

영문 원문: Jeffrey Richter
편집자: Zhao Yukai
링크 http://www.php.cn/
이전 기사에서는 Finalize 메서드를 실행하기 위한 .Net 가비지 수집의 기본 원리와 가비지 수집의 내부 메커니즘을 소개했습니다. 이번 기사에서는 약한 참조 객체, 세대, 멀티스레드 가비지 수집, 대형 객체를 살펴봅니다. 처리 및 가비지 수집 관련 성능 카운터.
약한 참조 객체부터 시작하겠습니다. 약한 참조 객체는 큰 객체로 인한 메모리 부담을 줄일 수 있습니다.
약한 참조
프로그램의 루트 개체가 개체를 가리킬 때 개체에 도달할 수 있으며 가비지 수집기가 이를 회수할 수 없습니다. 이를 개체에 대한 강한 참조라고 합니다. 강한 참조의 반대는 약한 참조입니다. 개체에 약한 참조가 있는 경우 가비지 수집기는 개체를 회수할 수 있지만 프로그램이 해당 개체에 액세스할 수도 있습니다. 무슨 일이야? 아래를 읽어주세요.
객체에 약한 참조만 있고 가비지 수집기가 실행 중인 경우 나중에 프로그램에서 객체에 액세스하면 액세스가 실패합니다. 반면에 약하게 참조된 개체를 사용하려면 프로그램이 먼저 개체에 대한 강력한 참조를 만들어야 합니다. 가비지 수집기가 개체를 수집하기 전에 프로그램이 개체에 대한 강력한 참조를 만든 경우에는 (강한 참조를 얻은 후) 가비지 수집기는 이 개체를 재활용할 수 없습니다. 이것은 약간 복잡합니다. 코드를 사용하여 설명하겠습니다.
void Method() {
//创建对象的强引用
Object o = new Object();
// 用一个短弱引用对象弱引用o.
WeakReference wr = new WeakReference(o);
o = null; // 移除对象的强引用
o = wr.Target; //尝试从弱引用对象中获得对象的强引用
if (o == null) {
// 如果对象为空说明对象已经被垃圾回收器回收掉了
} else {
// 如果垃圾回收器还没有回收此对象就可以继续使用对象了
}
}약한 개체가 필요한 이유는 무엇입니까? 일부 데이터는 생성하기 쉽지만 많은 메모리가 필요하기 때문입니다. 예를 들어, 사용자 하드 디스크의 모든 폴더와 파일 이름에 액세스해야 하는 프로그램이 있고, 프로그램에서 처음으로 데이터가 필요할 때 사용자 디스크에 액세스하여 데이터를 생성할 수 있습니다. 매번 데이터를 얻기 위해 디스크를 읽는 대신 데이터를 사용하여 사용자 파일 데이터를 얻습니다.
问题是这个数据可能相当大,需要相当大的内存。如果用户去操作程序的另外一部分功能了,这块相当大的内存就没有占用的必要了。你可以通过代码删除这些数据,但是如果用户马上切换到需要这块数据的功能上,你就必须重新从用户的磁盘上构建这个数据。弱引用为这种场景提供了一种简单有效的方案。
当用户切换到其他功能时,你可以为这个数据创建一个弱引用对象,并把对这个数据的强引用解除掉。这样如果程序占用的内存很低,垃圾回收操作就不会触发,弱引用对象就不会被回收掉;这样当程序需要使用这块数据时就可以通过一个强引用来获得数据,如果成功得到了对象引用,程序就没有必要再次读取用户的磁盘了。
WeakReference类型提供了两个构造函数:
WeakReference(object target); WeakReference(object target, bool trackResurrection);
target参数显然就是弱引用要跟踪的对象了。trackResurrection参数表示当对象的Finalize方法执行之后是否还要跟踪这个对象。默认这个参数是false。有关对象的复活请参考这里。
편의상, 부활된 객체를 추적하지 않는 약한 참조를 "짧은 약한 참조"라고 하고, 부활한 객체를 추적하는 약한 참조를 "긴 약한 참조"라고 합니다. 개체가 Finalize 메서드를 구현하지 않는 경우 긴 약한 참조와 짧은 약한 참조는 완전히 동일합니다. 길고 약한 참조를 사용하지 않는 것이 좋습니다. 긴 약한 참조를 사용하면 동작을 예측할 수 없는 부활된 개체를 사용할 수 있습니다.
