1. 소개
이전 글에서는 Python 소스 코드를 통해 분석하는 방법을 소개했습니다. 크롤링 블로그, Wikipedia InfoBox 및 사진, 기사 링크는 다음과 같습니다:
[파이썬 학습] 위키피디아 프로그래밍 언어 메시지 상자 간단한 크롤링
[파이썬 학습] 간단한 웹 크롤러 블로그 글 크롤링 및 아이디어 소개
[파이썬 학습] 그림 홈페이지 갤러리 내 이미지 단순 크롤링
핵심 코드는 다음과 같습니다.
# coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'<a href=.*?>(.*?)</a>'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个url로그인 후 복사
출력 결과는 다음과 같습니다.
>>>
CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
登录
>>>
로그인 후 복사
이미지 다운로드를 위한 핵심 코드는 다음과 같습니다.
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename)로그인 후 복사
그러나 웹 사이트 콘텐츠를 크롤링하기 위해 HTML을 분석하는 위의 방법에는 다음과 같은 많은 단점이 있습니다.
1. 정규 표현식은 HTML 소스 코드에 의해 제한됩니다. , 보다 추상적인 구조에 의존하기보다는 웹 페이지 구조의 작은 변경으로 인해 프로그램이 중단될 수 있습니다.
2. 프로그램은 실제 HTML 소스 코드를 기반으로 콘텐츠를 분석해야 하며 &와 같은 문자 엔터티와 같은 HTML 기능이 발생할 수 있으며 , 아이콘 하이퍼링크, 아래 첨자 등 다양한 콘텐츠.
3. 정규식은 완전히 읽을 수 없으며 더 복잡한 HTML 코드와 쿼리 표현식은 지저분해집니다.
"Python Basics Tutorial(2nd Edition)"에서는 두 가지 솔루션을 채택합니다. 첫 번째는 Tidy(Python 라이브러리) 프로그램과 XHTML 구문 분석을 사용하는 것이고, 두 번째는 BeautifulSoup 라이브러리를 사용합니다.
2. 설치 및 소개 Beautiful Soup 라이브러리
Beautiful Soup은 Python으로 작성된 HTML/XML 파서입니다. 불규칙한 마크업을 잘 처리하고 구문 분석 트리를 생성합니다. 구문 분석 트리 탐색, 검색 및 수정을 위해 간단하고 일반적으로 사용되는 작업을 제공합니다. 프로그래밍 시간을 크게 절약할 수 있습니다.
책에 쓰여 있듯이 "당신은 그 나쁜 웹 페이지를 쓴 것이 아니라, 단지 거기에서 데이터를 얻으려고 했을 뿐입니다. 이제는 신경 쓰지 마세요." HTML이 어떻게 생겼는지, 파서는 이를 달성하는 데 도움이 됩니다."
다운로드 주소 :
http://www .php.cn/
setup.py 설치
 구체적인 사용법은 중국어 참고를 권장합니다: http://www.php.cn/
구체적인 사용법은 중국어 참고를 권장합니다: http://www.php.cn/
그 중 BeautifulSoup의 사용법은 "이상한 나라의 앨리스"의 공식 예를 사용하여 간략하게 설명합니다.
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#获取BeautifulSoup对象并按标准缩进格式输出
soup = BeautifulSoup(html_doc)
print(soup.prettify())
로그인 후 복사
출력 내용
표준 들여쓰기 형식에 따른 출력 구조
는 다음과 같습니다. <html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>로그인 후 복사
'''获取title值'''
print soup.title
# <title>The Dormouse's story</title>
print soup.title.name
# title
print unicode(soup.title.string)
# The Dormouse's story
'''获取<p>值'''
print soup.p
# <p class="title"><b>The Dormouse's story</b></p>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
'''从文档中找到<a>的所有标签链接'''
print soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for link in soup.find_all('a'):
print(link.get('href'))
# http://www.php.cn/
# http://www.php.cn/
# http://www.php.cn/
print soup.find(id='link3')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>로그인 후 복사
기사의 모든 텍스트 내용을 얻으려면 코드는 다음과 같습니다. '''从文档中获取所有文字内容'''
print soup.get_text()
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
로그인 후 복사
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。
其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
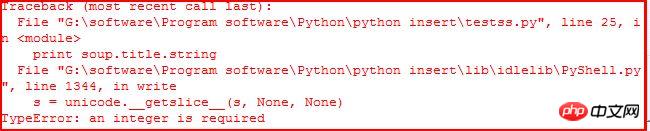
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="start"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html)
tag = soup.p
print tag
# <p class="title" id="start"><b>The Dormouse's story</b></p>
print type(tag)
# <class 'bs4.element.Tag'>
print tag.name
# p 标签名字
print tag['class']
# [u'title']
print tag.attrs
# {u'class': [u'title'], u'id': u'start'}로그인 후 복사
使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。
print unicode(tag.string)
# The Dormouse's story
print type(tag.string)
# <class 'bs4.element.NavigableString'>
tag.string.replace_with("No longer bold")
print tag
# <p class="title" id="start"><b>No longer bold</b></p>로그인 후 복사
这是获取“The Dormouse's story
”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。
NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
print type(comment)
# <class 'bs4.element.Comment'>
print unicode(comment)
