| 직원 아니요. |
직원 이름 |
직위 |
연봉 |
E0001 |
잭 |
근로자 |
3000/월 |
E0002 |
가입 |
근로자 |
3000/월 |
E0003 |
애플 |
선임 정비사 |
6000/월
이런 식으로 표 1-1은 두 개의 표가 되며, 각 표는 한 가지 내용만 명확하고 명확하게 설명합니다.
제3정규형(3NF)
세 번째 정규형은 두 번째 정규형을 기반으로 하며 한 단계 더 발전합니다. 세 번째 정규형의 목표는 테이블의 각 열이 기본 키 열과 간접적으로 관련되지 않도록 하는 것입니다. 즉, 각 컬럼은 기본키 컬럼과 직접적인 종속관계를 가지며, 이는 제3정규형을 만족한다.
세 번째 정규형에서는 각 열이 기본 키 열과 직접 관련되어 있어야 합니다. 이런 식으로 이해할 수 있습니다. Zhang San은 Li Si의 폰이고 Wang Wu는 이때 Wang Wu의 폰입니다. 이 관계에서 우리는 Wang Wu도 Li Si의 군인이라는 것을 알 수 있습니다. 왜냐하면 Wang Wu는 Zhang San에 의존하고 있고 Zhang San은 Li Si의 군인이므로 Wang Wu도 Li Si의 군인이기 때문입니다. 세 번째 패러다임에서 강조된 직접적인 의존 관계보다는 간접적인 의존 관계가 있습니다.
이제 두 번째 패러다임에 대한 설명을 살펴보겠습니다. 표 1-1을 두 개의 테이블로 나눕니다. 이 두 테이블은 제3정규형을 따르나요? 직원 정보 테이블에는 "직원 번호", "직원 이름", "직위", "급여 수준"이 포함되어 있으며 급여 수준은 직위에 따라 결정됩니다. 여기서 "급여 수준"은 다음을 통해 직원과 관련됩니다. "위치"는 제3정규형을 따르지 않습니다. 직원 정보 테이블을 다음과 같이 추가로 분할해야 합니다.
이제 데이터베이스 정규화 설계의 세 가지 주요 패러다임을 이해했으므로 표 1-1의 최적화된 데이터 테이블을 살펴보겠습니다.
직원 정보 테이블(Employee)
员工编号 |
员工姓名 |
职务编号 |
E0001 |
Jack |
1 |
E0002 |
Join |
1 |
E0003 |
Apple |
2 |
직원 번호
|
工程编号 |
工程名称 |
工程地址 |
P001 |
港珠澳大桥 |
广东珠海 |
P002 |
南海航天 |
海南三亚 |
직원 이름
|
职务编号 |
职务名称 |
工资待遇 |
1 |
工人 |
3000/月 |
2 |
高级技工 |
6000/月 |
직위 번호 |
E0001 |
잭 |
1 |
E0002 |
가입 |
1 |
E0003 |
애플 |
2 |
프로젝트 정보 테이블(ProjectInfo)
프로젝트 번호 |
프로젝트 이름 |
프로젝트 주소 |
P001 |
홍콩-주하이-마카오 대교 |
주하이, 광둥 |
P002 |
난하이 항공우주 |
싼야, 하이난 |
의무
직위 번호 |
직위 이름 |
급여 tr> |
1 |
근로자 |
3000/월 |
2 |
수석 정비사 |
6000/월 |
工程参与人员记录表(Project_ Employee_info)
|
방향
编号 |
工程编号 |
人员编号 |
1 |
P001 |
E0001 |
2 |
P001 |
E0002 |
3 |
P002 |
E0003 |
|
工程编号 |
인력 강함> |
1 |
P001 |
E0001 |
2 |
P001 |
E0002 |
3 |
P002 |
E0003 |
비교해 보면, 테이블이 많아지고, 관계가 복잡해지고, 데이터를 쿼리하기가 더 번거로워지고, 프로그래밍의 난이도도 높아지는 것을 알 수 있었습니다. 그러나 각 테이블의 내용이 더 명확해지고, 중복된 데이터가 적어졌습니다. 업데이트하고 유지 관리하는 것이 더 쉽습니다. 이 모순의 균형을 맞추는 방법은 무엇입니까?
1.4.3. 패러다임과 효율성
데이터베이스를 디자인할 때 디자이너, 고객, 개발자는 일반적으로 데이터베이스 디자인에 대해 일정한 갈등을 겪습니다. 고객은 편리하고 명확한 결과를 선호하며 개발자도 데이터베이스 관계가 개발의 어려움을 줄이기 위해 더 단순해지기를 바라지만 디자이너는 필요합니다. 세 가지 주요 패러다임을 적용하여 데이터베이스를 엄격하게 표준화하고, 데이터 중복성을 줄이고, 데이터베이스 유지 관리 및 확장성을 향상시킵니다. 이를 통해 우리의 데이터베이스 설계는 고객과 개발자에 따라 차이가 있을 것임을 알 수 있습니다. 따라서 실제 데이터베이스 설계에서는 맹목적으로 표준화를 추구할 수 없으며 데이터를 줄여야 합니다. 다양한 데이터베이스가 비정상적으로 운영되는 경우 데이터베이스의 성능 문제를 충분히 고려하고 적절한 데이터베이스 이중화를 허용해야 합니다.
2. MySQL 소개
2.1. MySQL 개요
MySQL은 스웨덴의 MySQL AB 회사가 개발한 관계형 데이터베이스 관리 시스템으로 현재 Oracle의 제품입니다. MySQL은 웹 애플리케이션 측면에서 가장 널리 사용되는 관계형 데이터베이스 관리 시스템 중 하나이며, MySQL은 최고의 RDBMS(관계형 데이터베이스 관리 시스템) 애플리케이션 소프트웨어 중 하나입니다.

MySQL은 관계형 데이터베이스 관리 시스템입니다. 관계형 데이터베이스는 모든 데이터를 하나의 큰 창고에 저장하는 대신 여러 테이블에 저장하므로 속도와 유연성이 향상됩니다.
MySQL에서 사용하는 SQL 언어는 데이터베이스 액세스에 가장 일반적으로 사용되는 표준화된 언어입니다. MySQL 소프트웨어는 이중 라이센스 정책을 채택하고 있으며 작은 크기, 빠른 속도, 낮은 총 소유 비용, 특히 오픈 소스의 특성으로 인해 커뮤니티 버전과 상용 버전으로 구분됩니다. 중소규모 웹사이트 개발.
MySQL 다운로드
2.2. 시스템 특징
1. C 및 C++로 작성되었으며 소스 코드 이식성을 보장하기 위해 다양한 컴파일러를 사용하여 테스트되었습니다.
2. AIX, FreeBSD, HP-UX, Linux, Mac OS, NovellNetware, OpenBSD, OS/2 Wrap, Solaris, Windows 및 기타 운영 체제를 지원합니다.
3. API는 여러 프로그래밍 언어에 대해 제공됩니다. 이러한 프로그래밍 언어에는 C, C++, Python, Java, Perl, PHP, 에펠, 루비, .NET 및 Tcl 등이 포함됩니다.
4. 멀티스레딩을 지원하고 CPU 리소스를 최대한 활용합니다.
5. 최적화된 SQL 쿼리 알고리즘은 쿼리 속도를 효과적으로 향상시킵니다.
6. 클라이언트-서버 네트워크 환경에서 독립형 애플리케이션으로 사용하거나 다른 소프트웨어에 라이브러리로 내장할 수 있습니다.
7. 다국어 지원이 제공됩니다. 중국어 GB 2312, BIG5, 일본어 Shift_JIS 등의 공통 인코딩을 데이터 테이블 이름 및 데이터 열 이름으로 사용할 수 있습니다.
8. TCP/IP, ODBC, JDBC 등 다양한 데이터베이스 연결 채널을 제공합니다.
9. 데이터베이스 운영을 관리, 확인, 최적화하기 위한 관리 도구를 제공합니다.
10. 대규모 데이터베이스를 지원합니다. 수천만 개의 레코드가 포함된 대규모 데이터베이스를 처리할 수 있습니다.
11. 여러 스토리지 엔진을 지원합니다.
12.MySQL은 오픈 소스이므로 추가 비용을 지불할 필요가 없습니다.
13.MySQL은 표준 SQL 데이터 언어 형식을 사용합니다.
14.MySQL은 현재 가장 널리 사용되는 웹 개발 언어인 PHP를 훌륭하게 지원합니다.
15.MySQL은 사용자 정의가 가능하며 GPL 프로토콜을 채택하여 소스 코드를 수정하여 자신만의 MySQL 시스템을 개발할 수 있습니다.
16. 온라인 DDL/변경 기능, 데이터 아키텍처는 동적 애플리케이션 및 개발자 유연성을 지원합니다(5.6의 새로운 기능)
17. 자가 복구 클러스터를 지원하기 위한 전역 트랜잭션 식별자 복사(5.6의 새로운 기능)
18. 가용성 향상을 위해 충돌 없는 슬레이브 머신 복제(5.6의 새로운 기능)
19. 성능 향상을 위해 멀티스레드 슬레이브 복사(5.6의 새로운 기능)
20.3배 더 빠른 성능(5.7의 새로운 기능)
21. 새로운 최적화 프로그램(5.7의 새로운 기능)
22. 기본 JSON 지원(5.7의 새로운 기능)
23. 다중 소스 복제(5.7의 새로운 기능)
24.GIS 공간 확장(5.7의 새로운 기능)
2.3. 스토리지 엔진
MySQL 데이터베이스는 애플리케이션의 요구에 따라 다양한 엔진을 준비했습니다. 차이점은 다음과 같습니다.
MyISAM MySQL 5.0 이전의 기본 데이터베이스 엔진으로 가장 일반적으로 사용됩니다. 삽입 및 조회 속도가 높지만 트랜잭션을 지원하지 않습니다
InnoDB는 트랜잭션 데이터베이스에 선호되는 엔진으로, ACID 트랜잭션과 행 수준 잠금을 지원하며 MySQL 5.5
부터 기본 데이터베이스 엔진이 되었습니다.
BDB는 트랜잭션 데이터베이스의 또 다른 옵션인 Berkeley DB에서 유래되었으며 커밋 및 롤백과 같은 다른 트랜잭션 기능을 지원합니다
메모리는 모든 데이터를 메모리에 저장하는 스토리지 엔진으로 삽입, 업데이트, 쿼리 효율성이 매우 높습니다. 하지만 데이터 양에 비례하여 메모리 공간을 차지하게 됩니다. MySQL을 다시 시작하면 해당 내용이 손실됩니다.
Merge는 일정 수의 MyISAM 테이블을 전체로 결합하므로 대규모 데이터 저장에 매우 유용합니다
아카이브는 대량의 독립적인 기록 데이터를 저장하는 데 이상적입니다. 자주 읽히지 않기 때문입니다. Archive는 삽입 속도가 효율적이나 쿼리 지원이 상대적으로 열악합니다
Federated는 서로 다른 MySQL 서버를 결합하여 논리적으로 완전한 데이터베이스를 형성합니다. 분산 애플리케이션에 매우 적합
Cluster/NDB는 여러 데이터 시스템을 사용하여 전반적인 성능과 보안을 향상시키는 서비스를 공동으로 제공하는 고도로 중복된 스토리지 엔진입니다. 데이터 양이 많고 보안 및 성능 요구 사항이 높은 애플리케이션에 적합
CSV는 데이터를 쉼표로 논리적으로 구분하는 스토리지 엔진입니다. 데이터베이스 하위 디렉터리의 각 데이터 테이블에 대해 .csv 파일을 생성합니다. 이는 각 데이터 줄이 하나의 텍스트 줄을 차지하는 일반 텍스트 파일입니다. CSV 저장소 엔진은 인덱싱을 지원하지 않습니다.
