
버퍼는 실제로 쓰거나 읽을 일부 데이터가 포함된 컨테이너 개체입니다. NIO에 Buffer 객체를 추가하면 새 라이브러리와 원래 I/O 간의 중요한 차이점이 반영됩니다. 스트림 지향 I/O에서는 Stream 개체에 직접 데이터를 쓰거나 읽습니다.
NIO 라이브러리에서는 모든 데이터를 버퍼를 사용하여 처리합니다. 데이터를 읽을 때 버퍼로 직접 읽혀집니다. 데이터가 기록되면 버퍼에 기록됩니다. NIO의 데이터에 액세스할 때마다 해당 데이터를 버퍼에 넣습니다.
버퍼는 기본적으로 배열입니다. 일반적으로 바이트 배열이지만 다른 종류의 배열도 사용할 수 있습니다. 그러나 버퍼는 단순한 배열 그 이상입니다. 버퍼는 데이터에 대한 구조화된 액세스를 제공하고 시스템의 읽기/쓰기 프로세스를 추적할 수도 있습니다.
가장 일반적으로 사용되는 버퍼 유형은 ByteBuffer입니다. ByteBuffer는 기본 바이트 배열에서 가져오기/설정 작업(즉, 바이트 획득 및 설정)을 수행할 수 있습니다.
ByteBuffer는 NIO의 유일한 버퍼 유형이 아닙니다. 실제로 모든 기본 Java 유형에는 버퍼 유형이 있습니다(부울 유형에만 해당 버퍼 클래스가 없음):
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
각 Buffer 클래스는 Buffer 인터페이스의 인스턴스입니다. ByteBuffer를 제외하고 각 Buffer 클래스는 정확히 동일한 작업을 수행하지만 처리하는 데이터 유형은 다릅니다. 대부분의 표준 I/O 작업은 ByteBuffer를 사용하기 때문에 모든 공유 버퍼 작업과 일부 고유 작업이 있습니다. Buffer의 클래스 계층 다이어그램을 살펴보겠습니다. 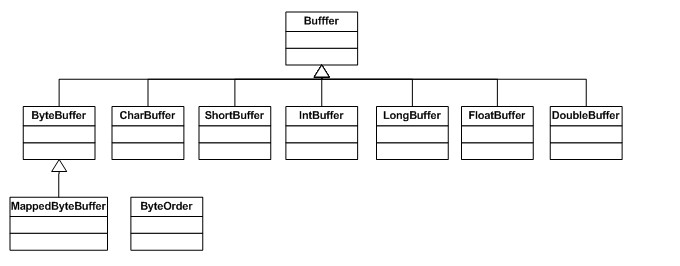
각 버퍼에는 다음과 같은 속성이 있습니다.
capacity
이 버퍼가 보유할 수 있는 최대 데이터 양입니다. 용량은 일반적으로 버퍼가 생성될 때 지정됩니다.
limit
버퍼에서 수행되는 읽기 및 쓰기 작업은 이 첨자를 초과할 수 없습니다. 버퍼에 데이터를 쓸 때 제한은 일반적으로 용량과 같습니다. 데이터를 읽을 때 제한은 버퍼에 있는 유효한 데이터의 길이를 나타냅니다.
위치
위치 변수는 버퍼에 쓰거나 버퍼에서 읽는 데이터의 양을 추적합니다.
보다 정확하게는 채널에서 버퍼로 데이터를 읽을 때 다음 데이터가 배열의 어느 요소에 배치될 것인지를 나타냅니다. 예를 들어, 채널에서 버퍼로 3바이트를 읽는 경우 버퍼의 위치는 3으로 설정되어 배열의 4번째 요소를 가리킵니다. 반대로, 쓰기 채널용 버퍼에서 데이터를 가져오면 다음 데이터가 배열의 어느 요소에서 나오는지 나타냅니다. 예를 들어, 버퍼에서 채널로 5바이트를 쓰면 버퍼의 위치는 배열의 6번째 요소를 가리키는 5로 설정됩니다.
mark
임시 저장 위치 인덱스입니다. mark()를 호출하면 mark가 현재 위치 값으로 설정되고 나중에 재설정()을 호출하면 position 속성이 mark 값으로 설정됩니다. mark 값은 항상 position 값보다 작거나 같습니다. position 값이 mark보다 작게 설정되면 현재 mark 값이 삭제됩니다.
