HEADERS)
return urllib2.urlopen(req)
def stdout_cr(msg=''):
sys.stdout.write('\r{:10}'.format(' '))
sys.stdout.write('\r{}'.format(msg))
sys.stdout.flush()
def get(url, data=None):
return _request(url, data, method='GET')
def post(url, data=None):
return _request(url, data, method='POST')
def login_post(data):
login_data = DEFAULT_POST_DATA
login_data.update(data)
res = post(LOGIN_URL, login_data)
return json.load(res, encoding='gbk')
def login(usr, pwd):
data = {
'TPL_username' : usr.encode('utf-8' if platform.system() == 'Windows' else 'GB18030'),
'TPL_password' : pwd
}
# 1. 尝试登录
ret = login_post(data)
while not ret.get('state', False):
code = ret.get('data', {}).get('code', 0)
if code == 3425 or code == 1000:
print('INFO: {}'.format(ret.get('message')))
check_code = checkcode(ret.get('data', {}).get('ccurl'))
data.update({'TPL_checkcode' : check_code, 'need_check_code' : 'true'})
ret = login_post(data)
else:
sys.exit('ERROR. code: {}, message:{}'.format(code, ret.get('message', '')))
token = ret.get('data', {}).get('token')
print('LOGIN SUCCESS. token: {}'.format(token))
# 2. 重定向
# 2.1 st值
res = get('https://passport.alipay.com/mini_apply_st.js', {
'site' : '0',
'token' : token,
'callback' : 'stCallback4'})
content = res.read()
st = re.search(r'"st":"(\S*)"( |})', content).group(1)
# 2.1 重定向
get('http://login.taobao.com/member/vst.htm',
{'st' : st, 'TPL_uesrname' : usr.encode('GB18030')})
def checkcode(url):
filename, _ = urllib.urlretrieve(url)
if not filename.endswith('.jpg'):
old_fn = filename
filename = '{}.jpg'.format(filename)
os.rename(old_fn, filename)
if platform.system() == 'Darwin':
# mac 下直接preview打开
subprocess.call(['open', filename])
elif platform.system() == 'Windows':
# windows 执行文件用默认程序打开
subprocess.call(filename, shell=True)
else:
# 其它系统 输出文件名
print('打开该文件获取验证码: {}'.format(filename))
return raw_input('输入验证码: '.encode(RAW_IMPUT_ENCODING))
def parse_bought_list(start_date=None, end_date=None):
url = 'http://buyer.trade.taobao.com/trade/itemlist/list_bought_items.htm'
# 运费险 增值服务 分段支付(定金,尾款)
extra_service = ['freight-info', 'service-info', 'stage-item']
stdout_cr('working... {:.0%}'.format(0))
# 1. 解析第一页
res = urllib2.urlopen(url)
soup = BeautifulSoup(res.read().decode('gbk'))
# 2. 获取页数相关
page_jump = soup.find('span', id='J_JumpTo')
jump_url = page_jump.attrs['data-url']
url_parts = urlparse.urlparse(jump_url)
query_data = dict(urlparse.parse_qsl(url_parts.query))
total_pages = int(query_data['tPage'])
# 解析
orders = []
cur_page = 1
out_date = False
errors = []
while True:
bought_items = soup.find_all('tbody', attrs={'data-orderid' : True})
# pprint(len(bought_items))
count = 0
for item in bought_items:
count += 1
# pprint('{}.{}'.format(cur_page, count))
try:
info = {}
# 订单在页面上的位置 页数.排序号
info['pos'] = '{}.{}'.format(cur_page, count)
info['orderid'] = item.attrs['data-orderid']
info['status'] = item.attrs['data-status']
# 店铺
node = item.select('tr.order-hd a.shopname')
if not node:
# 店铺不存在,可能是赠送彩票订单,忽略
# print('ignore')
continue
info['shop_name'] = node[0].attrs['title'].strip()