BlackHole 블랙홀 엔진, 기록된 데이터는 모두 사라집니다. 일반적으로 복제를 위한 릴레이로 binlog를 기록하는 데 사용됩니다
EXAMPLE 스토리지 엔진은 아무 작업도 수행하지 않는 스텁 엔진입니다. 이는 새로운 스토리지 엔진 작성을 시작하는 방법을 보여주기 위해 MySQL 소스 코드의 예제로 작성되었습니다. 다시 말하지만, 주요 관심은 개발자입니다. 예 스토리지 엔진은 인덱싱을 지원하지 않습니다.
또한 MySQL의 스토리지 엔진 인터페이스가 잘 정의되어 있습니다. 관심 있는 개발자는 문서를 읽고 자신만의 스토리지 엔진을 작성할 수 있습니다.
그림 3: 데이터베이스 스토리지 엔진 비교
3. MySQL 데이터베이스를 빠르게 설치하고 실행하세요
MySQL은 과거에도 항상 오픈 소스였으며 무료였습니다. Oracle에 인수된 후 몇 가지 변경 사항이 있었습니다. 이전 버전은 모두 무료였고, 커뮤니티 버전은 GPL 계약에 따라 오픈 소스이며 무료였으며, 상용 버전은 더욱 풍부한 기능을 제공합니다. 기능은 있지만 수수료가 부과됩니다.
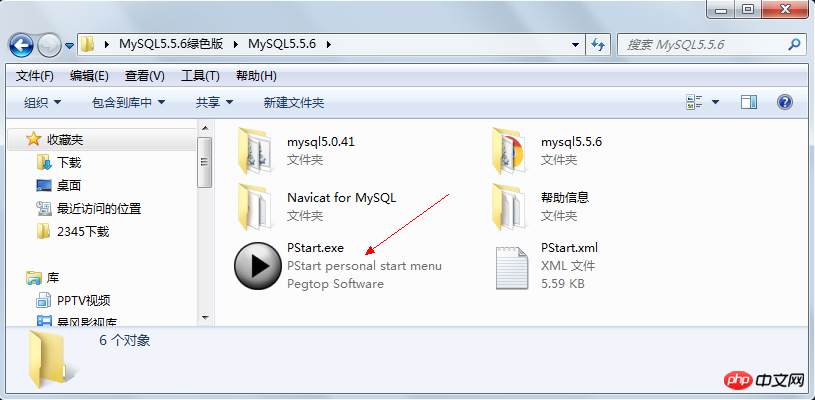
3.1. 그린 버전을 사용하세요
MySQL을 편리하고 빠르게 사용하기 위해 별도의 설정 없이 압축을 푼 후 바로 사용할 수 있는 그린 MySQL을 준비했습니다.
다운로드 후 바로 압축을 푸세요:
PStart.exe를 시작하려면 클릭하세요. 이것은 리소스를 구성하는 데 사용되는 메뉴를 사용자 정의하는 작은 도구입니다.
MySQL 소프트웨어 5.0과 5.5에는 두 가지 그린 버전이 있습니다
Navicat for MySQL은 데이터베이스 클라이언트 관리 도구입니다
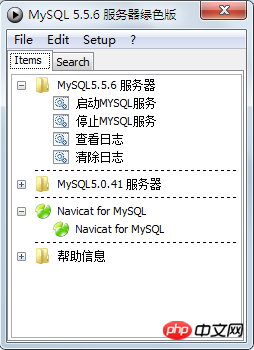
클릭하여 PStart.exe를 시작한 후의 결과는 다음과 같습니다.
MySQL 서비스를 시작하고 Navicat for MySQL을 실행하려면 클릭하세요.
3.1.1 mysql 원격 접속 설정
mysql 명령을 실행하여 mysql 명령 모드로 진입한 후 다음 SQL 코드 mysql> use mysql;
mysql> GRANT ALL ON *.* TO admin@'%' IDENTIFIED BY 'admin' WITH GRANT OPTION; 로그인 후 복사 를 실행합니다.
#이 문장의 의미는 IP 주소(위의 %가 의미함)를 가진 모든 컴퓨터가 관리자 계정과 비밀번호(admin)를 사용하여 이 MySQL 서버에 액세스할 수 있도록 허용한다는 것입니다
#그 전에 이와 같은 계정을 추가해야 합니다 원격으로 로그인할 수 있습니다. 루트 계정은 원격으로 로그인할 수 없으며 로컬로만 로그인할 수 있습니다
3.1.2. mysql 사용자 비밀번호 수정 1. mysqladmin 명령
형식은 다음과 같습니다(USER는 사용자 이름이고 PASSWORD는 새 비밀번호입니다): mysqladmin -u USER -p password PASSWORD 로그인 후 복사
이 명령을 입력하면 원래 비밀번호를 입력하라는 메시지가 표시됩니다. 올바르게 입력한 후에는 수정할 수 있습니다.
예를 들어 루트 사용자의 비밀번호가 123456으로 설정된 경우 mysqladmin -u root -p password 123456 로그인 후 복사 2.UPDATE 사용자 명령문
이 방법은 먼저 루트 계정으로 mysql에 로그인한 후 다음을 실행해야 합니다. UPDATE user SET password=PASSWORD('123456') WHERE user='root';
FLUSH PRIVILEGES; 로그인 후 복사 3.SET PASSWORD 문
이 방법을 사용하려면 먼저 root 명령으로 mysql에 로그인한 후 다음을 실행해야 합니다. SET PASSWORD FOR root=PASSWORD('123456'); 로그인 후 복사 4. 루트 비밀번호를 분실한 상황
저는 MySQL 버전 5.0과 함께 제공되는 도구인 "MySQL GUI 도구"를 사용합니다. 설치 디렉터리에서 MySQLSystemTrayMonitor.exe 프로그램을 실행하면 시스템 트레이에 아이콘이 나타납니다. MySQL 서비스가 설치되지 않은 경우에는 먼저 작업>MySQL 인스턴스 관리를 통해 서비스를 구성하고 설치할 수 있습니다. 서비스가 설치된 경우 마우스 오른쪽 버튼을 클릭하면 "인스턴스 구성" 메뉴가 나타납니다. 클릭하면 다음과 같은 MySQL 관리자 창이 나타납니다.
원래 서비스 구성이 정상이라면 왼쪽 목록에서 "시작 변수"를 선택하고 오른쪽 해당 라벨에서 "보안"을 선택한 후 "사용 안 함"을 선택합니다. 테이블 부여"를 선택한 다음 "변경 사항 적용"을 선택합니다.
그리고 왼쪽의 "서버 제어"와 오른쪽의 해당 "서비스 시작/중지" 탭으로 돌아가서 서비스 시작을 클릭합니다. 이제 mysql에 연결하는 데 더 이상 사용자 이름과 비밀번호가 필요하지 않습니다. 루트 비밀번호를 변경할 수 있습니다.
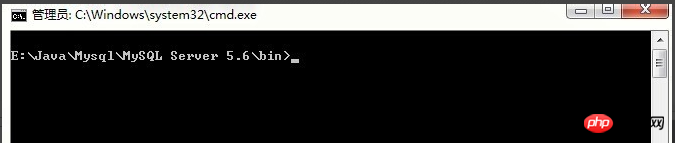
3.1.2. 설치 서비스
먼저 mysql 설치 디렉터리 아래 bin 디렉터리를 먼저 입력한 뒤, DOS 명령창을 열고 디렉터리를 입력합니다. (꼭 디렉터리를 입력해야 합니다. 그렇지 않으면 작업이 잘못됩니다.)
DOS 명령 실행:
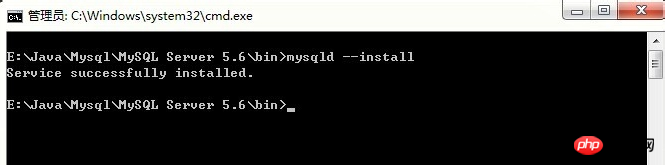
mysqld –install 명령을 입력하면 다음 인터페이스가 나타납니다. 서비스 설치가 성공했다는 메시지가 나타납니다.
mysql –install이 아니라 mysqld –install입니다.
서비스를 제거하려면 mysqld –remove 명령을 입력하면 됩니다. 다음 인터페이스가 나타납니다. 서비스가 성공적으로 제거되었다는 메시지를 표시합니다.
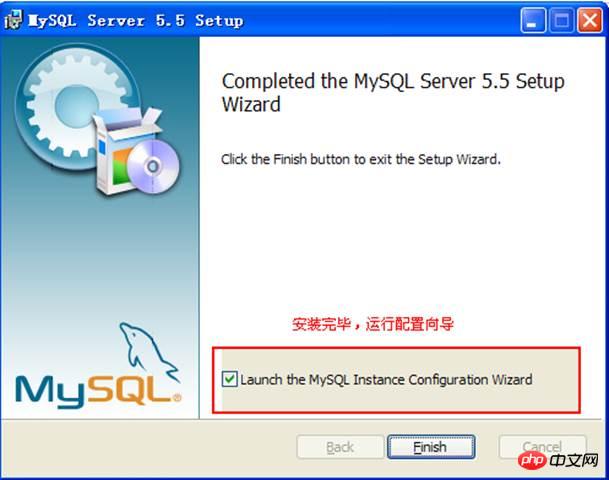
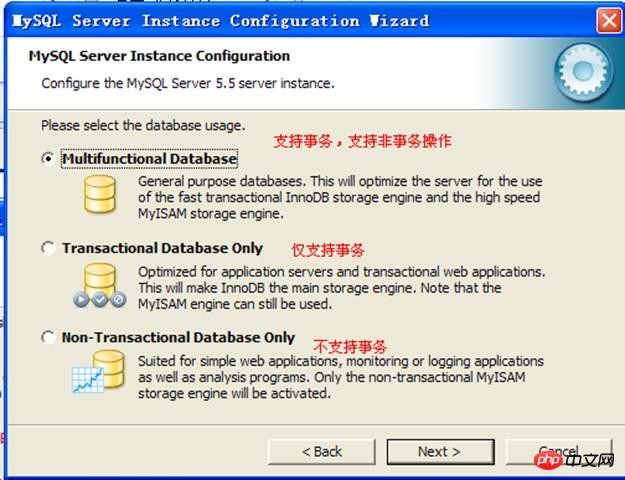
3.2. 설치 버전MySQL5.5.12 설치 패키지 를 사용하세요.
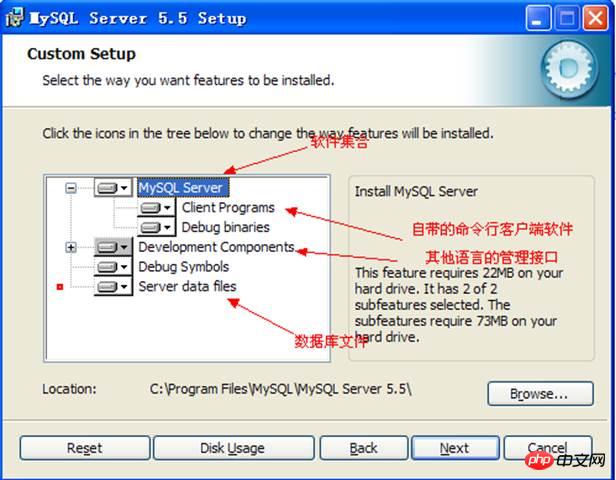
맞춤설정 선택:
설치된 구성요소 정보:
서버 소프트웨어 디렉터리:
데이터 디렉터리:
설치하려면 설치를 클릭하세요.
