

MySQL 파티션의 범위 파티션에 대한 자세한 소개

인터넷의 발달로 인해 모든 면에서 데이터가 점점 더 많아지고 있으며, 이는 지난 2년간 빅데이터에 대한 요구가 증가한 것을 보면 알 수 있습니다.
우리가 하고 있는 프로젝트는 큰 규모는 아니지만, 사업 규모로 인해 데이터가 꽤 많습니다.
데이터가 너무 많으면 성능 문제가 발생하기 쉽습니다. 이 문제를 해결하기 위해 우리는 일반적으로 클러스터링, 샤딩 등을 쉽게 생각합니다.
그러나 어느 시점에서는 클러스터나 샤딩을 사용할 필요가 없고 데이터 파티셔닝도 적절하게 사용할 수 있습니다.
파티션이란 무엇인가요?
MySQL이 파티션 기능을 활성화하지 않을 경우 데이터베이스 내 단일 테이블의 내용이 단일 파일 형태로 파일 시스템에 저장된다. 파티셔닝 기능이 활성화되면 MySQL은 단일 테이블의 내용을 여러 파일로 나누어 사용자가 지정한 규칙에 따라 파일 시스템에 저장합니다. 파티셔닝은 수평 파티셔닝과 수직 파티셔닝으로 구분됩니다. 수평 파티셔닝은 테이블 데이터를 행별로 여러 데이터 파일로 나누고, 수직 파티셔닝은 테이블 데이터를 열별로 여러 데이터 파일로 나눕니다. 샤딩은 완전성, 재구성성, 분리성의 원칙을 따라야 합니다. 완전성은 모든 데이터가 조각에 매핑되어야 함을 의미합니다. 재구성 가능성이란 샤딩된 모든 데이터를 글로벌 데이터로 재구성할 수 있어야 함을 의미합니다. 분리성은 서로 다른 샤드에 데이터가 중복되지 않음을 의미합니다(의도적으로 중복되도록 만들지 않는 한).
아마도 우리가 사용한 테이블은 범위 파티셔닝을 사용하고 있지만, 이 테이블을 사용하기 때문에 간단한 학습에 시간이 걸렸습니다.
제가 아는 한, 파티셔닝을 사용하려면 테이블 구조를 생성할 때 파티션을 생성하는 문을 사용해야 하며 나중에 변경할 수 없습니다.
예를 들어, id, name, age라는 세 가지 필드가 있는 간단한 emp 테이블을 만든 다음 id를 기준으로 분할합니다. 올바른 테이블 생성문은 기본적으로 다음과 같습니다.
CREATE TABLE emp( id INT NOT NULL, NAME VARCHAR(20), age INT) PARTITION BY RANGE(ID)( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION pmax VALUES LESS THAN maxvalue );
여기서 전체 테이블의 데이터를 세 개의 영역으로 나누도록 설정했습니다. id가 6보다 작은 영역이 하나의 영역이고 영역 이름은 p0입니다. ; 6에서 11 사이의 ID를 가진 영역은 하나의 영역, 영역 이름 p1에 속하고, 그 다음에는 ID가 11보다 큰 모든 영역, 영역 이름 pmax에 속합니다.
기본적으로 다음과 같이 구문을 구성합니다.
create table tablename( 字段名 数据类型...) partition by range(分区依赖的字段名)( partition 分取名 values less than (分区条件的值),...)
여기서 주목해야 할 점은 예제의 마지막 줄에서 maxvalue보다 작은 pmax 값을 분할한다는 것입니다. 파티션 이름을 나타내며 임의로 얻을 수 있습니다. 나머지는 변경할 수 없으며, maxvalue는 상위 파티션 조건의 최대값을 나타냅니다.
이렇게 하면 모든 데이터가 데이터베이스에 정상적으로 저장될 수 있습니다. 그렇지 않으면 해당 문장이 없으면 ID가 11보다 크거나 같은 데이터가 데이터베이스에 저장되지 않고 오류가 보고됩니다.
