

Firefox 2.0의 XML 처리 개선 사항에 대한 코드 예제에 대한 자세한 소개(그림)

Firefox 2.0에는 XML 지원과 관련하여 몇 가지 중요한 개선 사항이 있습니다. 현재 사용자 배포가 급성장하고 있습니다. 논란의 여지가 있는 RSS 웹 피드 처리 변경 사항을 포함하여 Firefox 2.0 XML 기능의 개선 사항에 대해 알아보세요.
새로운 애플리케이션 플랫폼의 역할을 고려할 때 웹 브라우저는 아마도 요즘 가장 인기 있는 소프트웨어일 것입니다. 지금은 소프트웨어 개발자들에게는 흥미로운 시기입니다.
Firefox 2.0에는 XML 지원에 있어 몇 가지 중요한 개선 사항이 있습니다. 현재 사용자 배포가 급성장하고 있습니다. 논란의 여지가 있는 RSS 웹 피드 처리 변경 사항을 포함하여 Firefox 2.0 XML 기능의 개선 사항에 대해 알아보세요.
새로운 애플리케이션 플랫폼의 역할을 맡은 웹 브라우저는 아마도 현재 가장 인기 있는 소프트웨어일 것입니다. 동적 HTML 기술이 Asynchr유일한 JavaScript XML(Ajax) 및 Microsoft® Internet Explorer® 이력서 개발 등으로 다시 태어나기 때문에 소프트웨어 개발자에게는 흥미로운 시기입니다. 지난 2년 동안 XML 및 Firefox에 대한 개발자웍스 시리즈(참고자료 참조)에서는 핵심 Mozilla 브라우저 엔진 버전 1.8을 기반으로 하는 Firefox 버전 1.5를 출시했습니다. 그 이후 Mozilla 프로젝트의 끊임없는 개발 속도로 인해 Gecko 1.8.1 웹 렌더링 엔진을 기반으로 하는 Firefox 2.0이 탄생했습니다. Firefox 2.0의 개선 사항 중 일부에는 XML 처리가 포함됩니다. 이 문서에서는 개발자가 염두에 두어야 할 주요 장애물을 포함하여 최신 Firefox XML 처리 기능을 소개합니다.
웹 피드에 대한 제어 감소
Firefox 2.0의 변경으로 인해 사용자 커뮤니티는 상당한 경악을 금치 못했습니다. RSS 또는 Atom과 같은 웹 피드를 제공하는 경우 XSLT 스타일시트를 포함하여 사용자를 위한 다른 표현으로 변환할 수 있습니다. Listing 1의 Atom 피드 는 이러한 변환을 참조합니다.
목록 1. 스타일시트 참조가 포함된 Atom 피드
<?xml version="1.0" encoding="utf-8"?> <?xml-stylesheet type="text/xml" href="atom2html.xslt"?> <feed xmlns="http://www.w3.org/2005/Atom" xml:lang="en" xml:base="http://www.example.org"> <id>http://www.php.cn/;/id> <title>My Simple Feed</title> <updated>2005-07-15T12:00:00Z</updated> <link href="/blog" /> <link rel="self" href="/myfeed" /> <author><name>Uche Ogbuji</name></author> <entry> <id>http://www.php.cn/;/id> <title>A simple blog entry</title> <link href="/blog/2005/07/1" /> <updated>2005-07-14T12:00:00Z</updated> <summary>This is a simple blog entry</summary> </entry> <entry> <id>http://www.php.cn/;/id> <title /> <link href="/blog/2005/07/2" /> <updated>2005-07-15T12:00:00Z</updated> <summary>This is simple blog entry without a title</summary> </entry> </feed>
핵심은 두 번째 줄에 있습니다. Style 시트 처리 지침(PI). Firefox 1.5에서 열면 브라우저는 자동으로atom2html.xslt를 로드하고 결과를 표시합니다. 이 시리즈의 Part 2에서 언급한 것처럼(참고자료 참조) 실제 XML을 보려면 소스 보기를 거쳐야 한다. Firefox 2.0에서 브라우저는 그림 1(Firefox 2.0.0.6, Mac OS X의 스크린샷)과 같이 이 스타일시트 PI를 무시하고 사용자 정의 Firefox 보기를 사용합니다. 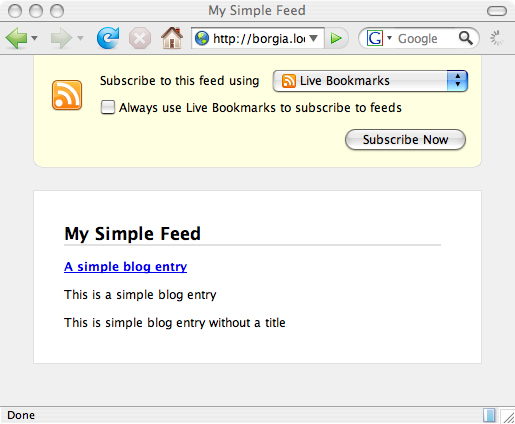 그림 1. Firefox 2.0 내장 웹 피드 보기
그림 1. Firefox 2.0 내장 웹 피드 보기