# Hey, buddy. Want to buy a used parser?
로그인 후 복사
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
soup.head# <head><title>The Dormouse's story</title></head>soup.title# <title>The Dormouse's story</title>soup.body.b# <b>The Dormouse's story</b>
로그인 후 복사
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取标签中第一个标签。
如果想得到所有的标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
soup.find_all('a')# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
로그인 후 복사
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
로그인 후 복사
通过tag的 .children 生成器,可以对tag的子节点进行循环:
for child in title_tag.children:
print(child)
# The Dormouse's story로그인 후 복사
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's story로그인 후 복사
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,标签是标签的父节点,换句话就是增加一层标签。<br/> <span style="color:#ff0000">注意:文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。</span><br/></span></strong></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">title_tag = soup.titletitle_tag# <title>The Dormouse's story</title>title_tag.parent# <head><title>The Dormouse's story</title></head>title_tag.string.parent# <title>The Dormouse's story</title></pre><div class="contentsignin">로그인 후 복사</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">兄弟节点</span>:因为<b>标签和<c>标签是同一层:他们是同一个元素的子节点,所以<b>和<c>可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。</span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>")print(sibling_soup.prettify())# <html># <body># <a># <b># text1# </b># <c># text2# </c># </a># </body># </html></pre><div class="contentsignin">로그인 후 복사</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。<b>标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为<b>标签在同级节点中是第一个。同理<c>标签有.previous_sibling 属性,却没有.next_sibling 属性:</span></span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup.b.next_sibling# <c>text2</c>sibling_soup.c.previous_sibling# <b>text1</b></pre><div class="contentsignin">로그인 후 복사</div></div><p><strong><span style="font-size:18px"> 介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。</span><br><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px"> </span><span style="font-size:18px; font-family:Arial; line-height:26px"><span style="color:#ff0000"> (By:Eastmount 2015-3-25 下午6点</span></span><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px">
</span>http://www.php.cn/<span style="font-family:Arial; color:#ff0000"><span style="font-size:18px; line-height:26px">)</span></span></strong><br></p>
<p></p>
<p><br></p>
<p class="pmark"><br></p>
<p>
</p><p>위 내용은 Python BeautifulSoup 라이브러리 설치 및 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!</p>
</div>
</div>
<div class="wzconShengming_sp">
<div class="bzsmdiv_sp">본 웹사이트의 성명</div>
<div>본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.</div>
</div>
</div>
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="2507867629"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="AI_ToolDetails_main4sR">
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="3653428331"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<!-- <div class="phpgenera_Details_mainR4">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hotarticle2.png" alt="" />
<h2>인기 기사</h2>
</div>
<div class="phpgenera_Details_mainR4_bottom">
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796785841.html" title="어 ass 신 크리드 그림자 : 조개 수수께끼 솔루션" class="phpgenera_Details_mainR4_bottom_title">어 ass 신 크리드 그림자 : 조개 수수께끼 솔루션</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>4 몇 주 전</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796789525.html" title="Windows 11 KB5054979의 새로운 기능 및 업데이트 문제를 해결하는 방법" class="phpgenera_Details_mainR4_bottom_title">Windows 11 KB5054979의 새로운 기능 및 업데이트 문제를 해결하는 방법</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>3 몇 주 전</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796785857.html" title="Atomfall에서 크레인 제어 키 카드를 찾을 수 있습니다" class="phpgenera_Details_mainR4_bottom_title">Atomfall에서 크레인 제어 키 카드를 찾을 수 있습니다</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>4 몇 주 전</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796784440.html" title="<s> : 데드 레일 - 모든 도전을 완료하는 방법" class="phpgenera_Details_mainR4_bottom_title"><s> : 데드 레일 - 모든 도전을 완료하는 방법</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>1 몇 달 전</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796784000.html" title="Atomfall Guide : 항목 위치, 퀘스트 가이드 및 팁" class="phpgenera_Details_mainR4_bottom_title">Atomfall Guide : 항목 위치, 퀘스트 가이드 및 팁</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>1 몇 달 전</span>
