

Python을 이용한 기본 코드 인터프리터 작성의 핵심 포인트 분석
Aug 04, 2016 am 08:55 AM저는 항상 컴파일러와 파서에 관심이 많았습니다. 컴파일러의 개념과 전반적인 프레임워크도 알고 있지만 세부적인 내용은 잘 모릅니다. 우리가 작성하는 프로그램 소스 코드는 실제로 일련의 문자입니다. 컴파일러나 인터프리터는 이 문자 시퀀스를 직접 이해하고 실행할 수 있습니다. 이 기사에서는 Python을 사용하여 소규모 목록 조작 언어(파이썬의 목록과 유사)를 해석하는 간단한 파서를 구현합니다. 사실, 컴파일러와 인터프리터는 기본 이론만 이해하면 구현이 비교적 간단합니다(물론 제품 수준의 컴파일러나 인터프리터는 여전히 매우 복잡합니다).
이 목록 언어에서 지원되는 작업:
veca = [1, 2, 3] # 列表声明 vecb = [4, 5, 6] print 'veca:', veca # 打印字符串、列表,print expr+ print 'veca * 2:', veca * 2 # 列表与整数乘法 print 'veca + 2:', veca + 2 # 列表与整数加法 print 'veca + vecb:', veca + vecb # 列表加法 print 'veca + [11, 12]:', veca + [11, 12] print 'veca * vecb:', veca * vecb # 列表乘法 print 'veca:', veca print 'vecb:', vecb
해당 출력:
veca: [1, 2, 3] veca * 2: [2, 4, 6] veca + 2: [1, 2, 3, 2] veca + vecb: [1, 2, 3, 2, 4, 5, 6] veca + [11, 12]: [1, 2, 3, 2, 11, 12] veca * vecb: [4, 5, 6, 8, 10, 12, 12, 15, 18, 8, 10, 12] veca: [1, 2, 3, 2] vecb: [4, 5, 6]
컴파일러와 인터프리터가 입력 문자 스트림을 처리할 때 기본적으로 인간이 문장을 이해하는 방식과 일치합니다. 예:
I love you.
영어를 처음 배우는 경우 먼저 각 단어의 의미를 알아야 하며, 그런 다음 각 단어의 품사를 주어-술어-목적어 구조에 맞게 분석하여 의미를 이해할 수 있어야 합니다. 이 문장의. 이 문장은 어휘분열에 따라 어휘단위스트림이 얻어지는 것이며, 실제로 이것이 문자스트림에서 어휘단위스트림으로의 변환을 완성하는 것이다. 품사를 분석하여 주어-동사-목적어 구조를 결정하는 것은 영어 문법에 따라 이 구조를 파악하는 것이며, 이것이 문법 분석이며, 입력된 어휘 단위 흐름을 기반으로 문법 파싱 트리를 식별한다. 마지막으로 단어의 의미와 문법적 구조를 결합하여 최종적으로 문장의 의미를 도출하는 것이 의미론적 분석이다. 컴파일러와 인터프리터의 처리 과정은 비슷하지만 약간 더 복잡합니다. 여기서는 인터프리터에만 중점을 둡니다.
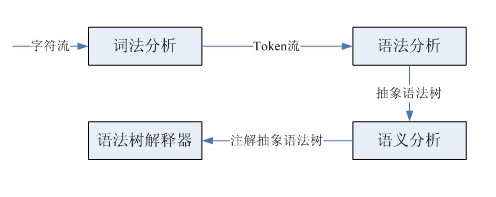
우리는 아주 간단한 작은 언어를 구현하고 있을 뿐이므로 구문 트리 생성과 그에 따른 복잡한 의미 분석이 포함되지 않습니다. 다음으로 어휘 분석과 구문 분석에 대해 살펴보겠습니다.
어휘 분석과 구문 분석은 각각 어휘 파서와 구문 파서에 의해 완료됩니다. 이 두 파서는 구조와 기능이 비슷합니다. 둘 다 입력 시퀀스를 입력으로 사용하여 특정 구조를 식별합니다. 어휘 파서는 소스 코드 문자 스트림에서 토큰(어휘 단위)을 하나씩 구문 분석하는 반면, 구문 파서는 하위 구조와 어휘 단위를 식별한 후 일부 처리를 수행합니다. 두 파서는 모두 LL(1) 재귀 하강 파서를 통해 구현될 수 있습니다. 이 유형의 파서로 완료되는 단계는 다음과 같습니다. 절의 유형을 예측하고, 하위 구조와 일치하도록 구문 분석 함수를 호출하고, 어휘 단위를 일치시킨 다음, 다음과 같이 코드를 삽입합니다. 필요합니다. 사용자 정의 작업을 수행합니다.
다음은 LL(1)에 대한 간략한 소개입니다. LL(1)은 구문 분석을 위해 구문 분석 트리를 사용합니다. 예: x = x 2;
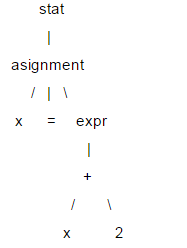
이 트리에서 x, =, 2와 같은 리프 노드를 터미널 노드라고 하고, 나머지 노드를 비터미널 노드라고 합니다. LL(1)을 구문 분석할 때 특정 트리 데이터 구조를 만들 필요가 없습니다. 각 비종단 노드에 대해 구문 분석 함수를 작성하고 해당 노드를 만날 때 이를 호출하면 구문 분석을 통과할 수 있습니다. 구문 분석 트리 정보를 얻기 위해 호출 시퀀스(트리 탐색과 동일)에서 함수를 사용합니다. LL(1)이 파싱되면 루트 노드부터 리프 노드까지 순서대로 실행되므로 이는 "내림차순" 프로세스이고 파싱 함수는 자신을 호출할 수 있으므로 "재귀적"이므로 LL( 1) 재귀 하강 파서라고도 합니다.