info['shop_url'] = node[0].attrs['href']
# 日期
node = item.select('tr.order-hd span.dealtime')[0]
info['date'] = datetime.strptime(node.attrs['title'], '%Y-%m-%d %H:%M')
if end_date and info['date'].toordinal() > end_date.toordinal():
continue
if start_date and info['date'].toordinal() < start_date.toordinal():
out_date = True
break
# 宝贝
baobei = []
node = item.find_all('tr', class_='order-bd')
# pprint(len(node))
for n in node:
try:
bb = {}
if [True for ex in extra_service if ex in n.attrs['class']]:
# 额外服务处理
# print('额外服务处理')
name_node = n.find('td', class_='baobei')
# 宝贝地址
bb['name'] = name_node.text.strip()
bb['url'] = ''
bb['spec'] = ''
# 宝贝快照
bb['snapshot'] = ''
# 宝贝价格
bb['price'] = 0.0
# 宝贝数量
bb['quantity'] = 1
bb['is_goods'] = False
try:
bb['url'] = name_node.find('a').attrs['href']
bb['price'] = float(n.find('td', class_='price').text)
except:
pass
else:
name_node = n.select('p.baobei-name a')
# 宝贝地址
bb['name'] = name_node[0].text.strip()
bb['url'] = name_node[0].attrs['href']
# 宝贝快照
bb['snapshot'] = ''
if len(name_node) > 1:
bb['snapshot'] = name_node[1].attrs['href']
# 宝贝规格
bb['spec'] = n.select('.spec')[0].text.strip()
# 宝贝价格
bb['price'] = float(n.find('td', class_='price').attrs['title'])
# 宝贝数量
bb['quantity'] = int(n.find('td', class_='quantity').attrs['title'])
bb['is_goods'] = True
baobei.append(bb)
# 尝试获取实付款
# 实付款所在的节点可能跨越多个tr的td
amount_node = n.select('td.amount em.real-price')
if amount_node:
info['amount'] = float(amount_node[0].text)
except Exception as e:
errors.append({
'type' : 'baobei',
'id' : '{}.{}'.format(cur_page, count),
'node' : '{}'.format(n),
'error' : '{}'.format(e)
})
except Exception as e:
errors.append({
'type' : 'order',
'id' : '{}.{}'.format(cur_page, count),
'node' : '{}'.format(item),
'error' : '{}'.format(e)
})
info['baobei'] = baobei
orders.append(info)
stdout_cr('working... {:.0%}'.format(cur_page / total_pages))
# 下一页
cur_page += 1
if cur_page > total_pages or out_date:
break
query_data.update({'pageNum' : cur_page})
page_url = '{}?{}'.format(url, urllib.urlencode(query_data))
res = urllib2.urlopen(page_url)
soup = BeautifulSoup(res.read().decode('gbk'))
stdout_cr()
if errors:
print('INFO. 有错误发生,统计结果可能不准确。')
# pprint(errors)
return orders
def output(orders, start_date, end_date):
amount = 0.0
org_amount = 0
baobei_count = 0
order_count = 0
invaild_order_count = 0
for order in orders:
if order['status'] in INVALID_ORDER_STATES:
invaild_order_count += 1
continue
amount += order['amount']
order_count += 1
for baobei in order.get('baobei', []):
if not baobei['is_goods']:
continue
org_amount += baobei['price'] * baobei['quantity']
baobei_count += baobei['quantity']
print('{:<9} {}'.format('累计消费:', amount))
print('{:<9} {}/{}'.format('订单/宝贝:', order_count, baobei_count))
if invaild_order_count:
print('{:<9} {} (退货或取消等, 不在上述订单之内)'.format('无效订单:', invaild_order_count))
print('{:<7} {}'.format('宝贝原始总价:', org_amount))
print('{:<7} {:.2f}'.format('宝贝平均单价:', 0 if baobei_count == 0 else org_amount / baobei_count))
print('{:<9} {} ({:.2%})'.format('节约了(?):',
org_amount - amount,
