

C# 웹 크롤러 코드 및 검색 엔진 연구에 대한 자세한 소개

효과 페이지:
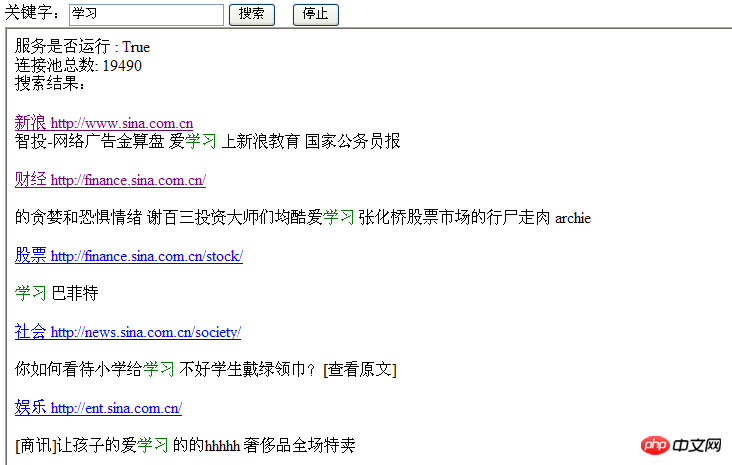
일반 아이디어:
입력 링크(예: www.sina.com.cn) , 거기에서 크롤링을 시작하고 링크를 찾습니다(여기서 웹페이지의 콘텐츠를 구문 분석하고, 키워드를 입력하고, 입력된 키워드가 포함되어 있는지 판단하고, 웹페이지의 링크 및 관련 콘텐츠를 캐시에 넣을 수 있습니다). 크롤링된 연결을 캐시에 넣고 재귀적으로 실행합니다.
작품이 비교적 단순해서 제가 직접 요약할 수 있어요.
동시에 10개의 스레드를 시작합니다. 각 스레드는 자체 연결 풀 캐시에 해당하고, 키워드가 포함된 모든 연결을 동일한 캐시에 넣고, 서비스 페이지를 준비하고, 정기적으로 새로 고치고, 현재 결과를 표시합니다(It만 해당) 실제 검색 엔진은 먼저 단어 분할을 사용하여 키워드를 분석한 다음 웹 콘텐츠를 결합하여 적합한 웹 페이지와 링크를 파일로 저장해야 합니다. 하루 24시간 크롤링합니다). 구체적인 구현을 살펴보겠습니다.
엔티티 클래스:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Threading;
namespace SpiderDemo.Entity
{
////爬虫线程
publicclass ClamThread
{
public Thread _thread { get; set; }
public List<Link> lnkPool { get; set; }
}
////爬到的连接
publicclass Link
{
public string Href { get; set; }
public string LinkName { get; set; }
public string Context { get; set; }
public int TheadId { get; set; }
}
}캐시 클래스:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using SpiderDemo.Entity;
using System.Threading;
namespace SpiderDemo.SearchUtil
{
public static class CacheHelper
{
public static bool EnableSearch;
/// <summary>
/// 起始URL
/// </summary>
public const string StartUrl = "http://www.sina.com.cn";
/// <summary>
/// 爬取的最大数量,性能优化一下,如果可以及时释放资源就可以一直爬了
/// </summary>
public const int MaxNum = 300;
/// <summary>
/// 最多爬出1000个结果
/// </summary>
public const int MaxResult = 1000;
/// <summary>
/// 当前爬到的数量
/// </summary>
public static int SpideNum;
/// <summary>
/// 关键字
/// </summary>
public static string KeyWord;
/// <summary>
/// 运行时间
/// </summary>
public static int RuningTime;
/// <summary>
/// 最多运行时间
/// </summary>
public static int MaxRuningtime;
/// <summary>
/// 10个线程同时去爬
/// </summary>
public static ClamThread[] ThreadList = new ClamThread[10];
/// <summary>
/// 第一次爬到的连接,连接池
/// </summary>
public static List<Link> LnkPool = new List<Link>();
/// <summary>
/// 拿到的合法连接
/// </summary>
public static List<Link> validLnk = new List<Link>();
/// <summary>
/// 拿连接的时候 不要拿同样的
/// </summary>
public static readonly object syncObj = new object();
}
}HTTP 요청 클래스:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Text;
using System.Net;
using System.IO;
using System.Threading;
namespace SpiderDemo.SearchUtil
{
public static class HttpPostUtility
{
/// <summary>
/// 暂时写成同步的吧,等后期再优化
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
public static Stream SendReq(string url)
{
try
{
if (string.IsNullOrEmpty(url)){
return null;
}
// WebProxy wp = newWebProxy("10.0.1.33:8080");
//wp.Credentials = new System.Net.NetworkCredential("*****","******", "feinno");///之前需要使用代理才能
HttpWebRequest myRequest =(HttpWebRequest)WebRequest.Create(url);
//myRequest.Proxy = wp;
HttpWebResponse myResponse =(HttpWebResponse)myRequest.GetResponse();
returnmyResponse.GetResponseStream();
}
////给一些网站发请求权限会受到限制
catch (Exception ex)
{
return null;
}
}
}