LL(1)의 두 L은 모두 왼쪽에서 오른쪽을 의미합니다. 첫 번째 L은 파서가 입력 내용을 왼쪽에서 오른쪽으로 구문 분석함을 의미하고 두 번째 L은 내림차순 프로세스 중에 입력도 분석함을 의미합니다. 콘텐츠는 왼쪽에서 오른쪽으로 하위 노드를 순회하며, 1은 1개의 예측 단위를 기반으로 예측을 한다는 의미입니다.
목록 미니 언어의 구현을 살펴보겠습니다. 첫 번째는 언어의 문법입니다. 문법은 언어를 설명하는 데 사용되며 파서의 설계 사양으로 간주됩니다.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
这是用DSL描述的文法,其中大部分概念和正则表达式类似。"a|b"表示a或者b,所有以单引号括起的字符串是关键字,比如:print,=等。大写的单词是词法单元。可以看到这个小语言的文法还是很简单的。有很多解析器生成器可以自动根据文法生成对应的解析器,比如:ANTRL,flex,yacc等,这里采用手写解析器主要是为了理解解析器的原理。下面看一下这个小语言的解释器是如何实现的。
首先是词法解析器,完成字符流到token流的转换。采用LL(1)实现,所以使用1个向前看字符预测匹配的token。对于像INT、ID这样由多个字符组成的词法规则,解析器有一个与之对应的方法。由于语法解析器并不关心空白字符,所以词法解析器在遇到空白字符时直接忽略掉。每个token都有两个属性类型和值,比如整型、标识符类型等,对于整型类型它的值就是该整数。语法解析器需要根据token的类型进行预测,所以词法解析必须返回类型信息。语法解析器以iterator的方式获取token,所以词法解析器实现了next_token方法,以元组方式(type, value)返回下一个token,在没有token的情况时返回EOF。
'''''
A simple lexer of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
Created on 2012-9-26
@author: bjzllou
'''
EOF = -1
# token type
COMMA = 'COMMA'
EQUAL = 'EQUAL'
LBRACK = 'LBRACK'
RBRACK = 'RBRACK'
TIMES = 'TIMES'
ADD = 'ADD'
PRINT = 'print'
ID = 'ID'
INT = 'INT'
STR = 'STR'
class Veclexer:
'''''
LL(1) lexer.
It uses only one lookahead char to determine which is next token.
For each non-terminal token, it has a rule to handle it.
LL(1) is a quit weak parser, it isn't appropriate for the grammar which is
left-recursive or ambiguity. For example, the rule 'T: T r' is left recursive.
However, it's rather simple and has high performance, and fits simple grammar.
'''
def __init__(self, input):
self.input = input
# current index of the input stream.
self.idx = 1
# lookahead char.
self.cur_c = input[0]
def next_token(self):
while self.cur_c != EOF:
c = self.cur_c
if c.isspace():
self.consume()
elif c == '[':
self.consume()
return (LBRACK, c)
elif c == ']':
self.consume()
return (RBRACK, c)
elif c == ',':
self.consume()
return (COMMA, c)
elif c == '=':
self.consume()
return (EQUAL, c)
elif c == '*':
self.consume()
return (TIMES, c)
elif c == '+':
self.consume()
return (ADD, c)
elif c == '\'' or c == '"':
return self._string()
elif c.isdigit():
return self._int()
elif c.isalpha():
t = self._print()
return t if t else self._id()
else:
raise Exception('not support token')
return (EOF, 'EOF')
def has_next(self):
return self.cur_c != EOF
def _id(self):
n = self.cur_c
self.consume()
while self.cur_c.isalpha():
n += self.cur_c
self.consume()
return (ID, n)
def _int(self):
n = self.cur_c
self.consume()
while self.cur_c.isdigit():
n += self.cur_c
self.consume()