WeakReference를 사용하여 객체를 참조한 후에는 이 객체의 모든 강력한 참조를 null로 설정하는 것이 좋습니다. 강력한 참조가 있는 경우 가비지 수집기는 약한 참조가 가리키는 객체를 회수할 수 없습니다. .
대상 객체에 대한 약한 참조를 사용하려면 대상 객체에 대한 강력한 참조를 생성해야 합니다. 이는 매우 간단합니다. 객체 a = weekRefer.Target을 사용한 다음 a가 비어 있는지 확인해야 합니다. 비어 있지 않은 경우에만 계속 사용할 수 있습니다. 약하게 비어 있으면 가비지 수집기에 의해 객체가 재활용되었음을 의미하므로 다른 방법을 통해 객체를 다시 획득해야 합니다.
약한 참조의 내부 구현
이전 설명을 보면 약한 참조 객체는 확실히 일반 객체와 다르게 처리된다는 것을 유추할 수 있습니다. 일반적으로 개체가 다른 개체를 참조하는 경우 이는 강력한 참조이며 가비지 수집기는 참조된 개체를 재활용할 수 없습니다. 그러나 WeakReference 개체의 경우에는 그렇지 않습니다.
약한 개체의 작동 방식을 완전히 이해하려면 관리되는 힙도 살펴봐야 합니다. 관리되는 힙에는 두 가지 내부 데이터 구조가 있습니다. 이들의 유일한 역할은 약한 참조를 관리하는 것입니다. 이를 긴 약한 참조 테이블이라고 부를 수 있으며, 이 두 테이블은 관리되는 힙에 약한 참조 대상 개체 포인터를 저장합니다.
프로그램 실행 시작 시 두 테이블이 모두 비어 있습니다. WeakReference 객체를 생성하면 관리되는 힙에 해당 객체가 할당되지 않고, Weak 객체 테이블에 빈 슬롯(Empty Slot)이 생성됩니다. 짧은 약한 참조 개체는 짧은 약한 참조 개체 테이블에 배치되고, 긴 약한 참조 개체는 긴 약한 참조 테이블에 배치됩니다.
빈 슬롯이 발견되면 빈 슬롯의 값은 약한 참조 대상 개체의 주소로 설정됩니다. 분명히 길고 짧은 약한 개체 테이블의 개체는 해당 개체의 루트 개체로 간주되지 않습니다. 애플리케이션. 가비지 수집기는 길고 짧은 약한 개체 테이블에서 데이터를 수집하지 않습니다.
가비지 수집이 실행되면 어떤 일이 발생하는지 살펴보겠습니다.
1. 가비지 수집기는 위의 구성 단계를 참조하세요. 약한 개체 테이블에서 가리키는 개체가 도달 가능한 개체 그래프에 없으면 해당 개체는 가비지 개체로 표시되고 짧은 개체 테이블의 개체 포인터는 null로 설정됩니다
3. 가비지 컬렉터 스캔 종료 큐(위 참조), 큐에 있는 객체가 도달 가능한 객체 그래프에 없으면 객체는 종료 큐에서 Freachable 큐로 이동됩니다. 이때 객체는 도달 가능한 것으로 표시됩니다. 개체이며 더 이상 쓰레기가 아닙니다
4. 가비지 수집기는 길고 약한 참조 테이블을 검색합니다. 테이블의 개체가 도달 가능한 개체 그래프에 없는 경우(접근 가능한 개체 그래프에 Freachable 대기열의 개체가 포함되어 있음) 긴 참조 개체 테이블의 해당 개체 포인터를 null로 설정합니다
5. 가비지 수집기는 연결 가능한 개체를 이동합니다. object
가비지 수집기의 작동 방식을 이해하고 나면 약한 참조가 작동하는 방식도 쉽게 이해할 수 있습니다. WeakReference의 Target 속성에 액세스하면 시스템이 약한 개체 테이블에 대상 개체 포인터를 반환하게 됩니다. null인 경우 개체가 재활용되었음을 의미합니다.