이러한 속성은 항상 다음 조건을 충족합니다.
0 <= mark <= position <= limit <= capacity
버퍼의 내부 구현 메커니즘:
아래에서는 입력 채널에서 출력 채널로 데이터를 복사하는 예를 들어 각 변수를 자세히 분석하고 설명하겠습니다. 함께 작동하는 방식:
초기 변수:
먼저 ByteBuffer를 예로 들어 새로 생성된 버퍼를 관찰합니다. 버퍼 크기가 8바이트라고 가정하면 ByteBuffer의 초기 상태는 다음과 같습니다. 다음은 다음과 같습니다. 
한도는 용량보다 클 수 없으며 이 예에서는 두 값 모두 8로 설정되어 있습니다. 배열의 끝(슬롯 8) 뒤를 가리켜 이를 설명합니다. 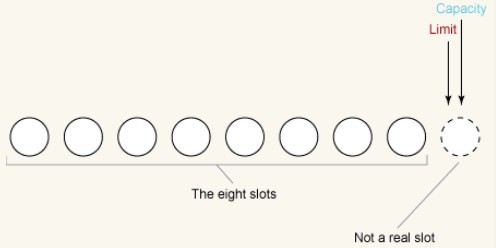
그런 다음 위치를 0으로 설정합니다. 일부 데이터를 버퍼로 읽으면 다음으로 읽은 데이터가 슬롯 0에 들어갈 것임을 나타냅니다. 버퍼에서 일부 데이터를 쓰면 버퍼에서 읽은 다음 바이트는 슬롯 0에서 나옵니다. 위치 설정은 다음과 같습니다. 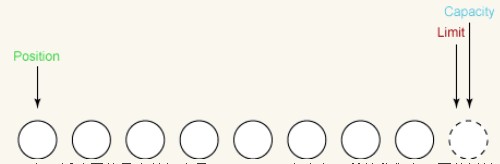
버퍼의 최대 데이터 용량은 변하지 않으므로 다음 논의에서는 무시해도 됩니다.
첫 번째 읽기:
이제 새로 생성된 버퍼에 대한 읽기/쓰기 작업을 시작할 수 있습니다. 먼저 입력 채널의 일부 데이터를 버퍼로 읽어옵니다. 첫 번째 읽기에서는 3바이트를 얻습니다. 0으로 설정된 위치에서 시작하여 배열에 배치됩니다. 읽은 후에는 아래와 같이 위치가 3으로 늘었고, 한도는 변하지 않았습니다. 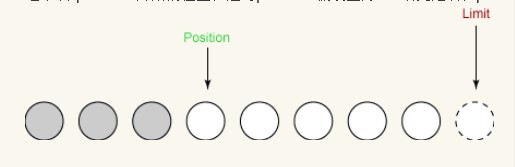
두 번째 읽기:
두 번째 읽기에서는 입력 채널에서 버퍼로 또 다른 2바이트를 읽습니다. 이 2바이트는 position으로 지정된 위치에 저장되므로 position은 2만큼 증가하고 제한은 변경되지 않습니다. 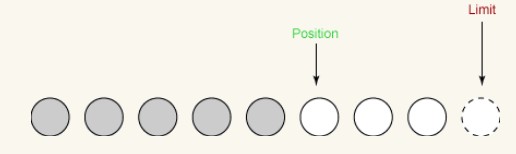
flip:
이제 출력 채널에 데이터를 쓰고 싶습니다. 그 전에 Flip() 메서드를 호출해야 합니다. 소스 코드는 다음과 같습니다.
public final Buffer flip()
{
limit = position;
position = 0;
mark = -1;
return this;
}
这个方法做两件非常重要的事:
i 它将limit设置为当前position。
ii 它将position设置为0。이전 그림은 뒤집기 전의 버퍼를 보여줍니다. 뒤집힌 후의 버퍼는 다음과 같습니다. 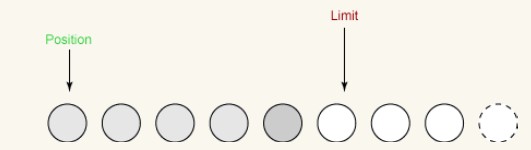
이제 버퍼에서 채널로 데이터를 쓸 수 있습니다. position은 0으로 설정됩니다. 이는 우리가 얻는 다음 바이트가 첫 번째 바이트임을 의미합니다. 제한은 원래 위치로 설정되었습니다. 즉, 이전에 읽은 모든 바이트가 포함되며 그 이상은 1바이트도 포함되지 않습니다.