이를 방지하고 선택한 스타일시트를 강제로 사용하는 유일한 방법은 파일 앞에 512를 붙여서 단순한 Firefox를 속이는 것입니다. 웹 피드인지 확인하려면 "rss" 또는 "feed"를 바이트 단위로 검색하세요. 목록 2에서는
주석을 삽입하여 512바이트를 채우는 잘 알려진 방법을 사용합니다.
목록 2. Firefox 2.0 및 Internet Explorer 7 기본 스타일 시트 처리를 우회하는 Atom 피드
<?xml version="1.0" encoding="utf-8"?> <!-- Firefox 2.0 and Internet Explorer 7 use simplistic feed sniffing to override desired presentation behavior for this feed, and thus we are obliged to insert this comment, a bit of a waste of bandwidth, unfortunately. This should ensure that the following stylesheet processing instruction is honored by these new browser versions. For some more background you might want to visit the following bug report: http://www.php.cn/ --> <?xml-stylesheet type="text/xml" href="atom2html.xslt"?> <feed xmlns="http://www.w3.org/2005/Atom" xml:lang="en" xml:base="http://www.example.org"> <!-- content of the feed identical to listing 1, so trimmed --> </feed>
考虑了用户社区的反对意见之后,Firefox 开发人员决定坚持自身的立场,因而这种行为方式将保留到未来的 Firefox 版本之中。我个人不喜欢这种方式,您可以阅读有关的争论再决定喜欢与否。值得一提的是,这种做法与 Internet Explorer 和 Apple Safari 有相似之处。
#p#
微摘要
微摘要(microsummarie),也称为活动标题(Live Title)是 Firefox 2.0 一种简洁的新特性,可以让浏览器用网站中一些有意义的内容来替换标题,特别是在书签中。比如,IBM developerWorks 的微摘要可以用站点上的最新文章标题代替静态文字 “developerWorks : IBM's resource for developers”。网站可以提供一个微摘要,用户也可自行创建。后一种情况称为 “微摘要生成器”,也是本文更关注的一点,因为它要求用户端处理 XML 和 XSLT(不熟悉 XML 的人可以重复使用其他人提供的生成器)。清单 3 中的微摘要生成器提取 developerWorks 主打文章的标题。
清单 3. 使用 IBM developerWorks 主打文章标题的微摘要生成器
<?xml version="1.0" encoding="UTF-8"?> <generator xmlns="http://www.mozilla.org/microsummaries/0.1" name="IBM developerWorks featured article"> <template> <xsl:transform xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0" xmlns:html="http://www.w3.org/1999/xhtml"> <xsl:output method="text"/> <xsl:template match="/"> <xsl:text>Featured article:</xsl:text> <!-- On sites that make wider use of element IDs you can use more direct and efficient XPaths --> <xsl:value-of select="//html:a[@class='feature'][1]"/> </xsl:template> </xsl:transform> </template> <pages> <include>http://www.php.cn/[a-zA-Z0-9]*/?</include> </pages> </generator>
生成器包括两部分:模板和页面信息。模板包括应用于网页的提取微摘要文本的 XSLT 代码。后者指定浏览器把微摘要应用于哪个页面。微摘要是简单的文本,输出指令与此相适应。微摘要的关键在于 XPath //html:a[@class='feature'][1],查找包含主打文章标题的元素。pages 部分的正则表达式保证微摘要可用于网站首页和每个 developerWorks 专区的首页。
参考资料 提供的一篇教程说明了如何安装 清单 3 这样的微摘要生成器。到目前为止,微摘要还是 Mozilla 特有的特性。
SAX 及其他