<span>By DDD</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/ko/article.html">더보기</a>
</div>
</div>
</div> -->
<div class="phpgenera_Details_mainR3">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hottools2.png" alt="" />
<h2>핫 AI 도구</h2>
</div>
<div class="phpgenera_Details_mainR3_bottom">
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/ai/undresserai-undress" title="Undresser.AI Undress" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411540686492.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Undresser.AI Undress" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/ai/undresserai-undress" title="Undresser.AI Undress" class="phpmain_tab2_mids_title">
<h3>Undresser.AI Undress</h3>
</a>
<p>사실적인 누드 사진을 만들기 위한 AI 기반 앱</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/ai/ai-clothes-remover" title="AI Clothes Remover" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411552797167.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="AI Clothes Remover" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/ai/ai-clothes-remover" title="AI Clothes Remover" class="phpmain_tab2_mids_title">
<h3>AI Clothes Remover</h3>
</a>
<p>사진에서 옷을 제거하는 온라인 AI 도구입니다.</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/ai/undress-ai-tool" title="Undress AI Tool" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173410641626608.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Undress AI Tool" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/ai/undress-ai-tool" title="Undress AI Tool" class="phpmain_tab2_mids_title">
<h3>Undress AI Tool</h3>
</a>
<p>무료로 이미지를 벗다</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/ai/clothoffio" title="Clothoff.io" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411529149311.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Clothoff.io" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/ai/clothoffio" title="Clothoff.io" class="phpmain_tab2_mids_title">
<h3>Clothoff.io</h3>
</a>
<p>AI 옷 제거제</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/ai/video-swap" title="Video Face Swap" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173414504068133.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Video Face Swap" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/ai/video-swap" title="Video Face Swap" class="phpmain_tab2_mids_title">
<h3>Video Face Swap</h3>
</a>
<p>완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!</p>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/ko/ai">더보기</a>
</div>
</div>
</div>
<script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script>
<div class="phpgenera_Details_mainR4">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hotarticle2.png" alt="" />
<h2>인기 기사</h2>
</div>
<div class="phpgenera_Details_mainR4_bottom">
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796785841.html" title="어 ass 신 크리드 그림자 : 조개 수수께끼 솔루션" class="phpgenera_Details_mainR4_bottom_title">어 ass 신 크리드 그림자 : 조개 수수께끼 솔루션</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>4 몇 주 전</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796789525.html" title="Windows 11 KB5054979의 새로운 기능 및 업데이트 문제를 해결하는 방법" class="phpgenera_Details_mainR4_bottom_title">Windows 11 KB5054979의 새로운 기능 및 업데이트 문제를 해결하는 방법</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>3 몇 주 전</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796785857.html" title="Atomfall에서 크레인 제어 키 카드를 찾을 수 있습니다" class="phpgenera_Details_mainR4_bottom_title">Atomfall에서 크레인 제어 키 카드를 찾을 수 있습니다</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>4 몇 주 전</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796784440.html" title="<s> : 데드 레일 - 모든 도전을 완료하는 방법" class="phpgenera_Details_mainR4_bottom_title"><s> : 데드 레일 - 모든 도전을 완료하는 방법</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>1 몇 달 전</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/1796784000.html" title="Atomfall Guide : 항목 위치, 퀘스트 가이드 및 팁" class="phpgenera_Details_mainR4_bottom_title">Atomfall Guide : 항목 위치, 퀘스트 가이드 및 팁</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>1 몇 달 전</span>