return (INT, int(n))
def _print(self):
n = self.input[self.idx - 1 : self.idx + 4]
if n == 'print':
self.idx += 4
self.cur_c = self.input[self.idx]
return (PRINT, n)
return None
def _string(self):
quotes_type = self.cur_c
self.consume()
s = ''
while self.cur_c != '\n' and self.cur_c != quotes_type:
s += self.cur_c
self.consume()
if self.cur_c != quotes_type:
raise Exception('string quotes is not matched. excepted %s' % quotes_type)
self.consume()
return (STR, s)
def consume(self):
if self.idx >= len(self.input):
self.cur_c = EOF
return
self.cur_c = self.input[self.idx]
self.idx += 1
if __name__ == '__main__':
exp = '''''
veca = [1, 2, 3]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
'''
lex = Veclexer(exp)
t = lex.next_token()
while t[0] != EOF:
print t
t = lex.next_token()
运行这个程序,可以得到源代码:
veca = [1, 2, 3] print 'veca:', veca print 'veca * 2:', veca * 2 print 'veca + 2:', veca + 2
对应的token序列:
('ID', 'veca')
('EQUAL', '=')
('LBRACK', '[')
('INT', 1)
('COMMA', ',')
('INT', 2)
('COMMA', ',')
('INT', 3)
('RBRACK', ']')
('print', 'print')
('STR', 'veca:')
('COMMA', ',')
('ID', 'veca')
('print', 'print')
('STR', 'veca * 2:')
('COMMA', ',')
('ID', 'veca')
('TIMES', '*')
('INT', 2)
('print', 'print')
('STR', 'veca + 2:')
('COMMA', ',')
('ID', 'veca')
('ADD', '+')
('INT', 2)
接下来看一下语法解析器的实现。语法解析器的的输入是token流,根据一个向前看词法单元预测匹配的规则。对于每个遇到的非终结符调用对应的解析函数,而终结符(token)则match掉,如果不匹配则表示有语法错误。由于都是使用的LL(1),所以和词法解析器类似, 这里不再赘述。
'''''
A simple parser of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
example:
veca = [1, 2, 3]
vecb = veca + 4 # vecb: [1, 2, 3, 4]
vecc = veca * 3 # vecc:
Created on 2012-9-26
@author: bjzllou
'''
import veclexer
class Vecparser:
'''''
LL(1) parser.
'''
def __init__(self, lexer):
self.lexer = lexer
# lookahead token. Based on the lookahead token to choose the parse option.
self.cur_token = lexer.next_token()
# similar to symbol table, here it's only used to store variables' value
self.symtab = {}
def statlist(self):
while self.lexer.has_next():
self.stat()
def stat(self):
token_type, token_val = self.cur_token
# Asignment
if token_type == veclexer.ID:
self.consume()
# For the terminal token, it only needs to match and consume.
# If it's not matched, it means that is a syntax error.
self.match(veclexer.EQUAL)
# Store the value to symbol table.
self.symtab[token_val] = self.expr()
# print statement
elif token_type == veclexer.PRINT:
self.consume()
v = str(self.expr())