짧은 약한 참조는 부활을 추적하지 않습니다. 즉, 가비지 수집기가 마무리 대기열을 스캔하기 전에 약한 참조 테이블에서 가리키는 개체가 가비지 개체인지 여부를 확인할 수 있음을 의미합니다.
긴 약한 참조는 부활된 개체를 추적합니다. 이는 가비지 수집기가 개체가 재활용되었음을 확인한 후 약한 참조 테이블의 포인터를 null로 설정해야 함을 의미합니다.
세대: .Net에서 가비지 컬렉션을 수행할 때 C++ 또는 C 프로그래머는 이러한 방식으로 메모리를 관리하면 성능 문제가 발생하지 않을까 궁금해할 수 있습니다. GC 개발자는 성능을 향상시키기 위해 가비지 수집기를 지속적으로 조정하고 있습니다. 생성은 가비지 수집이 성능에 미치는 영향을 줄이기 위한 메커니즘입니다. 가비지 컬렉터는 작업 시 다음 진술이 참이라고 가정합니다.
1. 객체가 최신일수록 객체의 수명 주기가 짧아집니다.
2. 객체가 오래될수록 수명이 짧아집니다.
3. 새로운 객체는 일반적으로 새로운 객체와 참조 관계를 가질 가능성이 더 높습니다
4. 힙의 일부를 압축하는 것이 전체 힙을 압축하는 것보다 빠릅니다
물론, 많은 연구를 통해 위의 가정이 옳다는 것이 입증되었습니다. 많은 절차가 확립되었습니다. 이제 이러한 가정이 가비지 수집기 작업에 어떤 영향을 미치는지 이야기해 보겠습니다.
프로그램 초기화 시 관리되는 힙에는 개체가 없습니다. 이때, 관리되는 힙에 새로 추가된 개체는 0세대 개체입니다. 아래 그림과 같이 0세대 개체는 가장 어린 개체이며 가비지 수집기에서 한 번도 확인한 적이 없습니다.
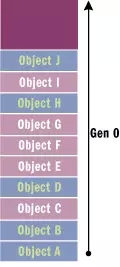
그림 1 관리되는 힙의 0세대 개체
이제 힙에 더 많은 항목이 추가되면 힙이 가득 차면 개체, 가비지 수집이 트리거됩니다. 가비지 수집기는 관리되는 힙을 분석할 때 가비지 개체(그림 2의 연한 보라색 블록)와 가비지가 아닌 개체의 그래프를 작성합니다. 재활용되지 않은 모든 객체는 힙 맨 아래로 이동되어 압축됩니다. 재활용되지 않은 이러한 개체는 그림 2
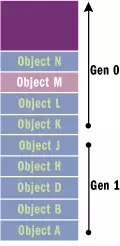
그림 2 관리형 힙 세대 0에 표시된 대로 1세대 개체가 됩니다.
에 1개 개체가 힙에 더 많이 할당되면 새 개체가 0세대 영역에 배치됩니다. 0세대 힙이 가득 차면 가비지 수집이 트리거됩니다. 이때 살아남은 개체는 1세대 개체가 되어 힙의 맨 아래로 이동되며, 가비지 수집이 발생한 후에는 1세대 개체에서 살아남은 개체가 2세대 개체로 승격되어 이동 및 압축됩니다. 그림 3에 표시된 대로:
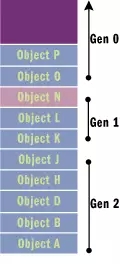
그림 3 관리되는 힙의 0, 1, 2세대 개체
2代对象是目前垃圾回收器的最高代,当再次垃圾回收时,没有回收的对象的代数依然保持2.