첫 번째 쓰기:
첫 번째 쓰기에서는 버퍼에서 4바이트를 가져와 출력 채널에 씁니다. 이렇게 하면 위치가 4로 증가하고 제한은 그대로 유지됩니다. 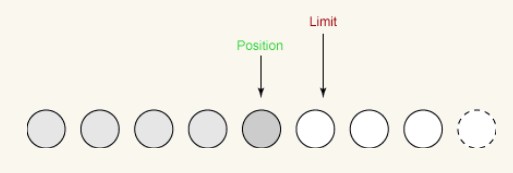
두 번째 쓰기:
이제 1바이트만 남게 됩니다. 쓸 수 있습니다. Flip()을 호출할 때 제한은 5로 설정되며 위치는 제한을 초과할 수 없습니다. 따라서 마지막 쓰기 작업은 버퍼에서 바이트를 가져와 출력 채널에 씁니다. 그러면 다음과 같이 위치가 5로 증가하고 제한은 변경되지 않습니다. 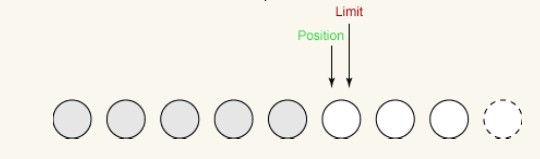
clear:
마지막 단계는 버퍼의clear() 메서드를 호출하는 것입니다. 이 메서드는 더 많은 바이트를 수신하도록 버퍼를 재설정합니다. 소스 코드는 다음과 같습니다.
public final Buffer clear()
{
osition = 0;
limit = capacity;
mark = -1;
return this;
}clear는 두 가지 매우 중요한 작업을 수행합니다.
i 용량과 동일하게 제한을 설정합니다.
ii 위치를 0으로 설정합니다.
다음 그림은 Clear()를 호출한 후 버퍼의 상태를 보여줍니다. 이제 버퍼는 새 데이터를 수신할 준비가 되었습니다. 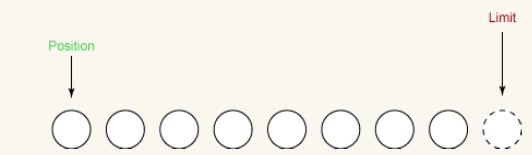
지금까지는 한 채널에서 다른 채널로 데이터를 전송하는 데 버퍼만 사용했습니다. 그러나 프로그램에서는 데이터를 직접 처리해야 하는 경우가 많습니다. 예를 들어 사용자 데이터를 디스크에 저장해야 할 수도 있습니다. 이 경우 이 데이터를 버퍼에 직접 넣은 다음 채널을 사용하여 버퍼를 디스크에 써야 합니다. 또는 디스크에서 사용자 데이터를 읽어야 할 수도 있습니다. 이 경우 채널의 데이터를 버퍼로 읽은 다음 버퍼에서 데이터를 확인합니다. 실제로 각 기본 유형의 버퍼는 버퍼의 데이터에 직접 액세스할 수 있는 메소드를 제공합니다. ByteBuffer를 예로 들어 ByteBuffer가 제공하는 get() 및 put() 메소드를 사용하여 데이터에 직접 액세스하는 방법을 분석해 보겠습니다. 데이터.
a) get()
ByteBuffer 클래스에는 4개의 get() 메서드가 있습니다.