0 if org_amount == 0 else (org_amount - amount) / org_amount))
from_date = start_date if start_date else orders[-1]['date']
to_date = end_date if end_date else datetime.now()
print('{:<9} {:%Y-%m-%d} - {:%Y-%m-%d}'.format('统计区间:', from_date, to_date))
if not start_date:
print('{:<9} {:%Y-%m-%d %H:%M}'.format('败家始于:', orders[-1]['date']))
def ouput_orders(orders):
print('所有订单:')
if not orders:
print(' --')
return
for order in orders:
print(' {:-^20}'.format('-'))
print(' * 订单号: {orderid} 实付款: {amount} 店铺: {shop_name} 时间: {date:%Y-%m-%d %H:%M}'.format(**order))
for bb in order['baobei']:
if not bb['is_goods']:
continue
print(' - {name}'.format(**bb))
if bb['spec']:
print(' {spec}'.format(**bb))
print(' {price} X {quantity}'.format(**bb))
def main():
parser = argparse.ArgumentParser(
prog='python {}'.format(__file__)
)
parser.add_argument('-u', '--username', help='淘宝用户名')
parser.add_argument('-p', '--password', help='淘宝密码')
parser.add_argument('-s', '--start', help='起始时间,可选, 格式如: 2014-11-11')
parser.add_argument('-e', '--end', help='结束时间,可选, 格式如: 2014-11-11')
parser.add_argument('--verbose', action='store_true', default=False, help='订单详细输出')
parser.add_argument('-v', '--version', action='version',
version='v{}'.format(__version__), help='版本号')
args = parser.parse_args()
usr = args.username
if not usr:
usr = raw_input('输入淘宝用户名: '.encode(RAW_IMPUT_ENCODING))
usr = usr.decode('utf-8') # 中文输入问题
pwd = args.password
if not pwd:
if platform.system() == 'Windows':
# Windows下中文输出有问题
pwd = getpass()
else:
pwd = getpass('输入淘宝密码: '.encode('utf-8'))
pwd = pwd.decode('utf-8')
verbose = args.verbose
start_date = None
if args.start:
try:
start_date = datetime.strptime(args.start, '%Y-%m-%d')
except Exception as e:
sys.exit('ERROR. {}'.format(e))
end_date = None
if args.end:
try:
end_date = datetime.strptime(args.end, '%Y-%m-%d')
except Exception as e:
sys.exit('ERROR. {}'.format(e))
if start_date and end_date and start_date > end_date:
sys.exit('ERROR, 结束日期必须晚于或等于开始日期')
cj_file = './{}.tmp'.format(usr)
cj = cookielib.LWPCookieJar()
try:
cj.load(cj_file)
except:
pass
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj), urllib2.HTTPHandler)
urllib2.install_opener(opener)
login(usr, pwd)
try:
cj.save(cj_file)
except:
pass
orders = parse_bought_list(start_date, end_date)
output(orders, start_date, end_date)
# 输出订单明细
if verbose:
ouput_orders(orders)
if __name__ == '__main__':
main()

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
Sublime 텍스트로 Python 코드를 실행하려면 먼저 Python 플러그인을 설치 한 다음 .py 파일을 작성하고 코드를 작성한 다음 CTRL B를 눌러 코드를 실행하면 콘솔에 출력이 표시됩니다.
 vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
Visual Studio Code (VSCODE)에서 코드를 작성하는 것은 간단하고 사용하기 쉽습니다. vscode를 설치하고, 프로젝트를 만들고, 언어를 선택하고, 파일을 만들고, 코드를 작성하고, 저장하고 실행합니다. VSCODE의 장점에는 크로스 플랫폼, 무료 및 오픈 소스, 강력한 기능, 풍부한 확장 및 경량 및 빠른가 포함됩니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장에서 Python 코드를 실행하려면 Python 실행 파일 및 NPPEXEC 플러그인을 설치해야합니다. Python을 설치하고 경로를 추가 한 후 nppexec 플러그인의 명령 "Python"및 매개 변수 "{current_directory} {file_name}"을 구성하여 Notepad의 단축키 "F6"을 통해 Python 코드를 실행하십시오.