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v += ' ' + str(self.expr())
print v
else:
raise Exception('not support token %s', token_type)
def expr(self):
token_type, token_val = self.cur_token
if token_type == veclexer.STR:
self.consume()
return token_val
else:
v = self.multipart()
while self.cur_token[0] == veclexer.ADD:
self.consume()
v1 = self.multipart()
if type(v1) == int:
v.append(v1)
elif type(v1) == list:
v = v + v1
return v
def multipart(self):
v = self.primary()
while self.cur_token[0] == veclexer.TIMES:
self.consume()
v1 = self.primary()
if type(v1) == int:
v = [x*v1 for x in v]
elif type(v1) == list:
v = [x*y for x in v for y in v1]
return v
def primary(self):
token_type = self.cur_token[0]
token_val = self.cur_token[1]
# int
if token_type == veclexer.INT:
self.consume()
return token_val
# variables reference
elif token_type == veclexer.ID:
self.consume()
if token_val in self.symtab:
return self.symtab[token_val]
else:
raise Exception('undefined variable %s' % token_val)
# parse list
elif token_type == veclexer.LBRACK:
self.match(veclexer.LBRACK)
v = [self.expr()]
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v.append(self.expr())
self.match(veclexer.RBRACK)
return v
def consume(self):
self.cur_token = self.lexer.next_token()
def match(self, token_type):
if self.cur_token[0] == token_type:
self.consume()
return True
raise Exception('expecting %s; found %s' % (token_type, self.cur_token[0]))
if __name__ == '__main__':
prog = '''''
veca = [1, 2, 3]
vecb = [4, 5, 6]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
print 'veca + vecb:', veca + vecb
print 'veca + [11, 12]:', veca + [11, 12]
print 'veca * vecb:', veca * vecb
print 'veca:', veca
print 'vecb:', vecb
'''
lex = veclexer.Veclexer(prog)
parser = Vecparser(lex)
parser.statlist()
运行代码便会得到之前介绍中的输出内容。这个解释器极其简陋,只实现了基本的表达式操作,所以不需要构建语法树。如果要为列表语言添加控制结构,就必须实现语法树,在语法树的基础上去解释执行。

인기 기사


인기 기사

뜨거운 기사 태그

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7313
7313
 9
1625
14
1348
46
1260
25
1207
29
9
1625
14
1348
46
1260
25
1207
29


 Google AI, 개발자를 위한 Gemini 1.5 Pro 및 Gemma 2 발표
Jul 01, 2024 am 07:22 AM
Google AI, 개발자를 위한 Gemini 1.5 Pro 및 Gemma 2 발표
Jul 01, 2024 am 07:22 AM
Google AI, 개발자를 위한 Gemini 1.5 Pro 및 Gemma 2 발표

 여러 .NET 오픈 소스 AI 및 LLM 관련 프로젝트 프레임워크 공유
May 06, 2024 pm 04:43 PM
여러 .NET 오픈 소스 AI 및 LLM 관련 프로젝트 프레임워크 공유
May 06, 2024 pm 04:43 PM
여러 .NET 오픈 소스 AI 및 LLM 관련 프로젝트 프레임워크 공유