<span>By DDD</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/ko/article.html">더보기</a>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hottools2.png" alt="" />
<h2>뜨거운 도구</h2>
</div>
<div class="phpgenera_Details_mainR3_bottom">
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/toolset/development-tools/92" title="메모장++7.3.1" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab96f0f39f7357.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="메모장++7.3.1" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/toolset/development-tools/92" title="메모장++7.3.1" class="phpmain_tab2_mids_title">
<h3>메모장++7.3.1</h3>
</a>
<p>사용하기 쉬운 무료 코드 편집기</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/toolset/development-tools/93" title="SublimeText3 중국어 버전" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab97a3baad9677.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="SublimeText3 중국어 버전" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/toolset/development-tools/93" title="SublimeText3 중국어 버전" class="phpmain_tab2_mids_title">
<h3>SublimeText3 중국어 버전</h3>
</a>
<p>중국어 버전, 사용하기 매우 쉽습니다.</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/toolset/development-tools/121" title="스튜디오 13.0.1 보내기" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab97ecd1ab2670.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="스튜디오 13.0.1 보내기" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/toolset/development-tools/121" title="스튜디오 13.0.1 보내기" class="phpmain_tab2_mids_title">
<h3>스튜디오 13.0.1 보내기</h3>
</a>
<p>강력한 PHP 통합 개발 환경</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/toolset/development-tools/469" title="드림위버 CS6" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58d0e0fc74683535.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="드림위버 CS6" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/toolset/development-tools/469" title="드림위버 CS6" class="phpmain_tab2_mids_title">
<h3>드림위버 CS6</h3>
</a>
<p>시각적 웹 개발 도구</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/ko/toolset/development-tools/500" title="SublimeText3 Mac 버전" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58d34035e2757995.png?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="SublimeText3 Mac 버전" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/ko/toolset/development-tools/500" title="SublimeText3 Mac 버전" class="phpmain_tab2_mids_title">
<h3>SublimeText3 Mac 버전</h3>
</a>
<p>신 수준의 코드 편집 소프트웨어(SublimeText3)</p>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/ko/ai">더보기</a>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hotarticle2.png" alt="" />
<h2>뜨거운 주제</h2>
</div>
<div class="phpgenera_Details_mainR4_bottom">
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/gmailyxdlrkzn" title="Gmail 이메일의 로그인 입구는 어디에 있나요?" class="phpgenera_Details_mainR4_bottom_title">Gmail 이메일의 로그인 입구는 어디에 있나요?</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>7698</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>15</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/java-tutorial" title="자바 튜토리얼" class="phpgenera_Details_mainR4_bottom_title">자바 튜토리얼</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>1640</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>14</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/cakephp-tutor" title="Cakephp 튜토리얼" class="phpgenera_Details_mainR4_bottom_title">Cakephp 튜토리얼</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>1393</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>52</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/laravel-tutori" title="라라벨 튜토리얼" class="phpgenera_Details_mainR4_bottom_title">라라벨 튜토리얼</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>1287</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>25</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/ko/faq/php-tutorial" title="PHP 튜토리얼" class="phpgenera_Details_mainR4_bottom_title">PHP 튜토리얼</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>1229</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>29</span>
</div>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/ko/faq/zt">더보기</a>
</div>
</div>
</div>
</div>
</div>
<div class="Article_Details_main2">
<div class="phpgenera_Details_mainL4">
<div class="phpmain1_2_top">
<a href="javascript:void(0);" class="phpmain1_2_top_title">Related knowledge<img
src="/static/imghw/index2_title2.png" alt="" /></a>