테이블 구조가 생성된 후 파티셔닝이 성공했는지 테스트하기 위해 테이블에 일부 데이터를 삽입했습니다.
INSERT INTO emp VALUES(1,'test1',22);INSERT INTO emp VALUES(2,'test2',25);INSERT INTO emp VALUES(3,'test3',27); INSERT INTO emp VALUES(4,'test4',20);INSERT INTO emp VALUES(5,'test5',22);INSERT INTO emp VALUES(6,'test6',25); INSERT INTO emp VALUES(7,'test7',27);INSERT INTO emp VALUES(8,'test8',20);INSERT INTO emp VALUES(9,'test9',22); INSERT INTO emp VALUES(10,'test10',25);INSERT INTO emp VALUES(11,'test11',27);INSERT INTO emp VALUES(12,'test12',20); INSERT INTO emp VALUES(13,'test13',22);INSERT INTO emp VALUES(14,'test14',25);INSERT INTO emp VALUES(15,'test15',27); INSERT INTO emp VALUES(16,'test16',20);INSERT INTO emp VALUES(17,'test17',30);INSERT INTO emp VALUES(18,'test18',40); INSERT INTO emp VALUES(19,'test19',20);
데이터 삽입이 완료된 후입니다. , 해당 파티션에 해당 id에 해당하는 데이터가 저장되어 있는지 확인이 필요하며,
SELECT partition_name,partition_expression,partition_description,table_rows FROM information_schema.PARTITIONS WHERE table_schema = SCHEMA() AND table_name='emp'
쿼리 결과는 그림과 같습니다. : 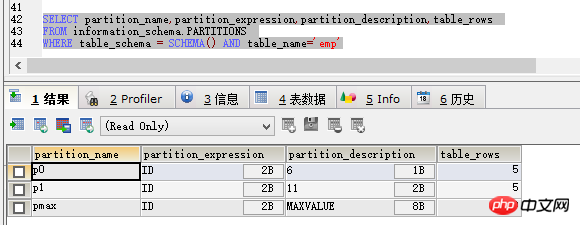
partition_name은 파티션 이름, partition_expression은 파티션 종속성 필드, partition_description은 파티션의 조건으로 이해될 수 있으며 table_rows는 현재 데이터의 양을 나타냅니다. 파티션.
위의 데이터를 보면 파티셔닝이 성공한 것을 알 수 있습니다. 그러나 위의 파티셔닝을 통해 삽입할 수 없는 문제는 피할 수 있지만 새로운 문제가 발생했습니다.
즉, 마지막 pmax 영역의 데이터가 매우 클 수 있으며, 결과적으로 데이터가 고르지 않고 불균형하여 마지막 영역의 데이터를 쿼리할 때 성능 문제가 발생할 수 있습니다. 따라서 대략 세 가지 해결 방법이 있습니다.
첫째, 여기서 id와 같은 파티션 필드 데이터를 제어할 수 있고, 그것이 언제, 어떤 값이 될지 명확하게 알 수 있다면 그렇게 할 수 없습니다. 처음에는 이 pmax를 사용하되 정기적으로 파티션을 추가하십시오. 예를 들어 여기에 p0과 p1이 존재한다면 ID가 11에 도달하려고 할 때 p2, p3 또는 그 이상을 추가할 수 있습니다. 파티션을 추가하는 문의 예는 다음과 같습니다.
ALTER TABLE emp ADD PARTITION(PARTITION p2 VALUES LESS THAN (16))
구문은 다음과 같습니다.
alter table tablename add partition(partition 分区名 values lessthan (分区条件))
위 방법은 데이터 불균형 문제를 해결할 수 있지만 숨겨진 위험도 있습니다. 즉, 후속 파티션을 늘리기 위해 잊어버리거나 파티션이 의존하는 필드 값이 기대치를 초과하는 경우 데이터가 데이터베이스에 저장되지 않는 문제가 발생할 수 있습니다. 이런 식으로 해결하는 방법은 두 가지가 있습니다.