垃圾回收分代为什么可以优化性能
如前所述,分代回收可以提高性能。当堆填满之后会触发垃圾回收,垃圾回收器可以只选择0代上的对象进行回收,而忽略更高代堆上的对象。然而,由于越年轻的对象生命周期越短,因此,回收0代堆可以回收相当多的内存,而且回收所耗的性能也比回收所有代对象要少得多。
这是分代垃圾回收的最简单优化。分代回收不需要便利整个托管堆,如果一个根对象引用了一个高代对象,那么垃圾回收器可以忽略高代对象和其引用对象的遍历,这会大大减少构建可达对象图的时间。
如果回收0代对象没有释放出足够的内存,垃圾回收器会尝试回收1代和0代堆;如果仍然没有获得足够的内存,那么垃圾回收器会尝试回收2,1,0代堆。具体会回收那一代对象的算法不是确定的,微软会持续做算法优化。
多数堆(像c-runtime堆)只要找到足够的空闲内存就分配给对象。因此,如果我连续分配多个对象时,这些对象的地址空间可能会相差几M。然而在托管堆上,连续分配的对象的内存地址是连续的。
前面的假设中还提到,新对象之间更可能存在相互引用关系。因此新对象分配到连续的内存上,你可以获得就近引用的性能优化(you gain performance from locality of reference)。这样的话很可能你的对象都在CPU的缓存中,这样CPU的很多操作就不需要去存取内存了。
微软的性能测试显示托管堆的分配速度比标准的win32 HeapAlloc方法还要快。这些测试也显示了200MHz的Pentium的CPU做一次0代回收时间可以小于1毫秒。微软的优化目的是让垃圾回收耗用的时间小于一次普通的页面错误。
使用System.GC类控制垃圾回收
类型System.GC运行开发人员直接控制垃圾回收器。你可以通过GC.MaxGeneration属性获得GC的最高代数,目前最高代是定值2.
你可以调用GC.Collect()方法强制垃圾回收器做垃圾回收,Collect方法有两个重载:
void GC.Collect(Int32 generation) void GC.Collect()
第一个方法允许你指定要回收那一代。你可以传0到GC.MaxGeneration的数字做参数,传0只做0代堆的回收,传1会回收1代和0代堆,而传2会回收整个托管堆。而无参数的方法调用GC.Collect(GC.MaxGeneration)相当于整个回收。
在通常情况下,不应该去调用GC.Collect方法;最好让垃圾回收器按照自己的算法判断什么时候该调用Collect方法。尽管如此,如果你确信比运行时更了解什么时候该做垃圾回收,你就可以调用Collect方法去做回收。比如说程序可以在保存数据文件之后做一次垃圾回收。比如你的程序刚刚用完一个长度为10000的大数组,你不再需要他了,就可以把它设置为null然后执行垃圾回收,缓解内存的压力。
GC还提供了WaitForPendingFinalizers方法。这个方法简单的挂起执行线程,知道Freachable队列中的清空之后,执行完所有队列中的Finalize方法之后才继续执行。
GC还提供了两个方法用来返回某个对象是几代对象,他们是
Int32 GC.GetGeneration(object o); Int32 GC.GetGeneration(WeakReference wr)
第一个方法返回普通对象是几代,第二个方法返回弱引用对象的代数。
下面的代码可以帮助你理解代的意义:
private static void GenerationDemo() {
// Let's see how many generations the GCH supports (we know it's 2)
Display("Maximum GC generations: " + GC.MaxGeneration);
// Create a new BaseObj in the heap
GenObj obj = new GenObj("Generation");
// Since this object is newly created, it should be in generation 0
obj.DisplayGeneration(); // Displays 0
// Performing a garbage collection promotes the object's generation
GC.Collect();
obj.DisplayGeneration(); // Displays 1
GC.Collect();
obj.DisplayGeneration(); // Displays 2
GC.Collect();
obj.DisplayGeneration(); // Displays 2 (max generation)
obj = null; // Destroy the strong reference to this object
GC.Collect(0); // Collect objects in generation 0
GC.WaitForPendingFinalizers(); // We should see nothing
GC.Collect(1); // Collect objects in generation 1
GC.WaitForPendingFinalizers(); // We should see nothing
GC.Collect(2); // Same as Collect()
GC.WaitForPendingFinalizers(); // Now, we should see the Finalize
// method run
Display(-1, "Demo stop: Understanding Generations.", 0);
}
class GenObj{
public void DisplayGeneration(){
Console.WriteLine(“my generation is ” + GC.GetGeneration(this));
}
~GenObj(){
Console.WriteLine(“My Finalize method called”);
}
}垃圾回收机制的多线程性能优化
이전 부분에서는 GC 알고리즘과 최적화에 대해 설명했고, 이후 논의의 전제는 싱글 스레드 상황이었습니다. 실제 프로그램에서는 여러 스레드가 함께 작동하고 여러 스레드가 관리되는 힙의 개체를 함께 조작할 가능성이 높습니다. 스레드가 가비지 수집을 트리거하면 다른 모든 스레드는 참조된 개체(자체 스택에서 참조되는 개체 포함)에 대한 액세스를 일시 중단해야 합니다. 가비지 수집기가 개체를 이동하고 개체의 메모리 주소를 수정할 수 있기 때문입니다.