对于那些开发 Mozilla 扩展的人来说,最有意义的是 Mozilla XPCOM 组件系统现在提供了一个 SAX 解析器框架。如果没有合适的高层处理技术,可以自行开发高效处理 XML 的扩展。XPCOM 集成意味着可以用 C 、JavaScript 或具有 XPCOM 绑定支持的其他任何语言来处理 SAX 事件。
OpenSearch
OpenSearch 是 Amazon A9 孵化器开发的一个 XML 标准。它提供了几种 XML 格式和其他约定来描述和使用搜索引擎。Firefox 一直强力支持可扩展的搜索引擎插件,2.0 引入了 OpenSearch 支持,因而可以通过与 Iternet Explorer 及其他浏览器兼容的机制扩展搜索功能。
Firefox 支持的 OpenSearch 1.1 目前是 beta 版,为保持与 Firefox 和 OpenSearch 的兼容性,可能需要更新。清单 4 提供了对于 IBM developerWorks 的 OpenSearch 描述文档。
清单 4. IBM developerWorks 的 OpenSearch 描述文档
<?xml version="1.0" encoding="UTF-8"?>
<OpenSearchDescription xmlns="http://a9.com/-/spec/opensearch/1.1/">
<ShortName>IBM developerWorks search</ShortName>
<Description>Search IBM developerWorks zones</Description>
<Tags>xml java architecture</Tags>
<InputEncoding>utf-8</InputEncoding>
<Contact>http://www.php.cn/
</Contact>
<!-- The template attribute is split at the "?" for formatting purposes -->
<Url type="text/html"
template="http://www.ibm.com/developerworks/views/xml/
libraryview.jsp?
search_by={searchTerms}"/>
<Attribution>All content Copyright 2007, IBM developerWorks</Attribution>
</OpenSearchDescription>
该文档仅仅说明 IBM developerWorks 提供了一个搜索 URL:
http://www.ibm.com/developerworks/views/xml/libraryview.jsp?search_by={searchTerms}其中的 {searchTerms} 是一个模板参数,搜索工具将使用搜索项目来代替它。如果搜索 “Firefox XML”,URL 将变成:
http://www.ibm.com/developerworks/views/xml/libraryview.jsp?search_by=Firefox XML
OpenSearch 规范了定义了这种 URL 模板系统。OpenSearch 还定义了把结果返回为 RSS 2.0 或 Atom 1.0 提要的约定和几种专用的扩展。Firefox 还不支持这种 Web 提要搜索结果,如果描述不含 Url 元素和 type="text/html"(表示从 URL 返回的内容类型)则返回错误。这种限制很不合理,但也可能是基于多数人仍然通过传统 HTML 表单和结果页面而不是 Web 2.0 机制搜索的现实考量。
在 Firefox 2.0 中,清单 4 这样的 OpenSearch 描述就像是完整的搜索引擎插件。网站可以使用页面头部的链接指定这样的描述,比如:
<link rel="search" type="application/opensearchdescription xml" title="IBM developerWorks" href="/path/to/opensearch/description/document.xml"/>
注意:前面的三行代码通常显示为一行。为了便于显示和打印而分解成多行。
结束语
仍在 alpha 测试阶段的 Firefox 3.0 将带来更重要的 XML 特性。预计将在 2008 年上半年发布完整的版本。包括关于 XML 处理的重要 bug 修正和新的特性,当它成为主流 Firefox 版本的时候我将继续讨论。Mozilla 核心 XML 工具箱仍然在不断改进,对于涉及 XML 技术的开发人员和用户来说是一大福音。对于多数用户和开发人员来说,Web 浏览器是 XML 处理的脸面,本系列文章讲继续追踪和讨论最新 Firefox 版本的相关特性。
위 내용은 Firefox 2.0의 XML 처리 개선 사항에 대한 코드 예제에 대한 자세한 소개(그림)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7318
7318
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 PowerPoint를 사용하여 XML 파일을 열 수 있나요?