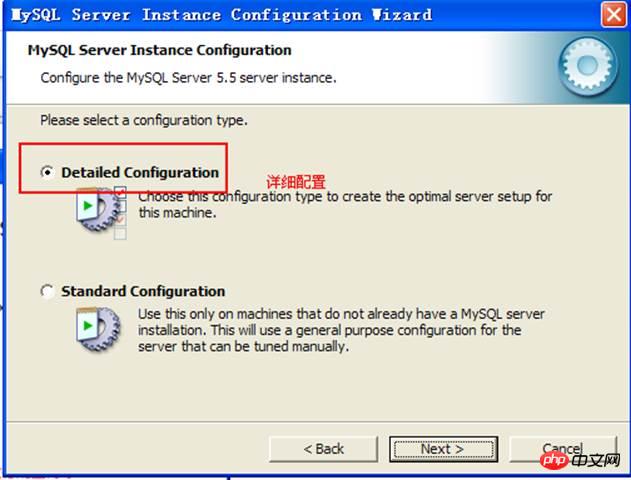
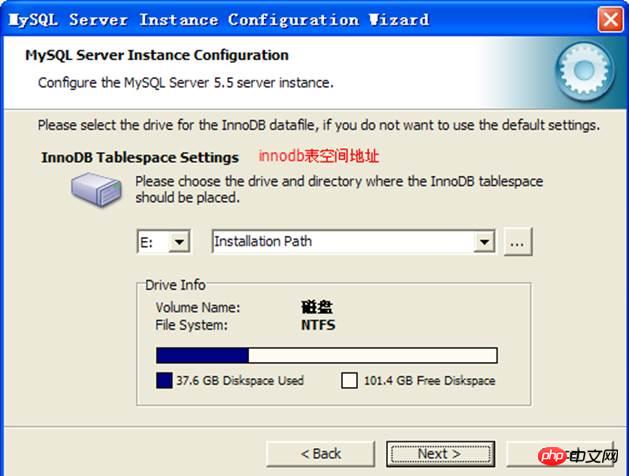
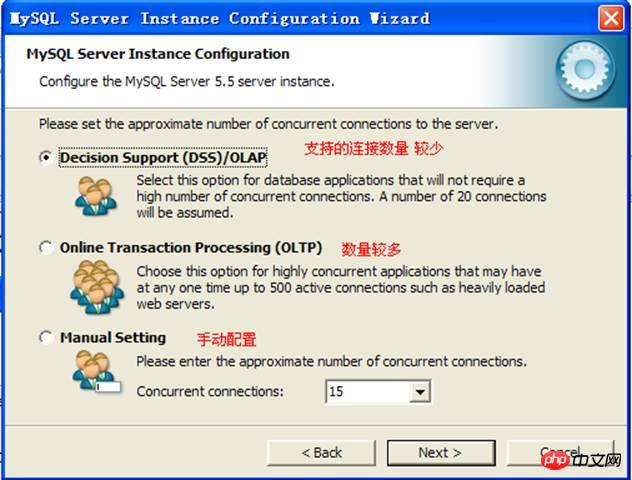
구성:
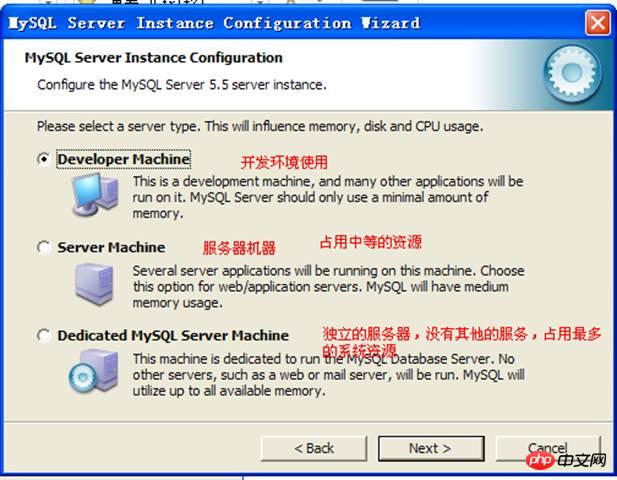
머신 종류
거래 기능 지원 여부:
innodb 테이블 공간:
연결 수:
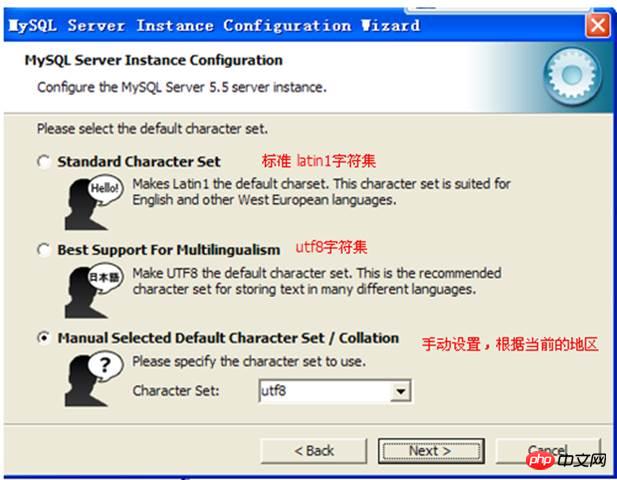
문자셋 설정 :
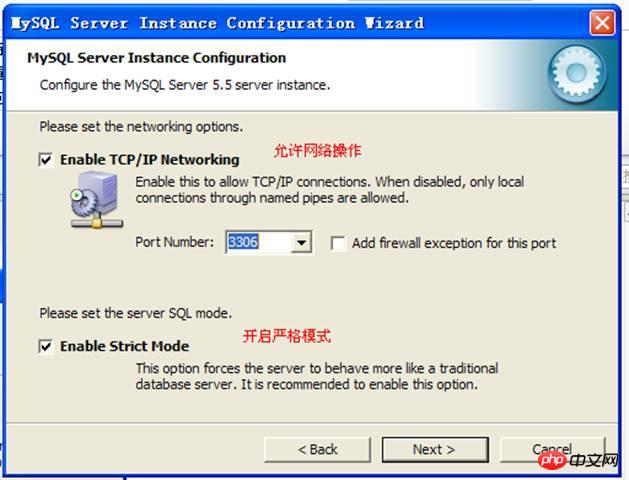
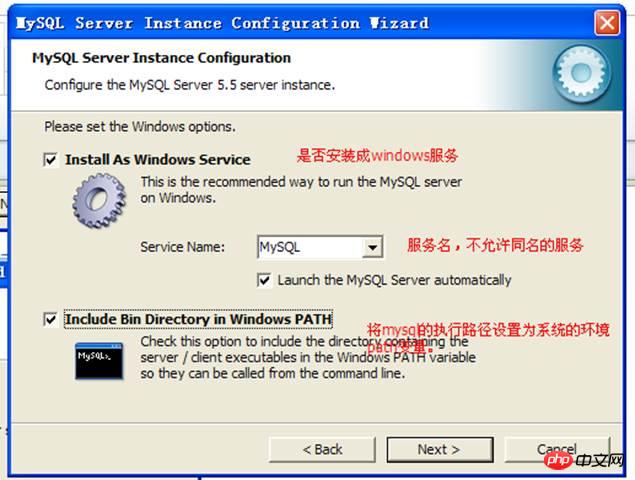
Windows 관리 관련 구성:
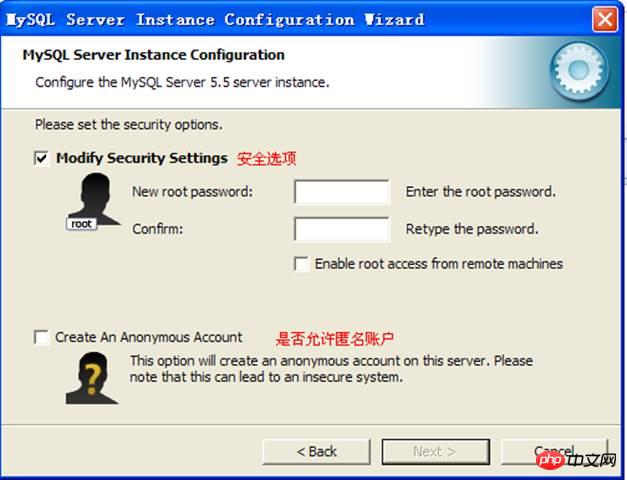
보안 옵션을 구성하고 관리자의 사용자 이름과 비밀번호를 설정하세요:
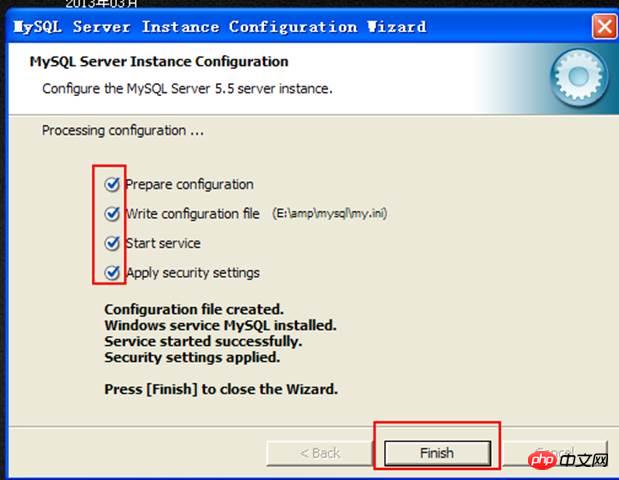
마지막으로 구성을 실행합니다:
구성이 완료되면 서비스가 시작됩니다.
새 버전의 MySQL 설치 패키지는 훨씬 더 크고 설치 프로세스도 다소 다릅니다.
4. GUI를 활용한 MySQL 운영
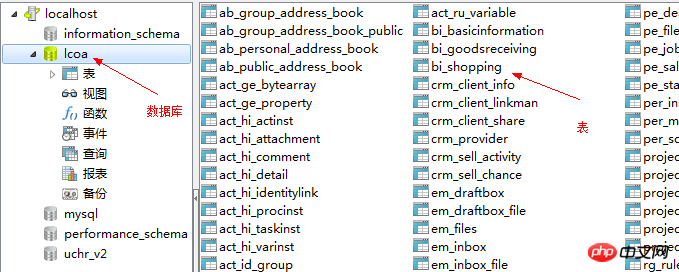
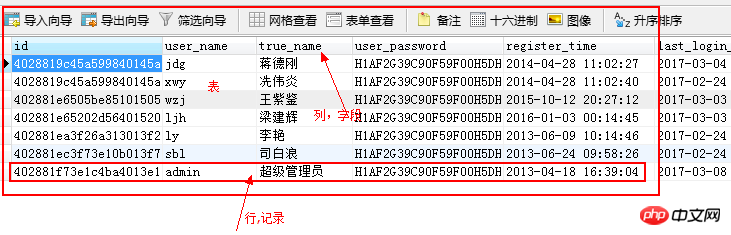
4.1. 관계형 데이터베이스의 일반적인 개념
데이터베이스 데이터베이스: 데이터 웨어하우스
테이블 테이블: 데이터는 테이블에 저장됩니다. 테이블에 저장된 데이터는 동일한 데이터 형식을 가져야 합니다
행: 행은 데이터를 기록하는 데 사용됩니다
기록: 행의 데이터
열: 열은 데이터 형식을 지정하는 데 사용됩니다
필드: 데이터 열
SQL: 데이터를 관리하는 데 사용되는 언어입니다. 구조적 쿼리 언어(SQL, 구조적 쿼리 언어)
기본 키: 테이블의 레코드를 고유하게 식별하며 비워 둘 수 없고 반복할 수 없습니다.