따라서 가비지 수집기가 재활용을 시작하면 관리 코드를 실행하는 모든 스레드가 중단되어야 합니다. 런타임에는 가비지 수집을 수행하기 위해 스레드를 안전하게 일시 중단하는 여러 가지 메커니즘이 있습니다. 이 작품의 내부 메커니즘에 대해서는 자세히 설명하지 않겠습니다. 그러나 Microsoft는 가비지 수집으로 인한 성능 손실을 줄이기 위해 가비지 수집 메커니즘을 계속 수정해 나갈 것입니다.
다음 단락에서는 다중 스레드 상황에서 가비지 수집기가 작동하는 방식을 설명합니다.
코드 실행을 완전히 중단합니다. 가비지 수집이 실행되기 시작하면 모든 애플리케이션 스레드를 일시 중단합니다. 그런 다음 가비지 수집기는 스레드의 일시 중지 위치를 JIT(Just-In-Time) 컴파일러에 의해 생성된 테이블에 기록합니다. 테이블에 스레드의 일시 중지 위치를 기록하고 현재 액세스 중인 개체의 위치를 기록합니다. 개체가 저장되는 위치(변수, CPU 레지스터 등)
하이재킹: 가비지 수집기는 반환 주소가 특수 메서드를 가리키도록 스레드의 스택을 수정할 수 있습니다. 스레드를 실행하고 일시 중단합니다. 스레드의 실행 경로를 변경하는 방법을 스레드 하이재킹이라고 합니다. 가비지 수집이 완료되면 스레드는 이전에 실행된 메서드로 돌아갑니다.
안전 포인트: JIT 컴파일러는 메서드를 컴파일할 때 특정 지점에 코드 조각을 삽입하여 GC가 중단되었는지 확인할 수 있습니다. 그런 경우 스레드는 가비지 수집이 완료될 때까지 기다리다가 중단됩니다. 실행을 다시 시작합니다. JIT 컴파일러가 검사 GC 코드를 삽입하는 위치를 "안전 지점"이라고 합니다.
스레드 하이재킹을 사용하면 관리되지 않는 코드를 실행하는 스레드가 가비지 수집 중에 실행될 수 있습니다. 비관리 코드가 관리되는 힙의 개체에 액세스하지 않는 경우에는 문제가 되지 않습니다. 이 스레드가 현재 비관리 코드를 실행하고 있다가 관리 코드 실행으로 돌아가면 스레드가 하이재킹되어 가비지 수집이 완료될 때까지 실행을 계속하지 않습니다.
방금 언급한 중앙 집중화 메커니즘 외에도 가비지 수집기에는 다중 스레드 프로그램에서 개체 메모리 할당 및 재활용을 향상시키는 다른 개선 사항이 있습니다.
동기화 없는 할당: 멀티 스레드 시스템에서는 0세대 힙이 여러 영역으로 나누어지고 하나의 스레드가 하나의 영역을 사용합니다. 이를 통해 하나의 스레드가 힙을 독점적으로 소유할 필요 없이 여러 스레드가 동시에 개체를 할당할 수 있습니다.
확장 가능한 컬렉션: 다중 스레드 시스템에서 서버 버전의 실행 엔진(MXSorSvr.dll)을 실행합니다. 관리되는 힙은 각 CPU마다 하나씩 여러 영역으로 나뉩니다. 재활용이 초기화되면 각 CPU는 재활용 스레드를 실행하고 각 스레드는 자신의 영역을 회수합니다. 실행 엔진(MXCorWks.dll)의 워크스테이션 버전은 이 기능을 지원하지 않습니다.