}파싱 웹 페이지 클래스, 여기에는 구성 요소가 사용됩니다. , HtmlAgilityPack.dll, 사용하기 매우 쉬움, 다운로드 링크: http://www.php.cn/
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Threading;
using System.Text;
using System.Xml;
using System.Xml.Linq;
using HtmlAgilityPack;
using System.IO;
using SpiderDemo.Entity;
namespace SpiderDemo.SearchUtil
{
public static class UrlAnalysisProcessor
{
public static void GetHrefs(Link url, Stream s, List<Link>lnkPool)
{
try
{
////没有HTML流,直接返回
if (s == null)
{
return;
}
////解析出连接往缓存里面放,等着前面页面来拿,目前每个线程最多缓存300个,多了就别存了,那边取的太慢了!
if (lnkPool.Count >=CacheHelper.MaxNum)
{
return;
}
////加载HTML,找到了HtmlAgilityPack,试试这个组件怎么样
HtmlAgilityPack.HtmlDocumentdoc = new HtmlDocument();
////指定了UTF8编码,理论上不会出现中文乱码了
doc.Load(s, Encoding.Default);
/////获得所有连接
IEnumerable<HtmlNode> nodeList=
doc.DocumentNode.SelectNodes("//a[@href]");////抓连接的方法,详细去看stackoverflow里面的:
////http://www.php.cn/
////移除脚本
foreach (var script indoc.DocumentNode.Descendants("script").ToArray())
script.Remove();
////移除样式
foreach (var style indoc.DocumentNode.Descendants("style").ToArray())
style.Remove();
string allText =doc.DocumentNode.InnerText;
int index = 0;
////如果包含关键字,为符合条件的连接
if ((index =allText.IndexOf(CacheHelper.KeyWord)) != -1)
{
////把包含关键字的上下文取出来,取40个字符吧
if (index > 20&& index < allText.Length - 20 - CacheHelper.KeyWord.Length)
{
string keyText =allText.Substring(index - 20, index) +
"<spanstyle='color:green'>" + allText.Substring(index,CacheHelper.KeyWord.Length) + "</span> " +
allText.Substring(index +CacheHelper.KeyWord.Length, 20) + "<br />";////关键字突出显示
url.Context = keyText;
}
CacheHelper.validLnk.Add(url);
//RecordUtility.AppendLog(url.LinkName + "<br />");
////爬到了一个符合条件的连接,计数器+1
CacheHelper.SpideNum++;
}
foreach (HtmlNode node innodeList)
{
if(node.Attributes["href"] == null)
{
continue;
}
else
{
Link lk = new Link()
{
Href =node.Attributes["href"].Value,
LinkName ="<a href='" + node.Attributes["href"].Value +
"'target='blank' >" + node.InnerText + " " +
node.Attributes["href"].Value + "</a>" +"<br />"
};
if(lk.Href.StartsWith("javascript"))
{
continue;
}
else if(lk.Href.StartsWith("#"))
{
continue;
}
else if(lnkPool.Contains(lk))
{
continue;
}
else
{
////添加到指定的连接池里面
lnkPool.Add(lk);
}
}
}
}
catch (Exception ex)
{
}
}
}
}검색 페이지 코드 숨김:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
using SpiderDemo.SearchUtil;
using System.Threading;
using System.IO;
using SpiderDemo.Entity;
namespace SpiderDemo
{
public partial class SearchPage : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
if (!IsPostBack)
{
InitSetting();
}
}
private void InitSetting()
{
}
private void StartWork()
{
CacheHelper.EnableSearch = true;
CacheHelper.KeyWord = txtKeyword.Text;
////第一个请求给新浪,获得返回的HTML流
Stream htmlStream = HttpPostUtility.SendReq(CacheHelper.StartUrl);
Link startLnk = new Link()
{
Href = CacheHelper.StartUrl,
LinkName = "<a href ='" + CacheHelper.StartUrl + "' > 新浪 " +CacheHelper.StartUrl + " </a>"