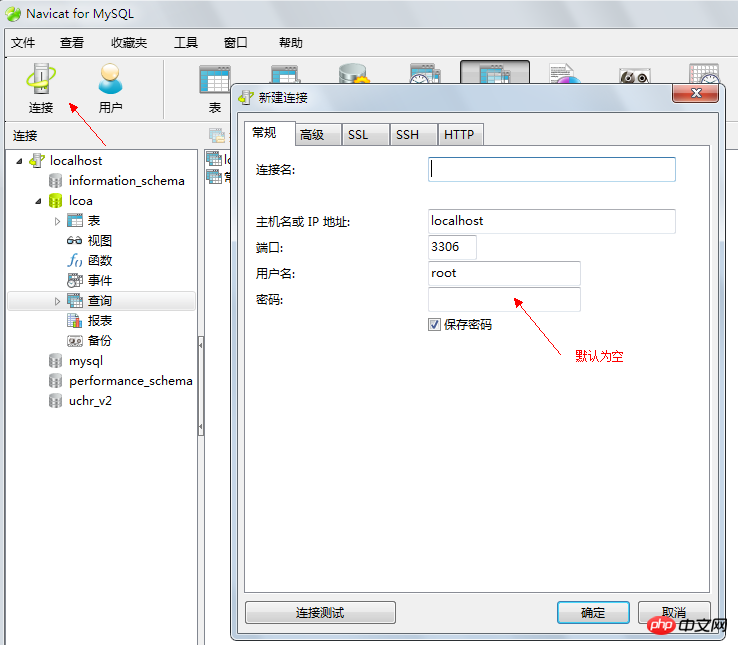
4.2. 데이터베이스에 로그인
*로컬 데이터베이스에 연결할 때 서비스를 시작해야 합니다
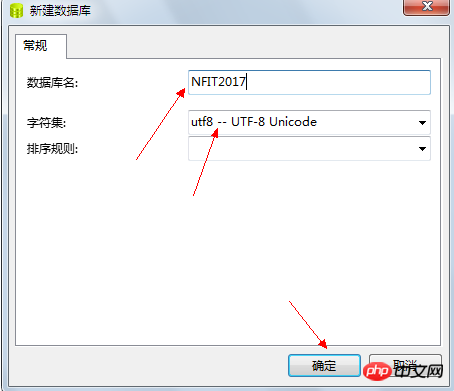
4.3. 데이터베이스 생성
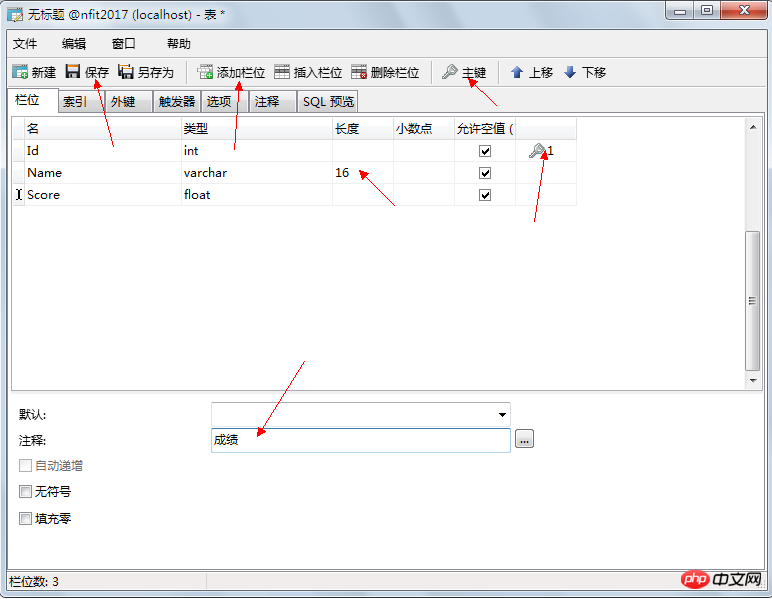
4.4. 테이블 생성
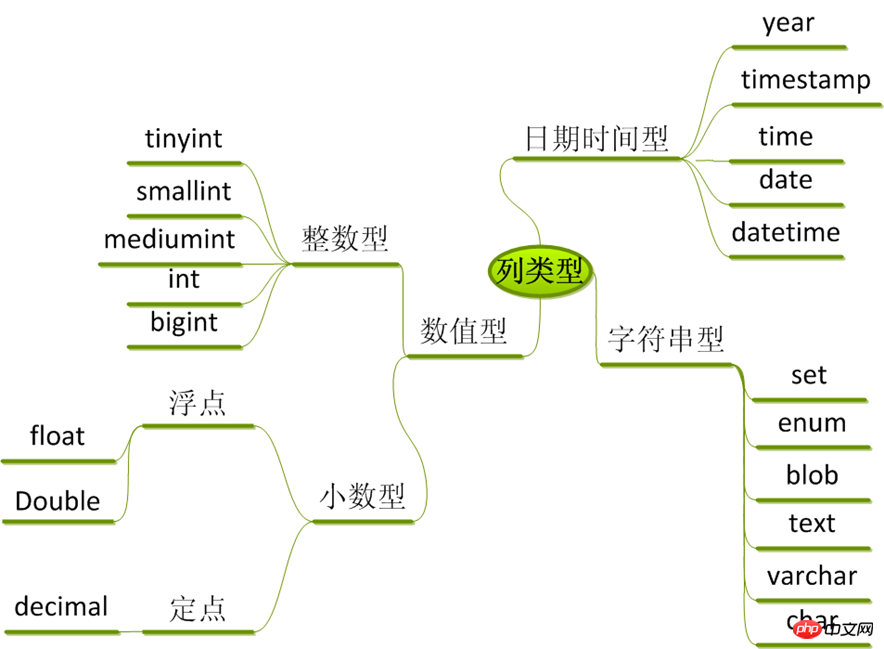
열 유형:
숫자 유형
정수:tinyint,smallint,mediumint,int,bigint
부동 소수점: float, double, real,decimal
날짜 및 시간: 날짜, 시간, 날짜/시간, 타임스탬프, 연도
문자열 유형
문자열: char, varchar
텍스트:tinytext, text,mediumtext,longtext
바이너리(사진, 음악 등을 저장하는 데 사용할 수 있음):tinyblob, blob,mediumblob,longblob
열 제약 조건:
그림 4: 데이터베이스 열 제약 조건
4.5. 관리자료
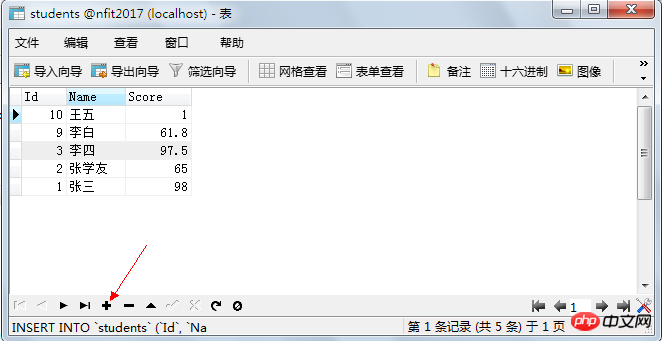
4.5.1. 데이터 추가
새로 생성된 테이블 이름을 더블클릭하면 테이블이 열리고 데이터가 추가됩니다.
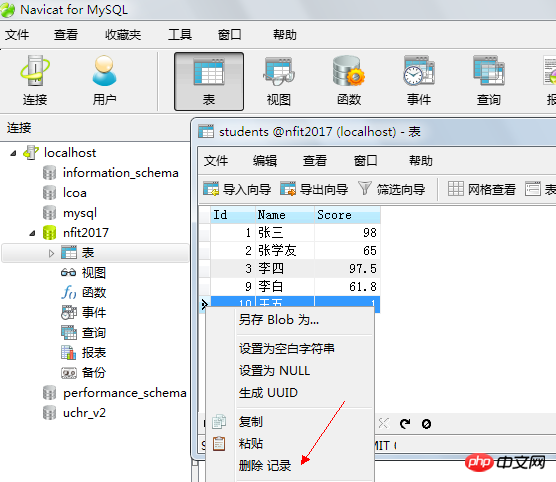
4.5.2. 데이터 삭제
4.5.3. 테이블 구조 수정
기존 테이블에 열을 추가하려면 테이블 구조를 수정하면 됩니다.
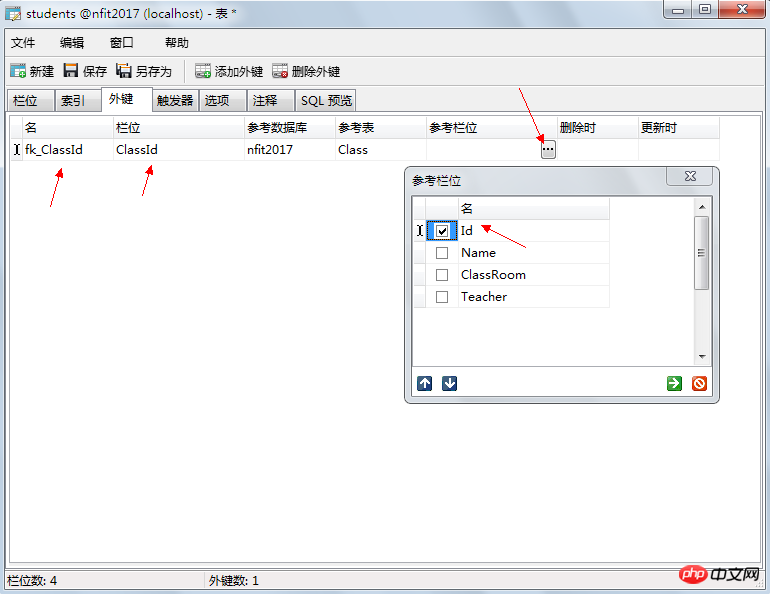
4.5.4. 외래 키
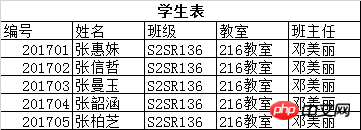
위의 학생 테이블에 몇 가지 문제가 있습니다.
a) 수정이 쉽지 않습니다. 예를 들어 교실을 305번 교실로 변경하면 학생 각자가 수정해야 합니다
b) 데이터 중복성, 대량의 중복 데이터
다음 그림과 같이 테이블을 2개로 분할하고 분해한 후 문제를 해결합니다.
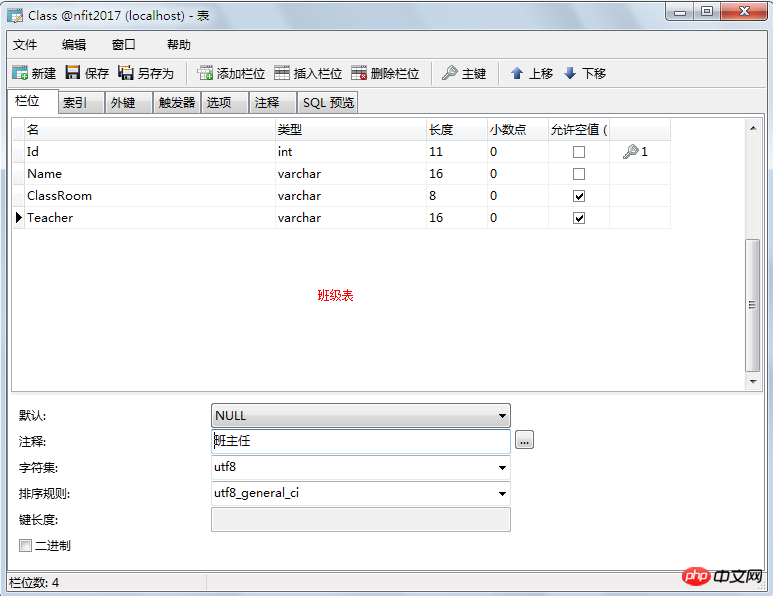
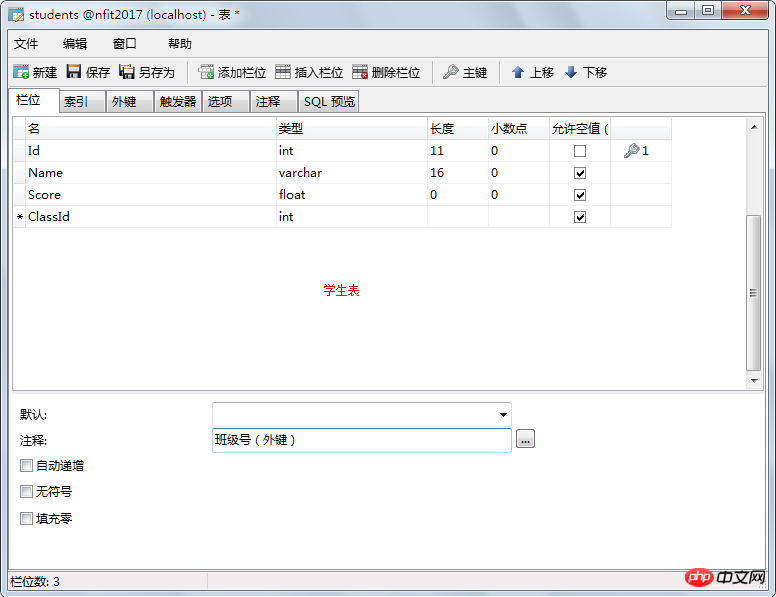
여기서 클래스 번호는 외래 키이므로 비어 있을 수 있지만 비어 있지 않은 경우 해당 값이 참조 테이블에 존재해야 합니다. 학생 테이블의 숫자가 기본 키인 경우 여기에서 반복하면 안 됩니다. 외래 키는 반복될 수 있으며 비워두는 것이 허용됩니다.