대형 개체 재활용
이 섹션은 번역되지 않습니다. 이에 대해 설명하는 특별 기사가 있습니다
가비지 수집 모니터링
.Net 프레임워크를 설치한 경우 성능 카운터(시작 메뉴-관리 도구-성능 입력)에 .Net CLR 메모리 항목이 있어야 합니다. 아래 그림과 같이 인스턴스 목록에서 관찰할 프로그램을 선택할 수 있습니다.
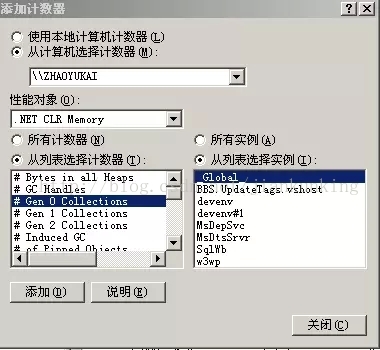
본 성과지표의 구체적인 의미는 다음과 같습니다.
성능 카운터 |
설명 |
모든 힙의 #바이트 |
다음 카운터 값의 합계를 표시합니다. "레벨 0 힙 크기" 카운터, "레벨 1" 힙 크기 카운터, 레벨 2 힙 크기 카운터 및 대형 개체 힙 크기 카운터입니다. 이 카운터는 가비지 수집 힙에 할당된 현재 메모리(바이트)를 나타냅니다. |
# GC Handles(GC 핸들 수) |
가비지 컬렉션을 표시합니다. use 현재 프로세스 수입니다. 가비지 수집은 공용 언어 런타임 및 호스팅 환경 외부의 리소스를 처리하는 것입니다. |
# Gen 0 컬렉션(레벨 2 재활용 수) |
신청에서 표시 프로그램이 시작된 이후 수준 0 개체(즉, 가장 젊고 가장 최근에 할당된 개체)가 가비지 수집된 횟수입니다. 레벨 0 가비지 수집은 할당 요청을 충족하기 위해 레벨 0에서 사용 가능한 메모리가 부족할 때 발생합니다. 이 카운터는 수준 0 가비지 수집이 끝나면 증가합니다. 상위 수준 가비지 수집에는 모든 하위 수준 가비지 수집이 포함됩니다. 이 카운터는 더 높은 수준(수준 1 또는 수준 2) 가비지 수집이 발생할 때 명시적으로 증가됩니다. 이 카운터는 가장 최근에 관찰된 값을 표시합니다. _Global_ 카운터 값이 정확하지 않으므로 무시해야 합니다. |
#1세대 컬렉션(2차 재활용 수) |
신청서에서 표시 프로그램이 시작된 후 수준 1 개체가 가비지 수집되는 횟수입니다. 이 카운터는 레벨 1 가비지 수집이 끝나면 증가합니다. 상위 수준 가비지 수집에는 모든 하위 수준 가비지 수집이 포함됩니다. 이 카운터는 더 높은 수준(수준 2) 가비지 수집이 발생할 때 명시적으로 증가됩니다. 이 카운터는 가장 최근에 관찰된 값을 표시합니다. _Global_ 카운터 값이 정확하지 않으므로 무시해야 합니다. |
# Gen 2 컬렉션(레벨 2 컬렉션 수) |
애플리케이션에서 표시 프로그램이 시작된 이후 수준 2 개체가 가비지 수집된 횟수입니다. 이 카운터는 레벨 2 가비지 수집(전체 가비지 수집이라고도 함)이 끝나면 증가합니다. 이 카운터는 가장 최근에 관찰된 값을 표시합니다. _Global_ 카운터 값이 정확하지 않으므로 무시해야 합니다. |
# Induced GC(발생한 GC 수) |
GC 기한을 표시합니다. .Collect에 대한 명시적 호출로 인해 수행된 가비지 수집의 최대 수입니다. 가비지 수집기가 수집 빈도를 미세 조정하도록 하는 것이 실용적입니다. |
# of Pinned Objects(고정된 개체 수) |
마지막 가비지 컬렉션 표시 개수 에서 발견된 고정된 개체의 수입니다. 고정된 개체는 가비지 수집기가 메모리로 이동할 수 없는 개체입니다. 이 카운터는 가비지 수집 힙에 고정된 개체만 추적합니다. 예를 들어, 수준 0 가비지 수집을 수행하면 수준 0 힙에 고정된 개체만 열거됩니다. |
사용 중인 싱크 블록 수 |
