

프로젝트를 개발하는 과정에서 최적화 개념이 항상 언급됩니다. 이 글은 MySQL 데이터 최적화 실습에 대한 탐색으로, 파티션 테이블 관리 방법과 간단한 파티셔닝 실습을 간략하게 소개합니다.
빅데이터를 운영할 때 데이터 테이블을 분할 정복하고, 대용량 데이터가 담긴 테이블을 분할한다 더 작은 운영 단위로 분류되면 각 운영 단위는 별도의 이름을 갖게 됩니다. 동시에, 프로그램 개발자에게 파티셔닝은 파티셔닝이 없는 것과 같습니다. 일반적으로 mysql 파티셔닝은 프로그램 응용 프로그램에 투명하며 데이터베이스에 의한 데이터 재배열일 뿐입니다.
파티션 기능 :
(1) 성능을 향상시킵니다.
파티셔닝의 궁극적인 목적은 성능을 향상시키는 것입니다. 파티셔닝이 완료된 후 mysql은 파티션마다 특정 데이터 파일과 인덱스 파일을 생성하고 검색 중에 특정 부분 데이터를 검색하므로 더 나은 데이터베이스 구현 및 유지 관리. 이는 분할된 테이블이 서로 다른 물리적 드라이브에 할당되어 동시에 여러 파티션에 액세스할 때 파티션의 물리적 I/O 경합이 줄어들기 때문입니다.
(2) 관리가 용이합니다.
파티셔닝 후 관리 데이터는 해당 파티션을 직접 관리할 수 있습니다. 작업은 간단합니다. 데이터가 수백만 개에 도달하면 파티션을 직접 작업하는 것이 데이터 테이블을 작업하는 것보다 훨씬 직접적입니다.
(3) 내결함성
파티션이 완료된 후 하나의 파티션이 파괴되면 다른 데이터는 영향을 받지 않습니다.
mysql의 파티셔닝 방법에는 RANGE 파티션, LIST 파티션, HASH 파티션, KEY 파티션이 있습니다.
RANGE 파티셔닝: 테이블을 직접 생성할 때 특정 필드의 값을 기준으로 파티션 관리를 수행합니다. 예:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date, salary int ) partition by range(salary) ( partition p1 values less than (1000), partition p2 values less than (2000), partition p3 values less than maxvalue );
LIST 파티션: RANG 파티션과 유사하지만 차이점은 목록 파티션이 해시 값이라는 것입니다. RANG 파티셔닝은 특정 필드 범위를 기반으로 합니다. 예:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by list(deptno) ( partition p1 values in (10,15), partition p2 values in (20,25), partition p3 values in (30,35) );
HASH 파티셔닝: 데이터가 미리 지정된 참고문헌의 파티션에 균등하게 분산되도록 보장합니다. 파티션은 열 값과 파티션 수에 따라 지정됩니다. 예:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by hash(year(birthdate)) partitions 4;
KEY 파티션: HASH 파티션과 유사하지만 하나 이상의 열 계산만 지원하는 KEY 파티션과는 다릅니다. , MySQL 서버는 정수 값을 포함하는 하나 이상의 열을 가져야 하는 자체 해시 함수를 제공합니다. 예:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by key(birthdate) partitions 4;
파티션 삭제:
alter table emp drop 파티션 p1;
해시 또는 키 파티션은 삭제할 수 없습니다.
여러 파티션을 한 번에 삭제, alter table emp drop 파티션 p1,p2;
파티션 추가:
변경 테이블 emp 추가 파티션(파티션 p3 값 미만(4000));
alter table empl add 파티션( 파티션 p3 값 (40));
파티션 재구성:
Reorganizepartition 키워드는 데이터 손실 없이 테이블의 일부 또는 전체 파티션을 수정할 수 있습니다. 파티션의 전체 범위는 분해 전후에 일관되어야 합니다.
alter table te
파티션 p1을 <으로 재구성 🎜>
(
파티션 p1 값 미만(100) ,
파티션 p3 값 미만(1000)
) ----데이터 손실 없음
파티션 병합:
파티션 병합: 2개의 파티션을 하나로 병합합니다.
변경 테이블 te
파티션 p1,p3 재구성
(파티션 p1 값 미만(1000));
----데이터 손실 없음
해시 파티션 테이블 재정의:
Alter table emp 파티션 by hash(salary ) 파티션 7;
---은 손실되지 않습니다. 데이터
범위 파티션 테이블 재정의:
변경 테이블 emp 파티션범위(급여)별
(
파티션 p1 값 미만(2000),
파티션 p2 값 미만(4000 )
) ----데이터 손실 없음
테이블의 모든 파티션 삭제:
변경 테이블 emp Removepartitioning;--데이터 손실 없음
파티션 재구축:
파티션에 저장된 기록을 모두 삭제한 후 다시 삽입하는 것과 같은 효과가 있습니다. 효과. 파티션 조각 모음에 사용할 수 있습니다.
ALTER TABLE emp 재구축 파티션p1,p2;
파티셔닝 최적화:
파티션에서 많은 수의 행이 삭제되거나 변수가 행 길이(즉, VARCHAR, BLOB 또는 TEXT 유형 열이 있음)가 여러 번 수정된 경우 "ALTER TABLE ... OPTIMIZE PARTITION"을 사용하여 사용되지 않은 공간을 회수하고 파티션 데이터 파일 조각 모음을 수행할 수 있습니다.
ALTER TABLE emp 최적화 p1,p2;
분석 파티션:
읽고 저장 파티션의 키 분포.
ALTER TABLE emp 분석 p1,p2;
파티션 패치:
손상된 파티션 패치 분할.
ALTER TABLE emp 수리 파티션 p1,p2;
파티션 확인:
파티션은 비파티션에 대해 CHECK TABLE을 사용하는 것과 거의 동일한 방식으로 확인할 수 있습니다. 파티션된 테이블.
ALTER TABLE emp CHECK 파티션 p1,p2;
这个命令可以告诉你表emp的分区p1,p2中的数据或索引是否已经被破坏。如果发生了这种情况,使用“ALTER TABLE ... REPAIR PARTITION”来修补该分区。
1. 创建分区表和不分区表:
-- 创建分区表 CREATE TABLE part_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null) PARTITION BY RANGE(year(c3)) (PARTITION p0 VALUES LESS THAN (1995), PARTITION p1 VALUES LESS THAN (1996) , PARTITION p2 VALUES LESS THAN (1997) , PARTITION p3 VALUES LESS THAN (1998) , PARTITION p4 VALUES LESS THAN (1999) , PARTITION p5 VALUES LESS THAN (2000) , PARTITION p6 VALUES LESS THAN (2001) , PARTITION p7 VALUES LESS THAN (2002) , PARTITION p8 VALUES LESS THAN (2003) , PARTITION p9 VALUES LESS THAN (2004) , PARTITION p10 VALUES LESS THAN (2010), PARTITION p11 VALUES LESS THAN (MAXVALUE) );
-- 创建没有分区表 CREATE TABLE nopart_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null)
2. 创建大数据操作环境。为了测试结果的准确度提高,需要表中存在大数据,通过以下事务可在数据表中创建800万条数据:
-- 创建生成数据事物
CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end; 执行事务:call load_part_tab(); ,因为执行此事务执行的时间很长,我只在表中插入了283304条数据。
创建完成一张表后,可以将该表的数据复制到未分区表,这样执行速度会很快:
insert into test.nopart_tab select * from test.part_tab
3. 查看分区表分区结构:
-- 查询分区情况 select partition_name part, partition_expression expr, partition_description descr, table_rows from information_schema.partitions where table_schema = schema() and table_name='part_tab';
执行结果:
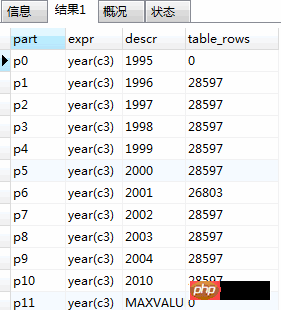
3. 测试速度:
执行分区表查询语句:
select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