외래 키 추가:
수업 일정:
학생 테이블:
외래 키 추가:
삭제 및 업데이트 시 계단식 업데이트 및 삭제가 가능합니다. 업데이트가 CASCADE로 설정되면 기본 키 변경 사항과 기본 키를 참조하는 테이블도 함께 변경됩니다. 삭제가 CASCADE로 설정되면 기본 키 테이블이 변경됩니다. 삭제되고 참조된 모든 기록이 삭제됩니다.
4.6.컴퓨터 실습
1. HR이라는 데이터베이스를 새로 생성하고, HR 데이터베이스에 EMP 테이블을 추가해 주세요. EMP 테이블의 테이블 구조는 다음과 같습니다.
EMP 테이블, 직원 정보 No. | 이름 | 유형 | 설명 |
1 |
엠프노 |
정수 |
사원번호, 기본키, 자동증가 |
2 |
에네임 |
VARCHAR(10) |
공백이 아닌 10자로 구성된 직원 이름, 고유 키 |
3 |
직업 |
VARCHAR(9) |
직원 직위 |
4 |
MGR |
정수 |
해당 직원에 해당하는 리더번호는 직원이므로 비워둘 수 있습니다. (이 열은 삭제될 수 있습니다.) |
5 |
채용 날짜 |
타임스탬프 |
직원 입사일은 현재일로 기본 설정됩니다. |
6 |
살 |
숫자(7,2) |
기본급은 소수점 이하 2자리와 정수 5자리로 총 7자리 |
7 |
COMM |
숫자(7,2) |
보너스, 커미션 |
8 |
부서번호 |
정수 |
직원의 부서 번호, 선택 사항, 외래 키 fk_deptno |
9 |
상세정보 |
문자 |
비고, 비워둘 수 있음 |
부서, 부서 테이블 № | 名称 | 类型 | 描述 |
1 |
DeptNO |
int |
部门的编号,主键,自动增长 |
2 |
DNAME |
VARCHAR(10) |
部门名,由50位字符所组成,不为空,唯一键 |
3 |
DTel |
VARCHAR(10) |
电话,可空 |
<🎜>°<🎜><🎜><🎜>< 🎜>이름<🎜><🎜><🎜><🎜>유형<🎜><🎜><🎜><🎜>설명 <🎜><🎜><🎜><🎜><🎜><🎜>
1 <🎜><🎜><🎜><🎜>
부서번호 <🎜><🎜><🎜><🎜>
정수 <🎜><🎜><🎜><🎜>
부서번호, 기본키, 자동증가 <🎜><🎜><🎜><🎜><🎜><🎜>
2 <🎜><🎜><🎜><🎜>
D이름 <🎜><🎜><🎜><🎜>
VARCHAR(10) <🎜><🎜><🎜><🎜>
부서명, 50자로 구성, 비어있지 않음, 고유키 <🎜><🎜><🎜><🎜><🎜><🎜>
3 <🎜><🎜><🎜><🎜>
DT텔 <🎜><🎜><🎜><🎜>
VARCHAR(10) <🎜><🎜><🎜><🎜>
전화번호, 사용 가능 <🎜><🎜><🎜><🎜><🎜>
2. 위의 테이블 구조를 바탕으로 테이블 생성을 완료합니다. 테이블 이름은 emp 입니다.
3. 테이블에 5개 이상의 데이터 추가
4. 다음 쿼리 요구 사항을 완료하세요
4.1 전체 직원 정보 조회
4.2 급여가 2000~5000 사이인 모든 사원의 이름, 직위, 급여를 쿼리
4.3 성이 "Zhang"인 모든 직원을 쿼리
4.4 2014년부터 2015년까지 입사한 직원의 급여 내림차순으로 쿼리
4.5.일반적으로 임금을 20% 인상
4.6. 급여가 3,000위안 미만인 직원에 대한 보너스를 급여의 2.8배로 수정
4.7. 번호가 5번이거나 성이 "Wang"인 직원을 삭제합니다.
5. SQL을 사용하여 MySQL 데이터베이스에 액세스
5.1. 데이터 추가
insert 문을 사용하면 하나 이상의 데이터 행을 데이터베이스 테이블에 삽입할 수 있습니다. 사용되는 일반적인 형식은 다음과 같습니다.
테이블 이름(필드 목록)에 값(값 목록) 삽입;
insert [into] 테이블 이름 [(열 이름 1, 열 이름 2, 열 이름 3, ...)] 값 (값 1, 값 2, 값 3, ...);
학생 값에 삽입(NULL, "Zhang San", "Male", 20, "18889009876");
때로는 데이터의 일부만 삽입해야 하거나 열 순서가 아닌 삽입이 필요한 경우 다음 형식을 사용하여 삽입할 수 있습니다.
학생(이름, 성별, 나이) 값에 삽입("lee思", "女", 21);
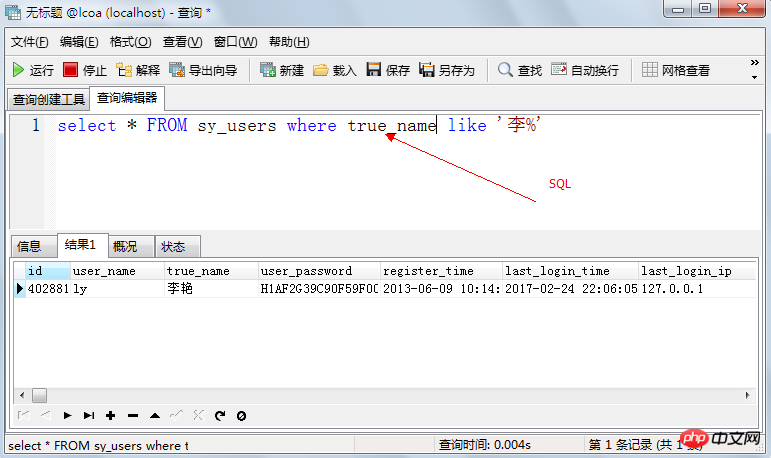
5.2. 데이터 쿼리
select 문은 특정 쿼리 규칙에 따라 데이터베이스에서 데이터를 가져오는 데 자주 사용됩니다.
테이블 이름에서 필드 이름 선택 [쿼리 조건];
학생 테이블의 모든 정보를 쿼리합니다. 학생 중에서 *를 선택합니다.
학생 테이블의 모든 이름과 나이 정보 쿼리: 학생의 이름, 나이 선택;
와일드카드 *를 사용하여 테이블의 모든 내용을 쿼리할 수도 있습니다. 명령문: select * from Students;
5.2.1. 표현식 및 조건부 쿼리
그림 5: 데이터베이스 연산자
where 키워드는 쿼리 조건을 지정하는 데 사용됩니다. 사용 형식은 테이블 이름에서 열 이름을 선택합니다. where 조건;
예를 들어 여성 성별에 대한 모든 정보를 쿼리하는 경우 쿼리 문을 입력합니다. select * from Students where sex="female";
where 절은 이름이 값과 동일한 "열 이름 = 값"의 쿼리 형식을 지원할 뿐만 아니라 =, >, <, >=, < != 및 일부 확장 연산자는 null, in, like 등이 [아닙니다]. 또는 및 및를 사용하여 쿼리 조건에 대해 결합된 쿼리를 수행할 수도 있습니다. 또한 여기서는 소개하지 않는 고급 조건 쿼리 방법도 나중에 배우게 됩니다.
예:
21세 이상 모든 사람의 정보 쿼리: 21세 이상인 학생 중에서 *를 선택;
이름에 "王"이라는 단어가 포함된 모든 사람의 정보를 쿼리합니다. 이름이 "%王%"와 같은 학생 중에서 *를 선택합니다.
id가 5보다 작고 나이가 20보다 큰 모든 사람의 정보를 쿼리합니다. id<5 and age>20; 인 학생 중에서 *를 선택합니다.
5.2.2. 집계 함수
그림 6: 공통 그룹 함수
5.3. 데이터 삭제
테이블 이름에서 삭제 [삭제 조건];
테이블의 모든 데이터 삭제: 학생에게서 삭제;
ID가 10인 행 삭제: ID=10; 인 학생에서 삭제
88세 미만 학생의 모든 데이터 삭제: <88; 인 학생에서 삭제
5.4. 데이터 업데이트
업데이트 문을 사용하여 테이블의 데이터를 수정할 수 있습니다. 기본 사용 형식은 입니다.
업데이트 테이블 이름 세트 열 이름 = 업데이트 조건이 있는 새 값;
업데이트 테이블 이름 설정 필드=값 목록 업데이트 조건
사용 예:
ID가 5인 휴대폰 번호를 기본 "-"로 변경: 학생이 tel=default where id=5; 로 설정하도록 업데이트합니다.
모든 사람의 나이를 1씩 늘립니다. 학생이 나이=나이+1로 설정되도록 업데이트합니다.
휴대폰 번호 13723887766의 이름을 "Zhang Guo"로 변경하고 나이를 19로 변경: 학생 세트 이름="Zhang Guo", age=19 where tel="13723887766″; 업데이트
5.5. 테이블 수정
alter table 문은 테이블 생성 후 수정하는 데 사용됩니다. 기본 사용법은 다음과 같습니다.
5.5.1. 열 추가
기본 형식: 테이블 테이블 이름 추가 컬럼 이름 컬럼 데이터 유형 [삽입 위치 뒤];
예:
테이블 끝에 열 주소를 추가합니다. alter table Students 추가 주소 char(60);
나이라는 열 뒤에 생일 열 삽입: 테이블 변경 학생은 나이 뒤에 생일 날짜를 추가합니다.