현재 동기화 블록 수를 표시합니다. 사용. 동기화 블록은 동기화 정보를 저장하기 위해 할당된 객체 기반의 데이터 구조이다. 동기화된 블록은 관리되는 개체에 대한 약한 참조를 보유하며 가비지 수집기에서 검색해야 합니다. 동기화 블록은 동기화 정보만 저장하는 것으로 제한되지 않고 COM interop 메타데이터도 저장할 수 있습니다. 이 카운터는 동기화 프리미티브의 남용과 관련된 성능 문제를 나타냅니다. |
# 총 커밋 바이트(총 커밋 바이트 수) |
가비지 컬렉션 표시 현재 서버에서 커밋된 가상 메모리의 양(바이트)입니다. 커밋된 메모리는 디스크 페이징 파일에 예약된 공간의 물리적 메모리입니다. |
# 총 예약 바이트 수(총 예약 바이트 수) |
가비지 수집 표시 현재 서버에서 예약한 가상 메모리의 양(바이트)입니다. 예약된 메모리는 애플리케이션용으로 예약된 가상 메모리 공간입니다(아직 디스크나 메인 메모리 페이지를 사용하지 않은 공간). |
% Time in GC(GC 시간의 백분율) |
마지막 이후의 시간을 표시합니다. 가비지 수집 주기 후 가비지 수집을 수행하는 데 소요된 실행 시간의 비율입니다. 이 카운터는 일반적으로 메모리를 수집하고 압축하기 위해 애플리케이션을 대신하여 가비지 수집기가 수행하는 작업을 나타냅니다. 이 카운터는 각 가비지 수집이 끝날 때만 업데이트됩니다. 이 카운터는 평균이 아니며 해당 값은 가장 최근 관찰을 반영합니다. |
할당된 바이트/초(초당 할당된 바이트 수) |
표시 초당 가비지 수집 힙에 할당된 바이트 수입니다. 이 카운터는 각 할당이 아닌 각 가비지 수집이 끝날 때 업데이트됩니다. 이 카운터는 시간 경과에 따른 평균이 아니며, 가장 최근의 두 샘플에서 관찰된 값 간의 차이를 샘플 간 시간으로 나눈 값을 표시합니다. |
Finalization Survivors(완료 시 남은 개체 수) |
이 표시되는 이유는 다음과 같습니다. 완료를 기다리고 있습니다. 수집 후 가비지 수집을 위해 보관된 객체 수입니다. 이러한 개체가 다른 개체에 대한 참조를 유지하는 경우 해당 개체는 유지되지만 이 카운터에 의해 계산되지는 않습니다. 수준 0에서 승격된 완료 메모리 및 수준 1에서 승격된 완료 메모리 카운터는 완료로 인해 유지되는 모든 메모리를 나타냅니다. 이 카운터는 누적 카운터가 아니며 각 가비지 수집이 끝날 때 특정 수집 중에만 살아남은 개체 수로 업데이트됩니다. 이 카운터는 신청 완료로 인해 과도한 시스템 오버헤드가 있을 수 있음을 나타냅니다. |
Gen 0 힙 크기 |
레벨 0에 할당할 수 있는 최대 바이트 수를 표시합니다. 이는 레벨 0에 할당된 현재 바이트 수를 나타내지 않습니다. 가장 최근 수집이 이 크기를 초과하므로 할당이 할당되면 레벨 0 가비지 수집이 발생합니다. 수준 0 크기는 가비지 수집기에 의해 미세 조정되며 애플리케이션 실행 중에 변경될 수 있습니다. 레벨 0 수집이 끝나면 레벨 0 힙의 크기는 0바이트입니다. 이 카운터는 다음 수준 0 가비지 수집을 호출하는 할당의 크기(바이트)를 표시합니다. 이 카운터는 가비지 수집이 끝날 때 업데이트됩니다(각 할당이 아님). |
0세대 승격된 바이트/초(레벨 1에서 승격된 바이트/초) |
