

미친 XML 연구 노트(9)------------스키마 내장형

XML 스키마 내장 유형:
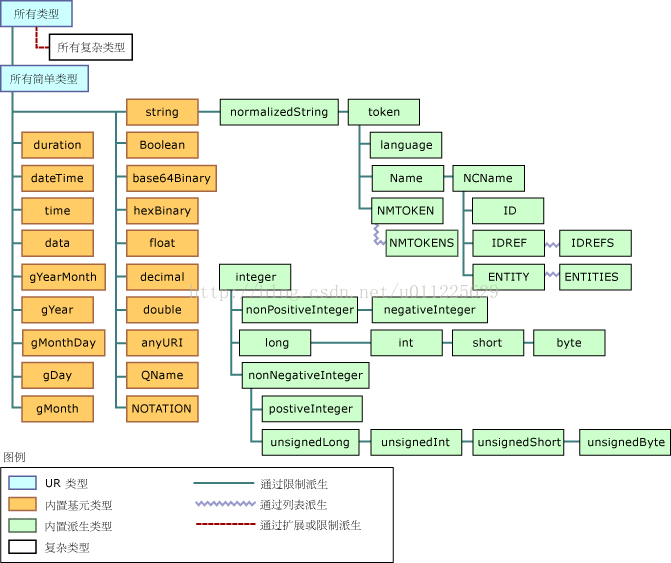
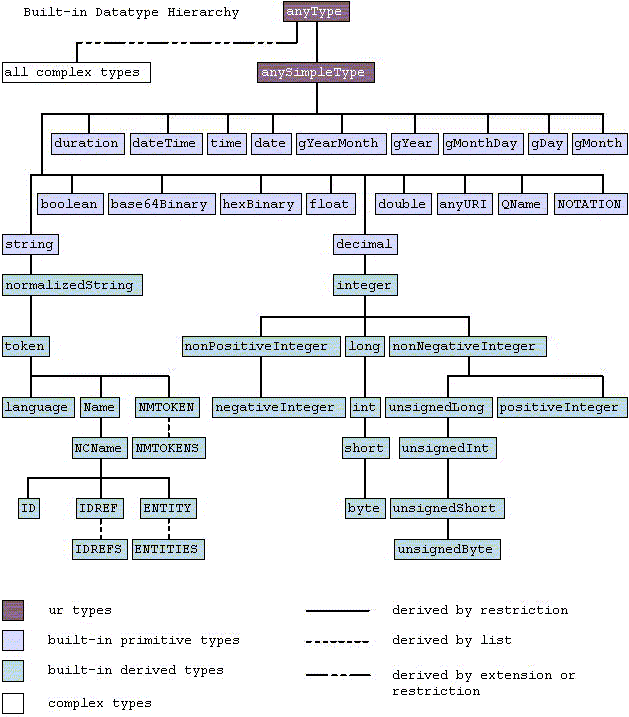
스키마 내장 유형 설명
| 표 2. XML 스키마에 내장된 단순 유형 | ||
|---|---|---|
| 단순 유형 | 예(쉼표로 구분) | 참고 |
| string | 전자식인지 확인 | |
| normalizedString | 전자식인지 확인 | (3) 참조 |
| 토큰 | 전자식인지 확인 | (4) |
| base64Binary 참조 | GpM7 | |
| hexBinary | 0FB7 | |
| 정수 | ... -1, 0, 1, ... | (2) 참조 |
| 긍정적 정수 | 1, 2, ... | (2) 참조 |
| negativeInteger | ... -2, -1 | (2) 참조 |
| 비음수 정수 | 0, 1, 2, ... | (2) 참조 |
| nonPositiveInteger | ... -2, -1, 0 | (2) 참조 |
| 길다 | -9223372036854775808, ... -1, 0, 1, ... 9223372036854775807 | (2) 참조 |
| unsignedLong | 0, 1, ... 18446744073709551615 | (2) 참조 |
| int | -2147483648 , ... -1, 0, 1, ... 2147483647 | (2) 참조 |
| unsignedInt | 0, 1, ...4294967295 | (2) 참조 |
| 짧게 | -32768, ... -1, 0, 1, ... 32767 | (2) 참조 |
| unsignedShort | 0, 1, ... 65535 | (2) |
| 바이트 | -128, ...-1, 0, 1, . .. 127 | (2) 참조 |
| unsignedByte | 0, 1, ... 255 | (2) 참조 |
| 십진수 | -1.23, 0, 123.4, 1000.00 | (2) 참조 |
| float | -INF, -1E4, -0, 0, 12.78E-2, 12, INF, NaN | 단정밀도 32-와 동일 비트 부동 소수점, NaN은 "숫자가 아님"입니다. (2) |
| double | -INF를 참조하세요. -1E4, -0, 0, 12.78E-2, 12, INF, NaN | 배정밀도 64비트 부동 소수점과 동일합니다. (2) |
| 부울 | 참, 거짓, 1, 0 | |
| 기간 | P1Y2M3DT10H30M12.3S | 1년, 2개월, 3일, 10시간 30분 12.3초 |
| dateTime | 1999-05-31T13:20:00.000- 05:00 | 1999년 5월 31일 오후 1시 20분 동부 표준시(협정 세계시보다 5시간 늦음), (2) 참조 |
| 날짜 | 1999-05-31 | (2) 참조 |
| 시간 | 13:20:00.000, 13:20:00.000-05:00 | (2) 참조 |
| g연도 | 1999 | 1999, (2) (5) 참조 |