Feb 19, 2024 pm 09:06 PM
PowerPoint를 사용하여 XML 파일을 열 수 있나요?
Feb 19, 2024 pm 09:06 PM
XML 파일을 PPT로 열 수 있나요? XML, Extensible Markup Language(Extensible Markup Language)는 데이터 교환 및 데이터 저장에 널리 사용되는 범용 마크업 언어입니다. HTML에 비해 XML은 더 유연하고 자체 태그와 데이터 구조를 정의할 수 있으므로 데이터 저장과 교환이 더 편리하고 통합됩니다. PPT 또는 PowerPoint는 프레젠테이션 작성을 위해 Microsoft에서 개발한 소프트웨어입니다. 이는 포괄적인 방법을 제공합니다.
 Python을 사용하여 XML 데이터 필터링 및 정렬
Aug 07, 2023 pm 04:17 PM
Python을 사용하여 XML 데이터 필터링 및 정렬
Aug 07, 2023 pm 04:17 PM
Python을 사용하여 XML 데이터 필터링 및 정렬 구현 소개: XML은 데이터를 태그 및 속성 형식으로 저장하는 일반적으로 사용되는 데이터 교환 형식입니다. XML 데이터를 처리할 때 데이터를 필터링하고 정렬해야 하는 경우가 많습니다. Python은 XML 데이터를 처리하는 데 유용한 많은 도구와 라이브러리를 제공합니다. 이 기사에서는 Python을 사용하여 XML 데이터를 필터링하고 정렬하는 방법을 소개합니다. XML 파일 읽기 시작하기 전에 XML 파일을 읽어야 합니다. Python에는 많은 XML 처리 라이브러리가 있습니다.
 Python에서 XML 데이터를 CSV 형식으로 변환
Aug 11, 2023 pm 07:41 PM
Python에서 XML 데이터를 CSV 형식으로 변환
Aug 11, 2023 pm 07:41 PM
Python의 XML 데이터를 CSV 형식으로 변환 XML(ExtensibleMarkupLanguage)은 데이터 저장 및 전송에 일반적으로 사용되는 확장 가능한 마크업 언어입니다. CSV(CommaSeparatedValues)는 데이터 가져오기 및 내보내기에 일반적으로 사용되는 쉼표로 구분된 텍스트 파일 형식입니다. 데이터를 처리할 때, 간편한 분석과 처리를 위해 XML 데이터를 CSV 형식으로 변환해야 하는 경우가 있습니다. 파이썬은 강력하다
 Python을 사용하여 XML 데이터 병합 및 중복 제거
Aug 07, 2023 am 11:33 AM
Python을 사용하여 XML 데이터 병합 및 중복 제거
Aug 07, 2023 am 11:33 AM
Python을 사용하여 XML 데이터 병합 및 중복 제거 XML(eXtensibleMarkupLanguage)은 데이터를 저장하고 전송하는 데 사용되는 마크업 언어입니다. XML 데이터를 처리할 때 여러 XML 파일을 하나로 병합하거나 중복된 데이터를 제거해야 하는 경우가 있습니다. 이 기사에서는 Python을 사용하여 XML 데이터 병합 및 중복 제거를 구현하는 방법을 소개하고 해당 코드 예제를 제공합니다. 1. XML 데이터 병합 XML 파일이 여러 개인 경우 이를 병합해야 합니다.