</div>
<div class="phpgenera_Details_mainL4_info">
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/ko/faq/1796797869.html" title="PHP와 Python : 다른 패러다임이 설명되었습니다" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174490716137257.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="PHP와 Python : 다른 패러다임이 설명되었습니다" />
</a>
<a href="https://www.php.cn/ko/faq/1796797869.html" title="PHP와 Python : 다른 패러다임이 설명되었습니다" class="phphistorical_Version2_mids_title">PHP와 Python : 다른 패러다임이 설명되었습니다</a>
<span class="Articlelist_txts_time">Apr 18, 2025 am 12:26 AM</span>
<p class="Articlelist_txts_p">PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/ko/faq/1796797864.html" title="PHP와 Python 중에서 선택 : 가이드" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174490706146904.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="PHP와 Python 중에서 선택 : 가이드" />
</a>
<a href="https://www.php.cn/ko/faq/1796797864.html" title="PHP와 Python 중에서 선택 : 가이드" class="phphistorical_Version2_mids_title">PHP와 Python 중에서 선택 : 가이드</a>
<span class="Articlelist_txts_time">Apr 18, 2025 am 12:24 AM</span>
<p class="Articlelist_txts_p">PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/ko/faq/1796796853.html" title="Python vs. JavaScript : 학습 곡선 및 사용 편의성" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174473354083140.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Python vs. JavaScript : 학습 곡선 및 사용 편의성" />
</a>
<a href="https://www.php.cn/ko/faq/1796796853.html" title="Python vs. JavaScript : 학습 곡선 및 사용 편의성" class="phphistorical_Version2_mids_title">Python vs. JavaScript : 학습 곡선 및 사용 편의성</a>
<span class="Articlelist_txts_time">Apr 16, 2025 am 12:12 AM</span>
<p class="Articlelist_txts_p">Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/ko/faq/1796796735.html" title="Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202412/27/2024122713580165301.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다" />
</a>
<a href="https://www.php.cn/ko/faq/1796796735.html" title="Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다" class="phphistorical_Version2_mids_title">Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다</a>
<span class="Articlelist_txts_time">Apr 15, 2025 pm 08:18 PM</span>
<p class="Articlelist_txts_p">VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/ko/faq/1796797866.html" title="PHP와 Python : 그들의 역사에 깊은 다이빙" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174490710066424.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="PHP와 Python : 그들의 역사에 깊은 다이빙" />
</a>
<a href="https://www.php.cn/ko/faq/1796797866.html" title="PHP와 Python : 그들의 역사에 깊은 다이빙" class="phphistorical_Version2_mids_title">PHP와 Python : 그들의 역사에 깊은 다이빙</a>
<span class="Articlelist_txts_time">Apr 18, 2025 am 12:25 AM</span>
<p class="Articlelist_txts_p">PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/ko/faq/1796796694.html" title="터미널 VSCODE에서 프로그램을 실행하는 방법" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202501/02/2025010222204446248.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="터미널 VSCODE에서 프로그램을 실행하는 방법" />
</a>
<a href="https://www.php.cn/ko/faq/1796796694.html" title="터미널 VSCODE에서 프로그램을 실행하는 방법" class="phphistorical_Version2_mids_title">터미널 VSCODE에서 프로그램을 실행하는 방법</a>
<span class="Articlelist_txts_time">Apr 15, 2025 pm 06:42 PM</span>
<p class="Articlelist_txts_p">vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/ko/faq/1796796708.html" title="Windows 8에서 코드를 실행할 수 있습니다" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202412/31/2024123119425980275.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Windows 8에서 코드를 실행할 수 있습니다" />
</a>
<a href="https://www.php.cn/ko/faq/1796796708.html" title="Windows 8에서 코드를 실행할 수 있습니다" class="phphistorical_Version2_mids_title">Windows 8에서 코드를 실행할 수 있습니다</a>
<span class="Articlelist_txts_time">Apr 15, 2025 pm 07:24 PM</span>
<p class="Articlelist_txts_p">VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/ko/faq/1796796719.html" title="VScode 확장자가 악의적입니까?" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202412/27/2024122714102618732.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="VScode 확장자가 악의적입니까?" />
</a>
<a href="https://www.php.cn/ko/faq/1796796719.html" title="VScode 확장자가 악의적입니까?" class="phphistorical_Version2_mids_title">VScode 확장자가 악의적입니까?</a>
<span class="Articlelist_txts_time">Apr 15, 2025 pm 07:57 PM</span>