첫째, mysql의 트랜잭션 메커니즘과 저장 프로시저를 사용하여 mysql 예약 작업을 만든 다음 데이터베이스 시스템이 특정 시간에 파티션을 추가하도록 할 수 있습니다. 이렇게 하면 첫 번째 방법에서 언급한 문제는 기본적으로 발생하지 않지만, 이 방법은 MySQL 트랜잭션 및 저장 프로시저에 대한 어느 정도의 이해가 필요하고 조작이 어렵습니다.
이 방법을 알고 있지만 아직 구현하지 않았습니다. 나중에 트랜잭션 및 저장 프로시저에 대해 자세히 알아보고 관련 예제를 제공하겠습니다.
위의 예약된 작업 방법 외에도 파티션을 분할하는 또 다른 방법이 있습니다. 즉, 이전에 pmax 파티션이 있던 테이블 구조를 계속 사용하고, 그런 다음 분할 파티션 문을 사용하여 pmax를 분할하는 것입니다. . 예시는 다음과 같습니다.
ALTER TABLE emp REORGANIZE PARTITION pmax INTO( PARTITION p2 VALUES LESS THAN (16), PARTITION pmax VALUES LESS THAN maxvalue )
然后我们再用查询分区情况的语句查询,便可以看到结果变成这样: 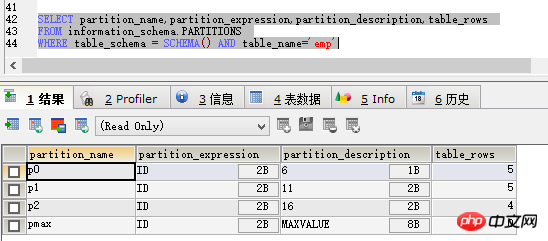
很显然,多出来了一个p2分区,拆分成功的同事不影响其他的功能。
那么这里分区拆分的语法整理如下:
alter table tablename reorganize partition 要拆分的分区名 into( partition 拆分后的分区名1 values less than (条件), partition 拆分后的分区名2 values lessthan (条件),...)
好了,到这里基本上算是完成了,但是我们知道数据库一般的操作都是增删改查,我们这里已经有了增改查,却自然也不能少了删。
按理说正常的生产环境的数据库应该是不能随意删除数据的,但是并不代表就不能删,反而有的时候还必须要删。
就比如我们项目中那个库,由于数据量太大,即便是分区了也依旧会在大量数据的情况下变慢。而与此同时,我们是按时间分区的,实际使用过程中只需要用到几天的数据,那么实际上很早以前的数据是可以删除不要的,或者说备份以后删除这个表的,这样就需要用到删除语句。
当然了,删除可以用delete,但是这样的话分区信息还在库中,实际上也是没必要要的,完全可以直接删除分区,因为删除分区的时候也同时会删除这个区内的所有数据。
示例之前我们先查一下之前插入的所有数据,如图: 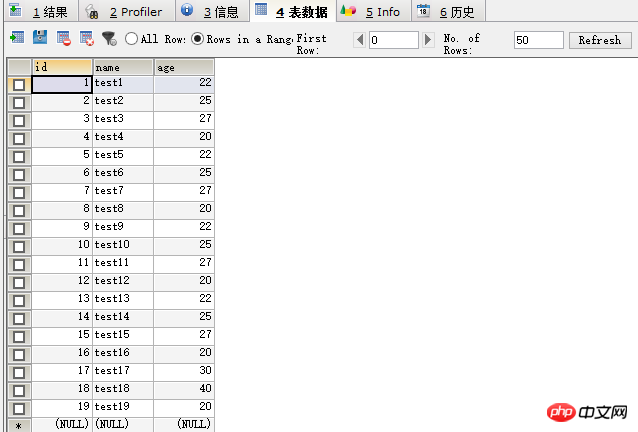
这里示例删除p0分区代码如下:
ALTER TABLE emp DROP PARTITION p0