};
////解析出连接
UrlAnalysisProcessor.GetHrefs(startLnk, htmlStream,CacheHelper.LnkPool);
for (int i = 0; i < CacheHelper.ThreadList.Length; i++)
{
CacheHelper.ThreadList[i] = newClamThread();
CacheHelper.ThreadList[i].lnkPool = new List<Link>();
}
////把连接平分给每个线程
for (int i = 0; i < CacheHelper.LnkPool.Count; i++)
{
int tIndex = i %CacheHelper.ThreadList.Length;
CacheHelper.ThreadList[tIndex].lnkPool.Add(CacheHelper.LnkPool[i]);
}
Action<ClamThread> clamIt = new Action<ClamThread>((clt)=>
{
Stream s =HttpPostUtility.SendReq(clt.lnkPool[0].Href);
DoIt(clt, s, clt.lnkPool[0]);
});
for (int i = 0; i < CacheHelper.ThreadList.Length; i++)
{
CacheHelper.ThreadList[i]._thread = new Thread(new ThreadStart(() =>
{
clamIt(CacheHelper.ThreadList[i]);
}));
/////每个线程开始工作的时候,休眠100ms
CacheHelper.ThreadList[i]._thread.Start();
Thread.Sleep(100);
}
}
private void DoIt(ClamThreadthread, Stream htmlStream, Link url)
{
if (!CacheHelper.EnableSearch)
{
return;
}
if (CacheHelper.SpideNum > CacheHelper.MaxResult)
{
return;
}
////解析页面,URL符合条件放入缓存,并把页面的连接抓出来放入缓存
UrlAnalysisProcessor.GetHrefs(url, htmlStream, thread.lnkPool);
////如果有连接,拿第一个发请求,没有就结束吧,反正这么耗资源的东西
if (thread.lnkPool.Count > 0)
{
Link firstLnk;
firstLnk = thread.lnkPool[0];
////拿到连接之后就在缓存中移除
thread.lnkPool.Remove(firstLnk);
firstLnk.TheadId =Thread.CurrentThread.ManagedThreadId;
Stream content =HttpPostUtility.SendReq(firstLnk.Href);
DoIt(thread, content,firstLnk);
}
else
{
//没连接了,停止吧,看其他线程的表现
thread._thread.Abort();
}
}
protected void btnSearch_Click(object sender, EventArgs e)
{
this.StartWork();
}
protected void btnShow_Click(object sender, EventArgs e)
{
}
protected void btnStop_Click(object sender, EventArgs e)
{
foreach (var t in CacheHelper.ThreadList)
{
t._thread.Abort();
t._thread.DisableComObjectEagerCleanup();
}
CacheHelper.EnableSearch =false;
//CacheHelper.ValidLnk.Clear();
CacheHelper.LnkPool.Clear();
CacheHelper.validLnk.Clear();
}
}
}검색 페이지 프런트엔드 코드:
<%@ Page Language="C#"AutoEventWireup="true" CodeBehind="SearchPage.aspx.cs"Inherits="SpiderDemo.SearchPage" %>
<!DOCTYPE html PUBLIC "-//W3C//DTDXHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<htmlxmlns="http://www.w3.org/1999/xhtml">
<head runat="server">
<title></title>
</head>
<body>
<form id="form1" runat="server">
<p>
关键字:<asp:TextBoxrunat="server" ID="txtKeyword" ></asp:TextBox>
<asp:Button runat="server" ID="btnSearch"Text="搜索" onclick="btnSearch_Click"/>
<asp:Button runat="server" ID="btnStop"Text="停止" onclick="btnStop_Click" />
</p>
<p>
<iframe width="800px" height="700px"src="ShowPage.aspx">
</iframe>
</p>
</form>
</body>
</html>
ShowPage.aspx(嵌在SearchPage里面,ajax请求一个handler):
<%@ Page Language="C#"AutoEventWireup="true" CodeBehind="ShowPage.aspx.cs"Inherits="SpiderDemo.ShowPage" %>
<!DOCTYPE html PUBLIC "-//W3C//DTDXHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head runat="server">