执行未分区表查询语句:
select count(*) from nopart_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

从时间对比可以看出,同样的查询语句,分区表执行速度在20ms左右,未分区表在175ms左右,执行速度相差8倍左右,因此得出结论:分区表的执行速度要比未分区表执行速度快。
1. MySQL分区处理NULL值的方式
如果分区键所在列没有notnull约束。
如果是range分区表,那么null行将被保存在范围最小的分区。
如果是list分区表,那么null行将被保存到list为0的分区。
在按HASH和KEY分区的情况下,任何产生NULL值的表达式mysql都视同它的返回值为0。
为了避免这种情况的产生,建议分区键设置成NOT NULL。
2. 파티션 키는 INT 유형이거나 NULL일 수 있는 표현식을 통해 INT 유형을 반환해야 합니다. 유일한 예외는 파티션 유형이 KEY 파티셔닝인 경우 다른 유형의 열을 파티션 키로 사용할 수 있다는 것입니다(BLOB 또는 TEXT 열 제외).
3. 파티션 테이블의 파티션 키에 인덱스를 생성하면 이 인덱스도 전역적으로 분할되지 않습니다. 파티션 키에 대한 인덱스입니다.
4. RANG, LIST 파티션만 하위 파티션으로 나눌 수 있고, HASH, KEY 파티션으로는 하위 파티션으로 나눌 수 없습니다.
5. 임시 테이블은 파티션을 나눌 수 없습니다.
위 내용은 MySQL 최적화 실험(1) - 파티션 내용입니다. 더 많은 관련 내용은 PHP 중국어 홈페이지(www.php.cn)를 참고해주세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