| gYearMonth | 1999-02 | 2월 1999, 일수에 관계없이 (2) (5) |
| gMonth | --05 참조 | 5월 (2)(5) 보기 |
| gMonthDay | --05-31 | 매년 5월 31일 (2)(5) |
| gDay | ---31 | 31일 (2)(5) |
| 이름 | 배송지 | XML 1.0 이름 유형 |
| QName | po:USAddress | XML 네임스페이스 QName |
| NCName | USAddress | XML 네임스페이스 NCName, 즉 접두사와 콜론이 없는 QName |
| 모든URI | http://www.php.cn/,http://www.php.cn/ | |
| 언어 | en-GB, en-US, fr | XML 1.0에 정의된 xml:lang의 유효한 값 |
| ID | XML 1.0 ID 속성 유형, (1) 참조 | |
| IDREF | XML 1.0 IDREF 속성 유형, (1) 참조 | |
| IDREFS | XML 1.0 IDREFS 속성 유형, (1) 참조 | |
| ENTITY | XML 1.0 ENTITY 속성 유형, (1) 참조 | |
| ENTITIES | XML 1.0 ENTITIES 속성 유형, (1) 참조 | |
| 표기 | XML 1.0 NOTATION 속성 유형, (1) 참조 | |
| NMTOKEN | US,Brésil | XML 1.0 NMTOKEN 속성 유형, (1) 참조 |
| NMTOKENS | 미국 영국, 브라질 캐나다 멕시코 | XML 1.0 NMTOKENS 속성 유형, 즉 공백으로 구분된 NMTOKEN 목록, (1) |
|
참고: (1) XML 스키마와 XML 1.0 DTD 간의 호환성을 유지하려면 단순 유형 ID, IDREF, IDREFS, ENTITY , ENTITIES, NOTATION, NMTOKEN, NMTOKENS는 속성에만 사용해야 합니다. (2) 이 유형의 값은 둘 이상의 어휘 형식으로 표시될 수 있습니다. 100과 1.0E2는 모두 "100"을 나타내는 유효한 부동 소수점 형식입니다. 그러나 이 유형에 대해 표준을 정의하는 규칙이 확립되었습니다. 어휘 형식은 XML 스키마 파트 2를 참조하세요. (3) 정규화된 문자열 유형의 줄 바꿈, 탭 및 캐리지 리턴 문자가 변환됩니다. 스키마 처리 전에 공백 문자로 변환합니다. (4) 정규화된 문자열이므로 인접한 공백 문자는 단일 공백 문자로 축소되고 앞뒤 공백이 제거됩니다. (5) "g" 접두어는 그레고리력의 기간을 나타냅니다. | ||
위 내용은 이상합니다. XML 학습 노트 (9)------------스키마 내장형 콘텐츠, 더 많은 관련 콘텐츠를 보려면 PHP 중국어 웹사이트(www.php.cn)를 참고하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7517
7517
 15
1378
52
79
11
53
19
21
66
15
1378
52
79
11
53
19
21
66

 PowerPoint를 사용하여 XML 파일을 열 수 있나요?