<title></title>
<script src="js/jquery-1.6.js"></script>
</head>
<body>
<form id="form1" runat="server">
<p>
</p>
<p id="pRet">
</p>
<script type="text/javascript">
$(document).ready(
function () {
var timer = setInterval(
function () {
$.ajax({
type: "POST",
url:"http://localhost:26820/StateServicePage.ashx",
data: "op=info",
success: function (msg) {
$("#pRet").html(msg);
}
});
}, 2000);
});
</script>
</form>
</body>
</html>StateServicePage.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Text;
using SpiderDemo.SearchUtil;
using SpiderDemo.Entity;
namespace SpiderDemo
{
/// <summary>
/// StateServicePage 的摘要说明
/// </summary>
public class StateServicePage : IHttpHandler
{
public void ProcessRequest(HttpContext context)
{
context.Response.ContentType = "text/plain";
if (context.Request["op"] != null &&context.Request["op"] == "info")
{
context.Response.Write(ShowState());
}
}
public string ShowState()
{
StringBuilder sbRet = new StringBuilder(100);
string ret = GetValidLnkStr();
int count = 0;
for (int i = 0; i <CacheHelper.ThreadList.Length; i++)
{
if(CacheHelper.ThreadList[i] != null && CacheHelper.ThreadList[i].lnkPool!= null)
count += CacheHelper.ThreadList[i].lnkPool.Count;
}
sbRet.AppendLine("服务是否运行 : " + CacheHelper.EnableSearch + "<br />");
sbRet.AppendLine("连接池总数: " + count + "<br />");
sbRet.AppendLine("搜索结果:<br /> " + ret);
return sbRet.ToString();
}
private string GetValidLnkStr()
{
StringBuilder sb = new StringBuilder(120);
Link[] cloneLnk = new Link[CacheHelper.validLnk.Count];
CacheHelper.validLnk.CopyTo(cloneLnk, 0);
for (int i = 0; i < cloneLnk.Length; i++)
{
sb.AppendLine("<br/>" + cloneLnk[i].LinkName + "<br />" +cloneLnk[i].Context);
}
return sb.ToString();
}
public bool IsReusable
{
get
{
return false;
}
}
}
} 위 내용은 C# 웹 크롤러 및 검색 엔진 연구의 코드 내용입니다. 더 많은 관련 내용은 PHP 중국어 홈페이지(www.php.cn)를 참고해주세요. )!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7647
7647
 15
1392
52
91
11
73
19
36
110
15
1392
52
91
11
73
19
36
110

 C#을 사용한 Active Directory
Sep 03, 2024 pm 03:33 PM
C#을 사용한 Active Directory
Sep 03, 2024 pm 03:33 PM
C#을 사용한 Active Directory 가이드. 여기에서는 소개와 구문 및 예제와 함께 C#에서 Active Directory가 작동하는 방식에 대해 설명합니다.

 C#의 난수 생성기
Sep 03, 2024 pm 03:34 PM
C#의 난수 생성기
Sep 03, 2024 pm 03:34 PM
C#의 난수 생성기 가이드입니다. 여기서는 난수 생성기의 작동 방식, 의사 난수 및 보안 숫자의 개념에 대해 설명합니다.
 C# 데이터 그리드 보기
Sep 03, 2024 pm 03:32 PM
C# 데이터 그리드 보기
Sep 03, 2024 pm 03:32 PM
C# 데이터 그리드 뷰 가이드. 여기서는 SQL 데이터베이스 또는 Excel 파일에서 데이터 그리드 보기를 로드하고 내보내는 방법에 대한 예를 설명합니다.



 멀티 스레딩과 비동기 C#의 차이
Apr 03, 2025 pm 02:57 PM
멀티 스레딩과 비동기 C#의 차이
Apr 03, 2025 pm 02:57 PM
멀티 스레딩과 비동기식의 차이점은 멀티 스레딩이 동시에 여러 스레드를 실행하는 반면, 현재 스레드를 차단하지 않고 비동기식으로 작업을 수행한다는 것입니다. 멀티 스레딩은 컴퓨팅 집약적 인 작업에 사용되며 비동기식은 사용자 상호 작용에 사용됩니다. 멀티 스레딩의 장점은 컴퓨팅 성능을 향상시키는 것이지만 비동기의 장점은 UI 스레드를 차단하지 않는 것입니다. 멀티 스레딩 또는 비동기식을 선택하는 것은 작업의 특성에 따라 다릅니다. 계산 집약적 작업은 멀티 스레딩을 사용하고 외부 리소스와 상호 작용하고 UI 응답 성을 비동기식으로 유지 해야하는 작업을 사용합니다.