5.5.2. 열 수정
기본 형식: 테이블 변경 테이블 이름 변경 열 이름 열 새 이름 새 데이터 유형;
예:
테이블 전화 열의 이름을 전화로 바꿉니다. 테이블 학생 변경 전화 전화 문자(12) 기본값 "-";
name 열의 데이터 유형을 char(9)로 변경: alter table Students 변경 이름 name char(9) not null;
5.5.3、删除列
基本形式: alter table 表名 drop 列名称;
示例:
删除 age 列: alter table students drop age;
5.5.4、重命名表
基本形式: alter table 表名 rename 新表名;
示例:
重命名 students 表为temp: alter table students rename temp;
5.5.5、删除表
基本形式: drop table 表名;
示例: 删除students表: drop table students;
5.5.6、删除数据库
基本形式: drop database 数据库名;
示例: 删除lcoa数据库: drop database lcoa;
5.5.7、一千行MySQL笔记/* 启动MySQL */
net start mysql
/* 连接与断开服务器 */
mysql -h 地址 -P 端口 -u 用户名 -p 密码
/* 跳过权限验证登录MySQL */
mysqld --skip-grant-tables
-- 修改root密码
密码加密函数password()
update mysql.user set password=password('root');
SHOW PROCESSLIST -- 显示哪些线程正在运行
SHOW VARIABLES --
/* 数据库操作 */ ------------------
-- 查看当前数据库
select database();
-- 显示当前时间、用户名、数据库版本
select now(), user(), version();
-- 创建库
create database[ if not exists] 数据库名 数据库选项
数据库选项:
CHARACTER SET charset_name
COLLATE collation_name
-- 查看已有库
show databases[ like 'pattern']
-- 查看当前库信息
show create database 数据库名
-- 修改库的选项信息
alter database 库名 选项信息
-- 删除库
drop database[ if exists] 数据库名
同时删除该数据库相关的目录及其目录内容
/* 表的操作 */ ------------------
-- 创建表
create [temporary] table[ if not exists] [库名.]表名 ( 表的结构定义 )[ 表选项]
每个字段必须有数据类型
最后一个字段后不能有逗号
temporary 临时表,会话结束时表自动消失
对于字段的定义:
字段名 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
-- 表选项
-- 字符集
CHARSET = charset_name
如果表没有设定,则使用数据库字符集
-- 存储引擎
ENGINE = engine_name
表在管理数据时采用的不同的数据结构,结构不同会导致处理方式、提供的特性操作等不同
常见的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
不同的引擎在保存表的结构和数据时采用不同的方式
MyISAM表文件含义:.frm表定义,.MYD表数据,.MYI表索引
InnoDB表文件含义:.frm表定义,表空间数据和日志文件
SHOW ENGINES -- 显示存储引擎的状态信息
SHOW ENGINE 引擎名 {LOGS|STATUS} -- 显示存储引擎的日志或状态信息
-- 数据文件目录
DATA DIRECTORY = '目录'
-- 索引文件目录
INDEX DIRECTORY = '目录'
-- 表注释
COMMENT = 'string'
-- 分区选项
PARTITION BY ... (详细见手册)
-- 查看所有表
SHOW TABLES[ LIKE 'pattern']
SHOW TABLES FROM 表名
-- 查看表机构
SHOW CREATE TABLE 表名 (信息更详细)
DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN']
SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
-- 修改表
-- 修改表本身的选项
ALTER TABLE 表名 表的选项
EG: ALTER TABLE 表名 ENGINE=MYISAM;
-- 对表进行重命名
RENAME TABLE 原表名 TO 新表名
RENAME TABLE 原表名 TO 库名.表名 (可将表移动到另一个数据库)
-- RENAME可以交换两个表名
-- 修改表的字段机构
ALTER TABLE 表名 操作名
-- 操作名
ADD[ COLUMN] 字段名 -- 增加字段
AFTER 字段名 -- 表示增加在该字段名后面
FIRST -- 表示增加在第一个
ADD PRIMARY KEY(字段名) -- 创建主键
ADD UNIQUE [索引名] (字段名)-- 创建唯一索引
ADD INDEX [索引名] (字段名) -- 创建普通索引
ADD
DROP[ COLUMN] 字段名 -- 删除字段
MODIFY[ COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上)
CHANGE[ COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改
DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)
DROP INDEX 索引名 -- 删除索引
DROP FOREIGN KEY 外键 -- 删除外键
-- 删除表
DROP TABLE[ IF EXISTS] 表名 ...
-- 清空表数据
TRUNCATE [TABLE] 表名
-- 复制表结构
CREATE TABLE 表名 LIKE 要复制的表名
-- 复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
-- 检查表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
-- 优化表
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
-- 修复表
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
-- 分析表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
/* 数据操作 */ ------------------
-- 增
INSERT [INTO] 表名 [(字段列表)] VALUES (值列表)[, (值列表), ...]
-- 如果要插入的值列表包含所有字段并且顺序一致,则可以省略字段列表。
-- 可同时插入多条数据记录!
REPLACE 与 INSERT 完全一样,可互换。
INSERT [INTO] 表名 SET 字段名=值[, 字段名=值, ...]
-- 查
SELECT 字段列表 FROM 表名[ 其他子句]
-- 可来自多个表的多个字段
-- 其他子句可以不使用
-- 字段列表可以用*代替,表示所有字段
-- 删
DELETE FROM 表名[ 删除条件子句]
没有条件子句,则会删除全部
-- 改
UPDATE 表名 SET 字段名=新值[, 字段名=新值] [更新条件]
/* 字符集编码 */ ------------------
-- MySQL、数据库、表、字段均可设置编码
-- 数据编码与客户端编码不需一致
SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集编码项
character_set_client 客户端向服务器发送数据时使用的编码
character_set_results 服务器端将结果返回给客户端所使用的编码
character_set_connection 连接层编码
SET 变量名 = 变量值
set character_set_client = gbk;
set character_set_results = gbk;
set character_set_connection = gbk;
SET NAMES GBK; -- 相当于完成以上三个设置
-- 校对集
校对集用以排序
SHOW CHARACTER SET [LIKE 'pattern']/SHOW CHARSET [LIKE 'pattern'] 查看所有字符集
SHOW COLLATION [LIKE 'pattern'] 查看所有校对集
charset 字符集编码 设置字符集编码
collate 校对集编码 设置校对集编码
/* 数据类型(列类型) */ ------------------
1. 数值类型
-- a. 整型 ----------
类型 字节 范围(有符号位)
tinyint 1字节 -128 ~ 127 无符号位:0 ~ 255
smallint 2字节 -32768 ~ 32767
mediumint 3字节 -8388608 ~ 8388607
int 4字节
bigint 8字节
int(M) M表示总位数
- 默认存在符号位,unsigned 属性修改
- 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改
例:int(5) 插入一个数'123',补填后为'00123'
- 在满足要求的情况下,越小越好。
- 1表示bool值真,0表示bool值假。MySQL没有布尔类型,通过整型0和1表示。常用tinyint(1)表示布尔型。
-- b. 浮点型 ----------
类型 字节 范围
float(单精度) 4字节
double(双精度) 8字节
浮点型既支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。
不同于整型,前后均会补填0.
定义浮点型时,需指定总位数和小数位数。
float(M, D) double(M, D)
M表示总位数,D表示小数位数。
M和D的大小会决定浮点数的范围。不同于整型的固定范围。
M既表示总位数(不包括小数点和正负号),也表示显示宽度(所有显示符号均包括)。
支持科学计数法表示。
浮点数表示近似值。
-- c. 定点数 ----------
decimal -- 可变长度
decimal(M, D) M也表示总位数,D表示小数位数。
保存一个精确的数值,不会发生数据的改变,不同于浮点数的四舍五入。
将浮点数转换为字符串来保存,每9位数字保存为4个字节。
2. 字符串类型
-- a. char, varchar ----------
char 定长字符串,速度快,但浪费空间
varchar 变长字符串,速度慢,但节省空间
M表示能存储的最大长度,此长度是字符数,非字节数。
不同的编码,所占用的空间不同。
char,最多255个字符,与编码无关。
varchar,最多65535字符,与编码有关。
一条有效记录最大不能超过65535个字节。
utf8 最大为21844个字符,gbk 最大为32766个字符,latin1 最大为65532个字符
varchar 是变长的,需要利用存储空间保存 varchar 的长度,如果数据小于255个字节,则采用一个字节来保存长度,反之需要两个字节来保存。
varchar 的最大有效长度由最大行大小和使用的字符集确定。
最大有效长度是65532字节,因为在varchar存字符串时,第一个字节是空的,不存在任何数据,然后还需两个字节来存放字符串的长度,所以有效长度是64432-1-2=65532字节。
例:若一个表定义为 CREATE TABLE tb(c1 int, c2 char(30), c3 varchar(N)) charset=utf8; 问N的最大值是多少? 答:(65535-1-2-4-30*3)/3
-- b. blob, text ----------
blob 二进制字符串(字节字符串)
tinyblob, blob, mediumblob, longblob
text 非二进制字符串(字符字符串)
tinytext, text, mediumtext, longtext
text 在定义时,不需要定义长度,也不会计算总长度。
text 类型在定义时,不可给default值
-- c. binary, varbinary ----------
类似于char和varchar,用于保存二进制字符串,也就是保存字节字符串而非字符字符串。
char, varchar, text 对应 binary, varbinary, blob.
3. 日期时间类型
一般用整型保存时间戳,因为PHP可以很方便的将时间戳进行格式化。
datetime 8字节 日期及时间 1000-01-01 00:00:00 到 9999-12-31 23:59:59
date 3字节 日期 1000-01-01 到 9999-12-31
timestamp 4字节 时间戳 19700101000000 到 2038-01-19 03:14:07
time 3字节 时间 -838:59:59 到 838:59:59
year 1字节 年份 1901 - 2155
datetime “YYYY-MM-DD hh:mm:ss”
timestamp “YY-MM-DD hh:mm:ss”
“YYYYMMDDhhmmss”
“YYMMDDhhmmss”
YYYYMMDDhhmmss
YYMMDDhhmmss
date “YYYY-MM-DD”
“YY-MM-DD”
“YYYYMMDD”
“YYMMDD”
YYYYMMDD
YYMMDD
time “hh:mm:ss”
“hhmmss”
hhmmss
year “YYYY”
“YY”
YYYY
YY
4. 枚举和集合
-- 枚举(enum) ----------
enum(val1, val2, val3...)
在已知的值中进行单选。最大数量为65535.
枚举值在保存时,以2个字节的整型(smallint)保存。每个枚举值,按保存的位置顺序,从1开始逐一递增。
表现为字符串类型,存储却是整型。
NULL值的索引是NULL。
空字符串错误值的索引值是0。
-- 集合(set) ----------
set(val1, val2, val3...)
create table tab ( gender set('男', '女', '无') );
insert into tab values ('男, 女');
最多可以有64个不同的成员。以bigint存储,共8个字节。采取位运算的形式。
当创建表时,SET成员值的尾部空格将自动被删除。
/* 选择类型 */
-- PHP角度
1. 功能满足
2. 存储空间尽量小,处理效率更高
3. 考虑兼容问题
-- IP存储 ----------
1. 只需存储,可用字符串
2. 如果需计算,查找等,可存储为4个字节的无符号int,即unsigned
1) PHP函数转换
ip2long可转换为整型,但会出现携带符号问题。需格式化为无符号的整型。
利用sprintf函数格式化字符串
sprintf("%u", ip2long('192.168.3.134'));
然后用long2ip将整型转回IP字符串
2) MySQL函数转换(无符号整型,UNSIGNED)
INET_ATON('127.0.0.1') 将IP转为整型
INET_NTOA(2130706433) 将整型转为IP
/* 列属性(列约束) */ ------------------
1. 主键
- 能唯一标识记录的字段,可以作为主键。
- 一个表只能有一个主键。
- 主键具有唯一性。
- 声明字段时,用 primary key 标识。
也可以在字段列表之后声明
例:create table tab ( id int, stu varchar(10), primary key (id));
- 主键字段的值不能为null。
- 主键可以由多个字段共同组成。此时需要在字段列表后声明的方法。
例:create table tab ( id int, stu varchar(10), age int, primary key (stu, age));
2. unique 唯一索引(唯一约束)
使得某字段的值也不能重复。
3. null 约束
null不是数据类型,是列的一个属性。
表示当前列是否可以为null,表示什么都没有。
null, 允许为空。默认。
not null, 不允许为空。
insert into tab values (null, 'val');
-- 此时表示将第一个字段的值设为null, 取决于该字段是否允许为null
4. default 默认值属性
当前字段的默认值。
insert into tab values (default, 'val'); -- 此时表示强制使用默认值。
create table tab ( add_time timestamp default current_timestamp );
-- 表示将当前时间的时间戳设为默认值。
current_date, current_time
5. auto_increment 自动增长约束
自动增长必须为索引(主键或unique)
只能存在一个字段为自动增长。
默认为1开始自动增长。可以通过表属性 auto_increment = x进行设置,或 alter table tbl auto_increment = x;
6. comment 注释
例:create table tab ( id int ) comment '注释内容';
7. foreign key 外键约束
用于限制主表与从表数据完整性。
alter table t1 add constraint `t1_t2_fk` foreign key (t1_id) references t2(id);
-- 将表t1的t1_id外键关联到表t2的id字段。
-- 每个外键都有一个名字,可以通过 constraint 指定
存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。
MySQL中,可以对InnoDB引擎使用外键约束:
语法:
foreign key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作]
此时需要检测一个从表的外键需要约束为主表的已存在的值。外键在没有关联的情况下,可以设置为null.前提是该外键列,没有not null。
可以不指定主表记录更改或更新时的动作,那么此时主表的操作被拒绝。
如果指定了 on update 或 on delete:在删除或更新时,有如下几个操作可以选择:
1. cascade,级联操作。主表数据被更新(主键值更新),从表也被更新(外键值更新)。主表记录被删除,从表相关记录也被删除。
2. set null,设置为null。主表数据被更新(主键值更新),从表的外键被设置为null。主表记录被删除,从表相关记录外键被设置成null。但注意,要求该外键列,没有not null属性约束。
3. restrict,拒绝父表删除和更新。
注意,外键只被InnoDB存储引擎所支持。其他引擎是不支持的。
/* 建表规范 */ ------------------
-- Normal Format, NF
- 每个表保存一个实体信息
- 每个具有一个ID字段作为主键
- ID主键 + 原子表
-- 1NF, 第一范式
字段不能再分,就满足第一范式。
-- 2NF, 第二范式
满足第一范式的前提下,不能出现部分依赖。
消除符合主键就可以避免部分依赖。增加单列关键字。
-- 3NF, 第三范式
满足第二范式的前提下,不能出现传递依赖。
某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
将一个实体信息的数据放在一个表内实现。
/* select */ ------------------
select [all|distinct] select_expr from -> where -> group by [合计函数] -> having -> order by -> limit
a. select_expr
-- 可以用 * 表示所有字段。
select * from tb;
-- 可以使用表达式(计算公式、函数调用、字段也是个表达式)
select stu, 29+25, now() from tb;
-- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。
- 使用 as 关键字,也可省略 as.