然后先用查询分区的代码看一下,如图 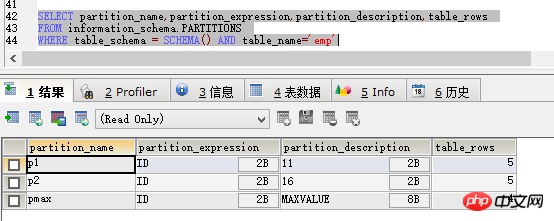
可以看到p0区不见了,在select * 一下,如图: 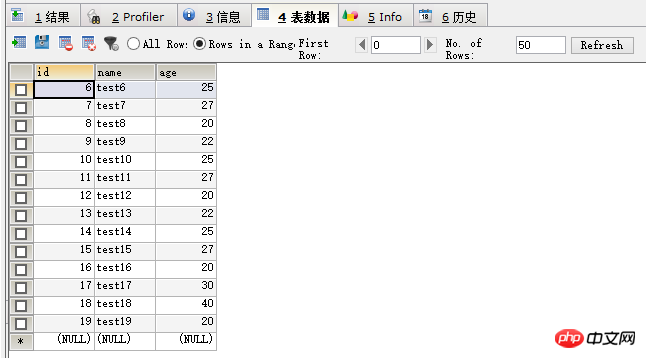
可以看到id小于6的数据已经没有了,数据删除成功。
以上就是mysql分区之range分区的详细介绍的内容,更多相关内容请关注PHP中文网(www.php.cn)!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7638
7638
 15
1391
52
90
11
71
19
32
150
15
1391
52
90
11
71
19
32
150

 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache는 데이터베이스에 연결하여 다음 단계가 필요합니다. 데이터베이스 드라이버 설치. 연결 풀을 만들려면 Web.xml 파일을 구성하십시오. JDBC 데이터 소스를 작성하고 연결 설정을 지정하십시오. JDBC API를 사용하여 Connections, 명세서 작성, 매개 변수 바인딩, 쿼리 또는 업데이트 실행 및 처리를 포함하여 Java 코드의 데이터베이스에 액세스하십시오.
 Redis Exporter 서비스로 Redis 액 적을 모니터링하십시오
Apr 10, 2025 pm 01:36 PM
Redis Exporter 서비스로 Redis 액 적을 모니터링하십시오
Apr 10, 2025 pm 01:36 PM
Redis 데이터베이스의 효과적인 모니터링은 최적의 성능을 유지하고 잠재적 인 병목 현상을 식별하며 전반적인 시스템 신뢰성을 보장하는 데 중요합니다. Redis Exporter Service는 Prometheus를 사용하여 Redis 데이터베이스를 모니터링하도록 설계된 강력한 유틸리티입니다. 이 튜토리얼은 Redis Exporter Service의 전체 설정 및 구성을 안내하여 모니터링 솔루션을 원활하게 구축 할 수 있도록합니다. 이 자습서를 연구하면 완전히 작동하는 모니터링 설정을 달성 할 수 있습니다.
 SQL 데이터베이스 오류를 보는 방법
Apr 10, 2025 pm 12:09 PM
SQL 데이터베이스 오류를 보는 방법
Apr 10, 2025 pm 12:09 PM
SQL 데이터베이스 오류를 보는 방법은 다음과 같습니다. 1. 오류 메시지보기 직접; 2. 표시 오류 및 경고 명령을 사용하십시오. 3. 오류 로그에 액세스; 4. 오류 코드를 사용하여 오류의 원인을 찾으십시오. 5. 데이터베이스 연결 및 쿼리 구문을 확인하십시오. 6. 디버깅 도구를 사용하십시오.