Feb 19, 2024 pm 09:06 PM
PowerPoint를 사용하여 XML 파일을 열 수 있나요?
Feb 19, 2024 pm 09:06 PM
XML 파일을 PPT로 열 수 있나요? XML, Extensible Markup Language(Extensible Markup Language)는 데이터 교환 및 데이터 저장에 널리 사용되는 범용 마크업 언어입니다. HTML에 비해 XML은 더 유연하고 자체 태그와 데이터 구조를 정의할 수 있으므로 데이터 저장과 교환이 더 편리하고 통합됩니다. PPT 또는 PowerPoint는 프레젠테이션 작성을 위해 Microsoft에서 개발한 소프트웨어입니다. 이는 포괄적인 방법을 제공합니다.
 Python을 사용하여 XML 데이터 병합 및 중복 제거
Aug 07, 2023 am 11:33 AM
Python을 사용하여 XML 데이터 병합 및 중복 제거
Aug 07, 2023 am 11:33 AM
Python을 사용하여 XML 데이터 병합 및 중복 제거 XML(eXtensibleMarkupLanguage)은 데이터를 저장하고 전송하는 데 사용되는 마크업 언어입니다. XML 데이터를 처리할 때 여러 XML 파일을 하나로 병합하거나 중복된 데이터를 제거해야 하는 경우가 있습니다. 이 기사에서는 Python을 사용하여 XML 데이터 병합 및 중복 제거를 구현하는 방법을 소개하고 해당 코드 예제를 제공합니다. 1. XML 데이터 병합 XML 파일이 여러 개인 경우 이를 병합해야 합니다.
 Python을 사용하여 XML 데이터 필터링 및 정렬
Aug 07, 2023 pm 04:17 PM
Python을 사용하여 XML 데이터 필터링 및 정렬
Aug 07, 2023 pm 04:17 PM
Python을 사용하여 XML 데이터 필터링 및 정렬 구현 소개: XML은 데이터를 태그 및 속성 형식으로 저장하는 일반적으로 사용되는 데이터 교환 형식입니다. XML 데이터를 처리할 때 데이터를 필터링하고 정렬해야 하는 경우가 많습니다. Python은 XML 데이터를 처리하는 데 유용한 많은 도구와 라이브러리를 제공합니다. 이 기사에서는 Python을 사용하여 XML 데이터를 필터링하고 정렬하는 방법을 소개합니다. XML 파일 읽기 시작하기 전에 XML 파일을 읽어야 합니다. Python에는 많은 XML 처리 라이브러리가 있습니다.