select stu+10 as add10 from tb;
b. from 子句
用于标识查询来源。
-- 可以为表起别名。使用as关键字。
select * from tb1 as tt, tb2 as bb;
-- from子句后,可以同时出现多个表。
-- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。
select * from tb1, tb2;
c. where 子句
-- 从from获得的数据源中进行筛选。
-- 整型1表示真,0表示假。
-- 表达式由运算符和运算数组成。
-- 运算数:变量(字段)、值、函数返回值
-- 运算符:
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
is/is not 加上ture/false/unknown,检验某个值的真假
<=>与<>功能相同,<=>可用于null比较
d. group by 子句, 分组子句
group by 字段/别名 [排序方式]
分组后会进行排序。升序:ASC,降序:DESC
以下[合计函数]需配合 group by 使用:
count 返回不同的非NULL值数目 count(*)、count(字段)
sum 求和
max 求最大值
min 求最小值
avg 求平均值
group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。
e. having 子句,条件子句
与 where 功能、用法相同,执行时机不同。
where 在开始时执行检测数据,对原数据进行过滤。
having 对筛选出的结果再次进行过滤。
having 字段必须是查询出来的,where 字段必须是数据表存在的。
where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。
where 不可以使用合计函数。一般需用合计函数才会用 having
SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。
f. order by 子句,排序子句
order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]...
升序:ASC,降序:DESC
支持多个字段的排序。
g. limit 子句,限制结果数量子句
仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。
limit 起始位置, 获取条数
省略第一个参数,表示从索引0开始。limit 获取条数
h. distinct, all 选项
distinct 去除重复记录
默认为 all, 全部记录
/* UNION */ ------------------
将多个select查询的结果组合成一个结果集合。
SELECT ... UNION [ALL|DISTINCT] SELECT ...
默认 DISTINCT 方式,即所有返回的行都是唯一的
建议,对每个SELECT查询加上小括号包裹。
ORDER BY 排序时,需加上 LIMIT 进行结合。
需要各select查询的字段数量一样。
每个select查询的字段列表(数量、类型)应一致,因为结果中的字段名以第一条select语句为准。
/* 子查询 */ ------------------
- 子查询需用括号包裹。
-- from型
from后要求是一个表,必须给子查询结果取个别名。
- 简化每个查询内的条件。
- from型需将结果生成一个临时表格,可用以原表的锁定的释放。
- 子查询返回一个表,表型子查询。
select * from (select * from tb where id>0) as subfrom where id>1;
-- where型
- 子查询返回一个值,标量子查询。
- 不需要给子查询取别名。
- where子查询内的表,不能直接用以更新。
select * from tb where money = (select max(money) from tb);
-- 列子查询
如果子查询结果返回的是一列。
使用 in 或 not in 完成查询
exists 和 not exists 条件
如果子查询返回数据,则返回1或0。常用于判断条件。
select column1 from t1 where exists (select * from t2);
-- 行子查询
查询条件是一个行。
select * from t1 where (id, gender) in (select id, gender from t2);
行构造符:(col1, col2, ...) 或 ROW(col1, col2, ...)
行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。
-- 特殊运算符
!= all() 相当于 not in
= some() 相当于 in。any 是 some 的别名
!= some() 不等同于 not in,不等于其中某一个。
all, some 可以配合其他运算符一起使用。
/* 连接查询(join) */ ------------------
将多个表的字段进行连接,可以指定连接条件。
-- 内连接(inner join)
- 默认就是内连接,可省略inner。
- 只有数据存在时才能发送连接。即连接结果不能出现空行。
on 表示连接条件。其条件表达式与where类似。也可以省略条件(表示条件永远为真)
也可用where表示连接条件。
还有 using, 但需字段名相同。 using(字段名)
-- 交叉连接 cross join
即,没有条件的内连接。
select * from tb1 cross join tb2;
-- 外连接(outer join)
- 如果数据不存在,也会出现在连接结果中。
-- 左外连接 left join
如果数据不存在,左表记录会出现,而右表为null填充
-- 右外连接 right join
如果数据不存在,右表记录会出现,而左表为null填充
-- 自然连接(natural join)
自动判断连接条件完成连接。
相当于省略了using,会自动查找相同字段名。
natural join
natural left join
natural right join
select info.id, info.name, info.stu_num, extra_info.hobby, extra_info.sex from info, extra_info where info.stu_num = extra_info.stu_id;
/* 导入导出 */ ------------------
select * into outfile 文件地址 [控制格式] from 表名; -- 导出表数据
load data [local] infile 文件地址 [replace|ignore] into table 表名 [控制格式]; -- 导入数据
生成的数据默认的分隔符是制表符
local未指定,则数据文件必须在服务器上
replace 和 ignore 关键词控制对现有的唯一键记录的重复的处理
-- 控制格式
fields 控制字段格式
默认:fields terminated by '\t' enclosed by '' escaped by '\\'
terminated by 'string' -- 终止
enclosed by 'char' -- 包裹
escaped by 'char' -- 转义
-- 示例:
SELECT a,b,a+b INTO OUTFILE '/tmp/result.text'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM test_table;
lines 控制行格式
默认:lines terminated by '\n'
terminated by 'string' -- 终止
/* insert */ ------------------
select语句获得的数据可以用insert插入。
可以省略对列的指定,要求 values () 括号内,提供给了按照列顺序出现的所有字段的值。
或者使用set语法。
insert into tbl_name set field=value,...;
可以一次性使用多个值,采用(), (), ();的形式。
insert into tbl_name values (), (), ();
可以在列值指定时,使用表达式。
insert into tbl_name values (field_value, 10+10, now());
可以使用一个特殊值 default,表示该列使用默认值。
insert into tbl_name values (field_value, default);
可以通过一个查询的结果,作为需要插入的值。
insert into tbl_name select ...;
可以指定在插入的值出现主键(或唯一索引)冲突时,更新其他非主键列的信息。
insert into tbl_name values/set/select on duplicate key update 字段=值, …;
/* delete */ ------------------
DELETE FROM tbl_name [WHERE where_definition] [ORDER BY ...] [LIMIT row_count]
按照条件删除
指定删除的最多记录数。Limit
可以通过排序条件删除。order by + limit
支持多表删除,使用类似连接语法。
delete from 需要删除数据多表1,表2 using 表连接操作 条件。
/* truncate */ ------------------
TRUNCATE [TABLE] tbl_name
清空数据
删除重建表
区别:
1,truncate 是删除表再创建,delete 是逐条删除
2,truncate 重置auto_increment的值。而delete不会
3,truncate 不知道删除了几条,而delete知道。
4,当被用于带分区的表时,truncate 会保留分区
/* 备份与还原 */ ------------------
备份,将数据的结构与表内数据保存起来。
利用 mysqldump 指令完成。
-- 导出
1. 导出一张表
mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql)
2. 导出多张表
mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql)
3. 导出所有表
mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql)
4. 导出一个库
mysqldump -u用户名 -p密码 -B 库名 > 文件名(D:/a.sql)
可以-w携带备份条件
-- 导入
1. 在登录mysql的情况下:
source 备份文件
2. 在不登录的情况下
mysql -u用户名 -p密码 库名 < 备份文件
/* 视图 */ ------------------
什么是视图:
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
视图具有表结构文件,但不存在数据文件。
对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。
视图是存储在数据库中的查询的sql语句,它主要出于两种原因:安全原因,视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。
-- 创建视图
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement
- 视图名必须唯一,同时不能与表重名。
- 视图可以使用select语句查询到的列名,也可以自己指定相应的列名。
- 可以指定视图执行的算法,通过ALGORITHM指定。
- column_list如果存在,则数目必须等于SELECT语句检索的列数
-- 查看结构
SHOW CREATE VIEW view_name
-- 删除视图
- 删除视图后,数据依然存在。
- 可同时删除多个视图。
DROP VIEW [IF EXISTS] view_name ...
-- 修改视图结构
- 一般不修改视图,因为不是所有的更新视图都会映射到表上。
ALTER VIEW view_name [(column_list)] AS select_statement
-- 视图作用
1. 简化业务逻辑
2. 对客户端隐藏真实的表结构
-- 视图算法(ALGORITHM)
MERGE 合并
将视图的查询语句,与外部查询需要先合并再执行!
TEMPTABLE 临时表
将视图执行完毕后,形成临时表,再做外层查询!