레벨 0부터 레벨 1까지 초당 바이트 수를 표시합니다. 메모리는 가비지 수집에서 보관된 후 승격됩니다. 이 카운터는 초당 생성되어 상당한 기간 동안 유지된 개체를 나타냅니다. 이 카운터는 마지막 두 샘플에서 관찰된 값의 차이를 샘플링 간격 기간으로 나눈 값을 표시합니다. |
Gen 1 힙 크기(레벨 2 힙 크기) |
1번째 표시 현재 레벨의 바이트 수. 이 카운터는 레벨 1의 최대 크기를 표시하지 않습니다. 이 세대에서는 개체가 직접 할당되지 않습니다. 이러한 개체는 이전 수준 0 가비지 수집에서 승격됩니다. 이 카운터는 가비지 수집이 끝날 때 업데이트됩니다(각 할당이 아닌). |
1세대 승격 바이트/초(레벨 1/초에서 승격된 바이트) |
레벨 1에서 레벨 2로 승격된 초당 바이트 수를 표시합니다. 단지 완료를 기다리고 있다는 이유만으로 승격된 개체는 이 카운터에 포함되지 않습니다. 메모리는 가비지 컬렉션에서 보관된 후 승격됩니다. 2레벨은 가장 오래된 레벨이므로 승격은 없습니다. 이 카운터는 초당 생성되는 수명이 매우 긴 개체를 나타냅니다. 이 카운터는 마지막 두 샘플에서 관찰된 값의 차이를 샘플링 간격 기간으로 나눈 값을 표시합니다. |
Gen 2 힙 크기 |
Gen 2 표시 수준. 이 세대에서는 개체가 직접 할당되지 않습니다. 이러한 개체는 이전 수준 1 가비지 수집 중에 수준 1에서 승격되었습니다. 이 카운터는 가비지 수집이 끝날 때 업데이트됩니다(각 할당이 아닌). |
대형 개체 힙 크기 |
대형 개체 힙 표시 현재 크기, in 바이트. 가비지 수집기는 20KB보다 큰 개체를 대형 개체로 처리하고 이러한 수준을 통해 승격되지 않는 특수 힙에 직접 대형 개체를 할당합니다. 이 카운터는 가비지 수집이 끝날 때 업데이트됩니다(각 할당이 아닌). |
Gen 0에서 승격된 최종화-메모리 |
메모리 바이트 수를 표시합니다. 완료를 기다리기만 하면 레벨 0에서 레벨 1로 승격됩니다. 이 카운터는 누적 카운터가 아니며 마지막 가비지 수집이 끝날 때 관찰된 값을 표시합니다. |
1세대에서 승격된 최종화-메모리 |
완료 대기로 인해 레벨 1에서 레벨 2로 승격된 메모리의 바이트 수를 표시합니다. 이 카운터는 누적 카운터가 아니며 마지막 가비지 수집이 끝날 때 관찰된 값을 표시합니다. 마지막 가비지 수집이 수준 0 수집인 경우 이 카운터는 0으로 재설정됩니다. |
Gen 0에서 승격된 메모리 |
이후에 유지되는 메모리 바이트 수를 표시합니다. 가비지 수집을 수행하고 레벨 0에서 레벨 1로 승격됩니다. 완료를 기다리는 동안에만 발생하는 개체는 이 카운터에서 제외됩니다. 이 카운터는 누적 카운터가 아니며 마지막 가비지 수집이 끝날 때 관찰된 값을 표시합니다. |
1세대에서 승격된 메모리 |
이후에 유지되는 메모리 바이트 수를 표시합니다. 가비지 수집을 통해 레벨 1에서 레벨 2로 승격됩니다. 완료를 기다리는 동안에만 발생하는 개체는 이 카운터에서 제외됩니다. 이 카운터는 누적 카운터가 아니며 마지막 가비지 수집이 끝날 때 관찰된 값을 표시합니다. 마지막 가비지 수집이 수준 0 수집인 경우 이 카운터는 0으로 재설정됩니다. |
이 표는 MSDN에서 가져온 것입니다.
위 내용은 .Net 가비지 수집 메커니즘 원칙(2)의 내용입니다. PHP 중국어 넷(www.php.cn)을 주목해주세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