byte get(); ByteBuffer get( byte dst[] ); ByteBuffer get( byte dst[], int offset, int length ); byte get( int index );
第一个方法获取单个字节。第二和第三个方法将一组字节读到一个数组中。第四个方法从缓冲区中的特定位置获取字节。那些返回ByteBuffer的方法只是返回调用它们的缓冲区的this值。 此外,我们认为前三个get()方法是相对的,而最后一个方法是绝对的。“相对”意味着get()操作服从limit和position值,更明确地说, 字节是从当前position读取的,而position在get之后会增加。另一方面,一个“绝对”方法会忽略limit和position值,也不会 影响它们。事实上,它完全绕过了缓冲区的统计方法。 上面列出的方法对应于ByteBuffer类。其他类有等价的get()方法,这些方法除了不是处理字节外,其它方面是是完全一样的,它们处理的是与该缓冲区类相适应的类型。
注:这里我们着重看一下第二和第三这两个方法
ByteBuffer get( byte dst[] ); ByteBuffer get( byte dst[], int offset, int length );
这两个get()主要用来进行批量的移动数据,可供从缓冲区到数组进行的数据复制使用。第一种形式只将一个数组 作为参数,将一个缓冲区释放到给定的数组。第二种形式使用 offset 和 length 参数来指 定目标数组的子区间。这些批量移动的合成效果与前文所讨论的循环是相同的,但是这些方法 可能高效得多,因为这种缓冲区实现能够利用本地代码或其他的优化来移动数据。
buffer.get(myArray)
等价于:
buffer.get(myArray,0,myArray.length);
注:如果您所要求的数量的数据不能被传送,那么不会有数据被传递,缓冲区的状态保持不 变,同时抛出 BufferUnderflowException 异常。因此当您传入一个数组并且没有指定长度,您就相当于要求整个数组被填充。如果缓冲区中的数据不够完全填满数组,您会得到一个 异常。这意味着如果您想将一个小型缓冲区传入一个大数组,您需要明确地指定缓冲区中剩 余的数据长度。上面的第一个例子不会如您第一眼所推出的结论那样,将缓冲区内剩余的数据 元素复制到数组的底部。例如下面的代码:
String str = "com.xiaoluo.nio.MultipartTransfer";
ByteBuffer buffer = ByteBuffer.allocate(50);
for(int i = 0; i < str.length(); i++)
{
buffer.put(str.getBytes()[i]);
}
buffer.flip();byte[] buffer2 = new byte[100];
buffer.get(buffer2);
buffer.get(buffer2, 0, length);
System.out.println(new String(buffer2));这里就会抛出java.nio.BufferUnderflowException异常,因为数组希望缓存区的数据能将其填满,如果填不满,就会抛出异常,所以代码应该改成下面这样:
//得到缓冲区未读数据的长度
int length = buffer.remaining();
byte[] buffer2 = new byte[100];
buffer.get(buffer2, 0, length);
b) put()ByteBuffer类中有五个put()方法:
ByteBuffer put( byte b );
ByteBuffer put( byte src[] );
ByteBuffer put( byte src[], int offset, int length );
ByteBuffer put( ByteBuffer src );
ByteBuffer put( int index, byte b );第一个方法 写入(put)单个字节。第二和第三个方法写入来自一个数组的一组字节。第四个方法将数据从一个给定的源ByteBuffer写入这个 ByteBuffer。第五个方法将字节写入缓冲区中特定的 位置 。那些返回ByteBuffer的方法只是返回调用它们的缓冲区的this值。 与get()方法一样,我们将把put()方法划分为“相对”或者“绝对”的。前四个方法是相对的,而第五个方法是绝对的。上面显示的方法对应于ByteBuffer类。其他类有等价的put()方法,这些方法除了不是处理字节之外,其它方面是完全一样的。它们处理的是与该缓冲区类相适应的类型。
c) 类型化的 get() 和 put() 方法
除了前些小节中描述的get()和put()方法, ByteBuffer还有用于读写不同类型的值的其他方法,如下所示:
getByte()
getChar()
getShort()
getInt()
getLong()
getFloat()
getDouble()
putByte()
putChar()
putShort()
putInt()
putLong()
putFloat()
putDouble()
事实上,这其中的每个方法都有两种类型:一种是相对的,另一种是绝对的。它们对于读取格式化的二进制数据(如图像文件的头部)很有用。
下面的内部循环概括了使用缓冲区将数据从输入通道拷贝到输出通道的过程。
while(true)
{
//clear方法重设缓冲区,可以读新内容到buffer里
buffer.clear();
int val = inChannel.read(buffer);
if(val == -1)
{
break;
}
//flip方法让缓冲区的数据输出到新的通道里面
buffer.flip();
outChannel.write(buffer);
}read()和write()调用得到了极大的简化,因为许多工作细节都由缓冲区完成了。clear()和flip()方法用于让缓冲区在读和写之间切换。
好了,缓冲区的内容就暂且写到这里,下一篇我们将继续NIO的学习–通道(Channel).
以上就是Java NIO 缓冲区学习笔记 的内容,更多相关内容请关注PHP中文网(www.php.cn)!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



