

이 섹션은 주로 특정 유형의 최적화 쿼리에 관한 것입니다.
(1) 카운트 쿼리 최적화
(2) 관련 검색어
(3) 하위 쿼리
(4) GROUP BY 및 DISTINCT 최적화
(5) LIMIT 페이징 최적화
COUNT() 집계 함수의 역할:
(1) 특정 값의 개수를 계산합니다. 열, 행 번호를 계산할 수도 있습니다. 컬럼 값을 계산할 때 컬럼 값이 비어 있지 않아야 한다는 점에 유의하세요(NULL은 계산되지 않음)
(2) 행 수 계산 결과 세트에서. 열 값을 비워둘 수 없는 경우 테이블의 행 수가 계산됩니다. 그러나 결과 집합의 행 수를 가져오려면 COUNT()를 사용해야 합니다. 와일드카드는 모든 열 값을 직접 무시하고 최적화할 행 수를 직접 계산합니다.
MyISAM 스토리지 엔진의 경우 MyISAM 자체가 이미 총 행 수를 저장했기 때문에 where 쿼리 조건이 단일 테이블에 제한되지 않을 때 COUNT(*)가 매우 빠릅니다. 자격 조건이 있는 경우 쿼리 통계도 필요합니다.
다음은 간단한 최적화 사용 예시입니다.
(1) 최적화 1:
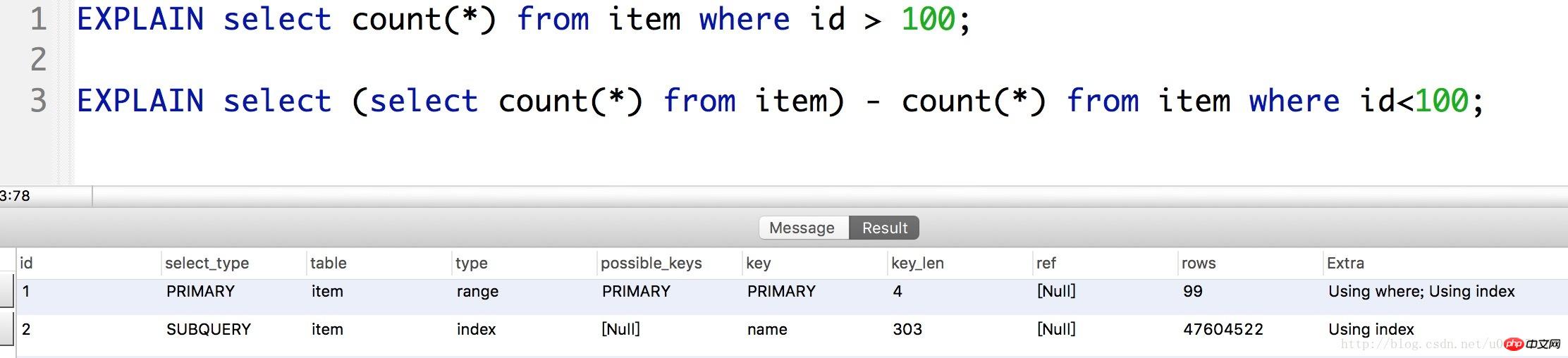
기록을 직접 확인해 보면 알 수 있습니다. id>100, 2천만 행 이상의 레코드 스캔이 포함됩니다. 하지만 COUNT() 기능으로 인해 count() - (id
(2) 최적화 2:
또 다른 최적화 방법은 Covering Index를 사용하는 것입니다.
(1) ON 또는 USING 절의 열에 인덱스가 있는지 확인합니다. 인덱스 생성 시 연관 순서를 고려해야 한다. 테이블 A와 테이블 B가 컬럼 c와 연관되어 있을 때 옵티마이저의 연관 순서가 B, A라면 테이블 A에만 인덱스를 생성하면 된다. 사용되지 않은 인덱스는 저장소
를 차지합니다. (2) Group by 및 order by 작업의 표현식 이 한 테이블의 열만 포함하는지 확인하세요. 이러한 방식으로 MySQL에서 인덱스 최적화
를 사용할 수 있습니다. 하위 쿼리는 임시 테이블을 생성하지 않기 때문입니다. like count(*) 임시 테이블은 매우 작습니다.
GROUP BY 및 DISTINCT를 최적화하는 가장 효과적인 방법은 인덱스를 사용하는 것입니다.
인덱스를 사용할 수 없는 경우 그룹화를 위한 임시 테이블 정렬 또는 파일 정렬이라는 두 가지 전략을 사용하여 그룹화를 완료합니다.
그룹화할 모든 열은 색인화되어야 합니다. 예:
select product, count(*) from orders group by product;
이러한 쿼리는 제품에 대한 색인을 생성해야 합니다.
페이징 작업을 수행할 때 일부 데이터는 일반적으로 오프셋을 통해 쿼리됩니다. 그런 다음 설명된 순서와 결합하여 성능이 일반적으로 좋습니다.
order by 열에 색인을 추가하세요.
그러나 10000, 10으로 제한되어 대상 10개의 레코드를 검색하려면 먼저 이전 10000개의 레코드를 쿼리해야 합니다. 이 경우 비용이 매우 높습니다. 최적화하는 가장 간단한 방법은 포함 인덱스를 사용하는 것입니다.
위 내용은 특정 유형의 쿼리에 대한 고성능 MySQL 세부 최적화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