<p class="Articlelist_txts_p">VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.</p>
</div>
</div>
<a href="https://www.php.cn/ko/be/" class="phpgenera_Details_mainL4_botton">
<span>See all articles</span>
<img src="/static/imghw/down_right.png" alt="" />
</a>
</div>
</div>
</div>
</main>
<footer>
<div class="footer">
<div class="footertop">
<img src="/static/imghw/logo.png" alt="">
<p>공공복지 온라인 PHP 교육,PHP 학습자의 빠른 성장을 도와주세요!</p>
</div>
<div class="footermid">
<a href="https://www.php.cn/ko/about/us.html">회사 소개</a>
<a href="https://www.php.cn/ko/about/disclaimer.html">부인 성명</a>
<a href="https://www.php.cn/ko/update/article_0_1.html">Sitemap</a>
</div>
<div class="footerbottom">
<p>
© php.cn All rights reserved
</p>
</div>
</div>
</footer>
<input type="hidden" id="verifycode" value="/captcha.html">
<script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script>
<script src="/static/js/common_new.js"></script>
<script type="text/javascript" src="/static/js/jquery.cookie.js?1745532045"></script>
<script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script>
<link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all' />
<script type='text/javascript' src='/static/js/viewer.min.js?1'></script>
<script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script>
<script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script>
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function () {
var u = "https://tongji.php.cn/";
_paq.push(['setTrackerUrl', u + 'matomo.php']);
_paq.push(['setSiteId', '9']);
var d = document,
g = d.createElement('script'),
s = d.getElementsByTagName('script')[0];
g.async = true;
g.src = u + 'matomo.js';
s.parentNode.insertBefore(g, s);
})();
</script>
<script>
// top
layui.use(function () {
var util = layui.util;
util.fixbar({
on: {
mouseenter: function (type) {
layer.tips(type, this, {
tips: 4,
fixed: true,
});
},
mouseleave: function (type) {
layer.closeAll("tips");
},
},
});
});
document.addEventListener("DOMContentLoaded", (event) => {
// 定义一个函数来处理滚动链接的点击事件
function setupScrollLink(scrollLinkId, targetElementId) {
const scrollLink = document.getElementById(scrollLinkId);
const targetElement = document.getElementById(targetElementId);
if (scrollLink && targetElement) {
scrollLink.addEventListener("click", (e) => {
e.preventDefault(); // 阻止默认链接行为
targetElement.scrollIntoView({
behavior: "smooth"
}); // 平滑滚动到目标元素
});
} else {
console.warn(
`Either scroll link with ID '${scrollLinkId}' or target element with ID '${targetElementId}' not found.`
);
}
}
// 使用该函数设置多个滚动链接
setupScrollLink("Article_Details_main1L2s_1", "article_main_title1");
setupScrollLink("Article_Details_main1L2s_2", "article_main_title2");
setupScrollLink("Article_Details_main1L2s_3", "article_main_title3");
setupScrollLink("Article_Details_main1L2s_4", "article_main_title4");
setupScrollLink("Article_Details_main1L2s_5", "article_main_title5");
setupScrollLink("Article_Details_main1L2s_6", "article_main_title6");
// 可以继续添加更多的滚动链接设置
});
window.addEventListener("scroll", function () {
var fixedElement = document.getElementById("Article_Details_main1Lmain");
var scrollTop = window.scrollY || document.documentElement.scrollTop; // 兼容不同浏览器
var clientHeight = window.innerHeight || document.documentElement.clientHeight; // 视口高度
var scrollHeight = document.documentElement.scrollHeight; // 页面总高度
// 计算距离底部的距离
var distanceToBottom = scrollHeight - scrollTop - clientHeight;
// 当距离底部小于或等于300px时,取消固定定位
if (distanceToBottom <= 980) {
fixedElement.classList.remove("Article_Details_main1Lmain");
fixedElement.classList.add("Article_Details_main1Lmain_relative");
} else {
// 否则,保持固定定位
fixedElement.classList.remove("Article_Details_main1Lmain_relative");
fixedElement.classList.add("Article_Details_main1Lmain");
}
});
</script>
<script>
document.addEventListener('DOMContentLoaded', function() {
const mainNav = document.querySelector('.Article_Details_main1Lmain');
const header = document.querySelector('header');
if (mainNav) {
window.addEventListener('scroll', function() {
const scrollPosition = window.scrollY;
if (scrollPosition > 84) {
mainNav.classList.add('fixed');
} else {
mainNav.classList.remove('fixed');
}
});
}
});
</script>
</body>
</html>



 구체적인 사용법은 중국어 참고를 권장합니다: http://www.php.cn/
구체적인 사용법은 중국어 참고를 권장합니다: http://www.php.cn/