 Python은 XML과 JSON 간의 변환을 구현합니다.
Aug 07, 2023 pm 07:10 PM
Python은 XML과 JSON 간의 변환을 구현합니다.
Aug 07, 2023 pm 07:10 PM
Python은 XML과 JSON 간의 변환을 구현합니다. 소개: 일상적인 개발 프로세스에서 우리는 종종 서로 다른 형식 간에 데이터를 변환해야 합니다. XML과 JSON은 일반적인 데이터 교환 형식입니다. Python에서는 다양한 라이브러리를 사용하여 XML과 JSON을 변환할 수 있습니다. 이 문서에서는 코드 예제와 함께 일반적으로 사용되는 몇 가지 방법을 소개합니다. 1. Python에서 XML을 JSON으로 변환하려면 xml.etree.ElementTree 모듈을 사용할 수 있습니다.
 Python을 사용하여 XML의 오류 및 예외 처리
Aug 08, 2023 pm 12:25 PM
Python을 사용하여 XML의 오류 및 예외 처리
Aug 08, 2023 pm 12:25 PM
Python을 사용하여 XML에서 오류 및 예외 처리하기 XML은 구조화된 데이터를 저장하고 표현하는 데 일반적으로 사용되는 데이터 형식입니다. Python을 사용하여 XML을 처리할 때 때때로 오류와 예외가 발생할 수 있습니다. 이 기사에서는 Python을 사용하여 XML의 오류 및 예외를 처리하는 방법을 소개하고 참조용 샘플 코드를 제공합니다. XML 구문 분석 오류를 잡기 위해 try-Exception 문을 사용하십시오. Python을 사용하여 XML을 구문 분석할 때 가끔 오류가 발생할 수 있습니다.
 PHP를 사용하여 XML 데이터를 데이터베이스로 가져오기
Aug 07, 2023 am 09:58 AM
PHP를 사용하여 XML 데이터를 데이터베이스로 가져오기
Aug 07, 2023 am 09:58 AM
PHP를 사용하여 데이터베이스로 XML 데이터 가져오기 소개: 개발 중에 추가 처리 및 분석을 위해 외부 데이터를 데이터베이스로 가져와야 하는 경우가 많습니다. 일반적으로 사용되는 데이터 교환 형식인 XML은 구조화된 데이터를 저장하고 전송하는 데 자주 사용됩니다. 이 기사에서는 PHP를 사용하여 XML 데이터를 데이터베이스로 가져오는 방법을 소개합니다. 1단계: XML 파일 구문 분석 먼저 XML 파일을 구문 분석하고 필요한 데이터를 추출해야 합니다. PHP는 XML을 구문 분석하는 여러 가지 방법을 제공하며 그 중 가장 일반적으로 사용되는 방법은 Simple을 사용하는 것입니다.
 PHP와 XML을 사용하여 지리적 위치 및 지도 데이터 처리 및 표시
Aug 01, 2023 am 08:37 AM
PHP와 XML을 사용하여 지리적 위치 및 지도 데이터 처리 및 표시
Aug 01, 2023 am 08:37 AM
PHP 및 XML을 사용하여 위치 정보 및 지도 데이터 처리 및 표시 개요: 위치 정보 및 지도 데이터 처리 및 표시는 웹 애플리케이션을 개발할 때 일반적인 요구 사항입니다. PHP는 XML 형식의 데이터와 상호 작용할 수 있는 널리 사용되는 서버측 프로그래밍 언어입니다. 이 문서에서는 PHP와 XML을 사용하여 지리적 위치 및 지도 데이터를 처리하고 표시하는 방법을 설명하고 몇 가지 샘플 코드를 제공합니다. 1. 준비: 시작하기 전에 PHP 및 Simple과 같은 관련 확장이 서버에 설치되어 있는지 확인해야 합니다.