 Python에서 XML 데이터를 CSV 형식으로 변환
Aug 11, 2023 pm 07:41 PM
Python에서 XML 데이터를 CSV 형식으로 변환
Aug 11, 2023 pm 07:41 PM
Python의 XML 데이터를 CSV 형식으로 변환 XML(ExtensibleMarkupLanguage)은 데이터 저장 및 전송에 일반적으로 사용되는 확장 가능한 마크업 언어입니다. CSV(CommaSeparatedValues)는 데이터 가져오기 및 내보내기에 일반적으로 사용되는 쉼표로 구분된 텍스트 파일 형식입니다. 데이터를 처리할 때, 간편한 분석과 처리를 위해 XML 데이터를 CSV 형식으로 변환해야 하는 경우가 있습니다. 파이썬은 강력하다
 PHP를 사용하여 XML 데이터를 데이터베이스로 가져오기
Aug 07, 2023 am 09:58 AM
PHP를 사용하여 XML 데이터를 데이터베이스로 가져오기
Aug 07, 2023 am 09:58 AM
PHP를 사용하여 데이터베이스로 XML 데이터 가져오기 소개: 개발 중에 추가 처리 및 분석을 위해 외부 데이터를 데이터베이스로 가져와야 하는 경우가 많습니다. 일반적으로 사용되는 데이터 교환 형식인 XML은 구조화된 데이터를 저장하고 전송하는 데 자주 사용됩니다. 이 기사에서는 PHP를 사용하여 XML 데이터를 데이터베이스로 가져오는 방법을 소개합니다. 1단계: XML 파일 구문 분석 먼저 XML 파일을 구문 분석하고 필요한 데이터를 추출해야 합니다. PHP는 XML을 구문 분석하는 여러 가지 방법을 제공하며 그 중 가장 일반적으로 사용되는 방법은 Simple을 사용하는 것입니다.
 Python은 XML과 JSON 간의 변환을 구현합니다.
Aug 07, 2023 pm 07:10 PM
Python은 XML과 JSON 간의 변환을 구현합니다.
Aug 07, 2023 pm 07:10 PM
Python은 XML과 JSON 간의 변환을 구현합니다. 소개: 일상적인 개발 프로세스에서 우리는 종종 서로 다른 형식 간에 데이터를 변환해야 합니다. XML과 JSON은 일반적인 데이터 교환 형식입니다. Python에서는 다양한 라이브러리를 사용하여 XML과 JSON을 변환할 수 있습니다. 이 문서에서는 코드 예제와 함께 일반적으로 사용되는 몇 가지 방법을 소개합니다. 1. Python에서 XML을 JSON으로 변환하려면 xml.etree.ElementTree 모듈을 사용할 수 있습니다.
 Python을 사용하여 XML의 오류 및 예외 처리
Aug 08, 2023 pm 12:25 PM
Python을 사용하여 XML의 오류 및 예외 처리
Aug 08, 2023 pm 12:25 PM
Python을 사용하여 XML에서 오류 및 예외 처리하기 XML은 구조화된 데이터를 저장하고 표현하는 데 일반적으로 사용되는 데이터 형식입니다. Python을 사용하여 XML을 처리할 때 때때로 오류와 예외가 발생할 수 있습니다. 이 기사에서는 Python을 사용하여 XML의 오류 및 예외를 처리하는 방법을 소개하고 참조용 샘플 코드를 제공합니다. XML 구문 분석 오류를 잡기 위해 try-Exception 문을 사용하십시오. Python을 사용하여 XML을 구문 분석할 때 가끔 오류가 발생할 수 있습니다.
 Python은 XML의 특수 문자와 이스케이프 시퀀스를 구문 분석합니다.
Aug 08, 2023 pm 12:46 PM
Python은 XML의 특수 문자와 이스케이프 시퀀스를 구문 분석합니다.
Aug 08, 2023 pm 12:46 PM
Python은 XML의 특수 문자와 이스케이프 시퀀스를 구문 분석합니다. XML(eXtensibleMarkupLanguage)은 서로 다른 시스템 간에 데이터를 전송하고 저장하는 데 일반적으로 사용되는 데이터 교환 형식입니다. XML 파일을 처리할 때 특수 문자와 이스케이프 시퀀스가 포함되어 구문 분석 오류가 발생하거나 데이터가 잘못 해석될 수 있는 상황이 자주 발생합니다. 따라서 Python을 사용하여 XML 파일을 구문 분석할 때 이러한 특수 문자와 이스케이프 시퀀스를 처리하는 방법을 이해해야 합니다. 1. 특수문자 및