UNDEFINED 未定义(默认),指的是MySQL自主去选择相应的算法。
/* 事务(transaction) */ ------------------
事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
- 支持连续SQL的集体成功或集体撤销。
- 事务是数据库在数据晚自习方面的一个功能。
- 需要利用 InnoDB 或 BDB 存储引擎,对自动提交的特性支持完成。
- InnoDB被称为事务安全型引擎。
-- 事务开启
START TRANSACTION; 或者 BEGIN;
开启事务后,所有被执行的SQL语句均被认作当前事务内的SQL语句。
-- 事务提交
COMMIT;
-- 事务回滚
ROLLBACK;
如果部分操作发生问题,映射到事务开启前。
-- 事务的特性
1. 原子性(Atomicity)
事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2. 一致性(Consistency)
事务前后数据的完整性必须保持一致。
- 事务开始和结束时,外部数据一致
- 在整个事务过程中,操作是连续的
3. 隔离性(Isolation)
多个用户并发访问数据库时,一个用户的事务不能被其它用户的事物所干扰,多个并发事务之间的数据要相互隔离。
4. 持久性(Durability)
一个事务一旦被提交,它对数据库中的数据改变就是永久性的。
-- 事务的实现
1. 要求是事务支持的表类型
2. 执行一组相关的操作前开启事务
3. 整组操作完成后,都成功,则提交;如果存在失败,选择回滚,则会回到事务开始的备份点。
-- 事务的原理
利用InnoDB的自动提交(autocommit)特性完成。
普通的MySQL执行语句后,当前的数据提交操作均可被其他客户端可见。
而事务是暂时关闭“自动提交”机制,需要commit提交持久化数据操作。
-- 注意
1. 数据定义语言(DDL)语句不能被回滚,比如创建或取消数据库的语句,和创建、取消或更改表或存储的子程序的语句。
2. 事务不能被嵌套
-- 保存点
SAVEPOINT 保存点名称 -- 设置一个事务保存点
ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
RELEASE SAVEPOINT 保存点名称 -- 删除保存点
-- InnoDB自动提交特性设置
SET autocommit = 0|1; 0表示关闭自动提交,1表示开启自动提交。
- 如果关闭了,那普通操作的结果对其他客户端也不可见,需要commit提交后才能持久化数据操作。
- 也可以关闭自动提交来开启事务。但与START TRANSACTION不同的是,
SET autocommit是永久改变服务器的设置,直到下次再次修改该设置。(针对当前连接)
而START TRANSACTION记录开启前的状态,而一旦事务提交或回滚后就需要再次开启事务。(针对当前事务)
/* 锁表 */
表锁定只用于防止其它客户端进行不正当地读取和写入
MyISAM 支持表锁,InnoDB 支持行锁
-- 锁定
LOCK TABLES tbl_name [AS alias]
-- 解锁
UNLOCK TABLES
/* 触发器 */ ------------------
触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
监听:记录的增加、修改、删除。
-- 创建触发器
CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
参数:
trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。
trigger_event指明了激活触发程序的语句的类型
INSERT:将新行插入表时激活触发程序
UPDATE:更改某一行时激活触发程序
DELETE:从表中删除某一行时激活触发程序
tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。
trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构
-- 删除
DROP TRIGGER [schema_name.]trigger_name
可以使用old和new代替旧的和新的数据
更新操作,更新前是old,更新后是new.
删除操作,只有old.
增加操作,只有new.
-- 注意
1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。
-- 字符连接函数
concat(str1[, str2,...])
-- 分支语句
if 条件 then
执行语句
elseif 条件 then
执行语句
else
执行语句
end if;
-- 修改最外层语句结束符
delimiter 自定义结束符号
SQL语句
自定义结束符号
delimiter ; -- 修改回原来的分号
-- 语句块包裹
begin
语句块
end
-- 特殊的执行
1. 只要添加记录,就会触发程序。
2. Insert into on duplicate key update 语法会触发:
如果没有重复记录,会触发 before insert, after insert;
如果有重复记录并更新,会触发 before insert, before update, after update;
如果有重复记录但是没有发生更新,则触发 before insert, before update
3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
/* SQL编程 */ ------------------
--// 局部变量 ----------
-- 变量声明
declare var_name[,...] type [default value]
这个语句被用来声明局部变量。要给变量提供一个默认值,请包含一个default子句。值可以被指定为一个表达式,不需要为一个常数。如果没有default子句,初始值为null。
-- 赋值
使用 set 和 select into 语句为变量赋值。
- 注意:在函数内是可以使用全局变量(用户自定义的变量)
--// 全局变量 ----------
-- 定义、赋值
set 语句可以定义并为变量赋值。
set @var = value;
也可以使用select into语句为变量初始化并赋值。这样要求select语句只能返回一行,但是可以是多个字段,就意味着同时为多个变量进行赋值,变量的数量需要与查询的列数一致。
还可以把赋值语句看作一个表达式,通过select执行完成。此时为了避免=被当作关系运算符看待,使用:=代替。(set语句可以使用= 和 :=)。
select @var:=20;
select @v1:=id, @v2=name from t1 limit 1;
select * from tbl_name where @var:=30;
select into 可以将表中查询获得的数据赋给变量。
-| select max(height) into @max_height from tb;
-- 自定义变量名
为了避免select语句中,用户自定义的变量与系统标识符(通常是字段名)冲突,用户自定义变量在变量名前使用@作为开始符号。
@var=10;
- 变量被定义后,在整个会话周期都有效(登录到退出)
--// 控制结构 ----------
-- if语句
if search_condition then
statement_list
[elseif search_condition then
statement_list]
...
[else
statement_list]
end if;
-- case语句
CASE value WHEN [compare-value] THEN result
[WHEN [compare-value] THEN result ...]
[ELSE result]
END
-- while循环
[begin_label:] while search_condition do
statement_list
end while [end_label];
- 如果需要在循环内提前终止 while循环,则需要使用标签;标签需要成对出现。
-- 退出循环
退出整个循环 leave
退出当前循环 iterate
通过退出的标签决定退出哪个循环
--// 内置函数 ----------
-- 数值函数
abs(x) -- 绝对值 abs(-10.9) = 10
format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46
ceil(x) -- 向上取整 ceil(10.1) = 11
floor(x) -- 向下取整 floor (10.1) = 10
round(x) -- 四舍五入去整
mod(m, n) -- m%n m mod n 求余 10%3=1
pi() -- 获得圆周率
pow(m, n) -- m^n
sqrt(x) -- 算术平方根
rand() -- 随机数
truncate(x, d) -- 截取d位小数
-- 时间日期函数
now(), current_timestamp(); -- 当前日期时间
current_date(); -- 当前日期
current_time(); -- 当前时间
date('yyyy-mm-dd hh:ii:ss'); -- 获取日期部分
time('yyyy-mm-dd hh:ii:ss'); -- 获取时间部分
date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化时间
unix_timestamp(); -- 获得unix时间戳
from_unixtime(); -- 从时间戳获得时间
-- 字符串函数
length(string) -- string长度,字节
char_length(string) -- string的字符个数
substring(str, position [,length]) -- 从str的position开始,取length个字符
replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_str
instr(string ,substring) -- 返回substring首次在string中出现的位置
concat(string [,...]) -- 连接字串
charset(str) -- 返回字串字符集
lcase(string) -- 转换成小写
left(string, length) -- 从string2中的左边起取length个字符
load_file(file_name) -- 从文件读取内容
locate(substring, string [,start_position]) -- 同instr,但可指定开始位置
lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为length
ltrim(string) -- 去除前端空格
repeat(string, count) -- 重复count次
rpad(string, length, pad) --在str后用pad补充,直到长度为length
rtrim(string) -- 去除后端空格
strcmp(string1 ,string2) -- 逐字符比较两字串大小
-- 流程函数
case when [condition] then result [when [condition] then result ...] [else result] end 多分支
if(expr1,expr2,expr3) 双分支。
-- 聚合函数
count()
sum();
max();
min();
avg();
group_concat()
-- 其他常用函数
md5();
default();
--// 存储函数,自定义函数 ----------
-- 新建
CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
函数体
- 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
- 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。
- 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
- 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
- 多条语句应该使用 begin...end 语句块包含。
- 一定要有 return 返回值语句。
-- 删除
DROP FUNCTION [IF EXISTS] function_name;
-- 查看
SHOW FUNCTION STATUS LIKE 'partten'
SHOW CREATE FUNCTION function_name;
-- 修改
ALTER FUNCTION function_name 函数选项
--// 存储过程,自定义功能 ----------
-- 定义
存储存储过程 是一段代码(过程),存储在数据库中的sql组成。
一个存储过程通常用于完成一段业务逻辑,例如报名,交班费,订单入库等。
而一个函数通常专注与某个功能,视为其他程序服务的,需要在其他语句中调用函数才可以,而存储过程不能被其他调用,是自己执行 通过call执行。
-- 创建
CREATE PROCEDURE sp_name (参数列表)
过程体
参数列表:不同于函数的参数列表,需要指明参数类型
IN,表示输入型
OUT,表示输出型
INOUT,表示混合型
注意,没有返回值。
/* 存储过程 */ ------------------
存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
调用:CALL 过程名
-- 注意
- 没有返回值。
- 只能单独调用,不可夹杂在其他语句中
-- 参数
IN|OUT|INOUT 参数名 数据类型
IN 输入:在调用过程中,将数据输入到过程体内部的参数
OUT 输出:在调用过程中,将过程体处理完的结果返回到客户端
INOUT 输入输出:既可输入,也可输出
-- 语法
CREATE PROCEDURE 过程名 (参数列表)
BEGIN
过程体
END
/* 用户和权限管理 */ ------------------
用户信息表:mysql.user
-- 刷新权限
FLUSH PRIVILEGES
-- 增加用户
CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 密码(字符串)
- 必须拥有mysql数据库的全局CREATE USER权限,或拥有INSERT权限。
- 只能创建用户,不能赋予权限。
- 用户名,注意引号:如 'user_name'@'192.168.1.1'
- 密码也需引号,纯数字密码也要加引号
- 要在纯文本中指定密码,需忽略PASSWORD关键词。要把密码指定为由PASSWORD()函数返回的混编值,需包含关键字PASSWORD
-- 重命名用户
RENAME USER old_user TO new_user
-- 设置密码
SET PASSWORD = PASSWORD('密码') -- 为当前用户设置密码
SET PASSWORD FOR 用户名 = PASSWORD('密码') -- 为指定用户设置密码
-- 删除用户
DROP USER 用户名
-- 分配权限/添加用户
GRANT 权限列表 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] 'password']
- all privileges 表示所有权限
- *.* 表示所有库的所有表
- 库名.表名 表示某库下面的某表
-- 查看权限
SHOW GRANTS FOR 用户名
-- 查看当前用户权限
SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
-- 撤消权限
REVOKE 权限列表 ON 表名 FROM 用户名
REVOKE ALL PRIVILEGES, GRANT OPTION FROM 用户名 -- 撤销所有权限
-- 权限层级
-- 要使用GRANT或REVOKE,您必须拥有GRANT OPTION权限,并且您必须用于您正在授予或撤销的权限。
全局层级:全局权限适用于一个给定服务器中的所有数据库,mysql.user
GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤销全局权限。
数据库层级:数据库权限适用于一个给定数据库中的所有目标,mysql.db, mysql.host
GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤销数据库权限。
表层级:表权限适用于一个给定表中的所有列,mysql.talbes_priv
GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限。
列层级:列权限适用于一个给定表中的单一列,mysql.columns_priv
当使用REVOKE时,您必须指定与被授权列相同的列。
-- 权限列表
ALL [PRIVILEGES] -- 设置除GRANT OPTION之外的所有简单权限
ALTER -- 允许使用ALTER TABLE
ALTER ROUTINE -- 更改或取消已存储的子程序
CREATE -- 允许使用CREATE TABLE
CREATE ROUTINE -- 创建已存储的子程序
CREATE TEMPORARY TABLES -- 允许使用CREATE TEMPORARY TABLE
CREATE USER -- 允许使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。
CREATE VIEW -- 允许使用CREATE VIEW
DELETE -- 允许使用DELETE
DROP -- 允许使用DROP TABLE
EXECUTE -- 允许用户运行已存储的子程序
FILE -- 允许使用SELECT...INTO OUTFILE和LOAD DATA INFILE
INDEX -- 允许使用CREATE INDEX和DROP INDEX
INSERT -- 允许使用INSERT
LOCK TABLES -- 允许对您拥有SELECT权限的表使用LOCK TABLES
PROCESS -- 允许使用SHOW FULL PROCESSLIST
REFERENCES -- 未被实施
RELOAD -- 允许使用FLUSH
REPLICATION CLIENT -- 允许用户询问从属服务器或主服务器的地址
REPLICATION SLAVE -- 用于复制型从属服务器(从主服务器中读取二进制日志事件)
SELECT -- 允许使用SELECT
SHOW DATABASES -- 显示所有数据库
SHOW VIEW -- 允许使用SHOW CREATE VIEW
SHUTDOWN -- 允许使用mysqladmin shutdown
SUPER -- 允许使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL语句,mysqladmin debug命令;允许您连接(一次),即使已达到max_connections。
UPDATE -- 允许使用UPDATE
USAGE -- “无权限”的同义词
GRANT OPTION -- 允许授予权限
/* 表维护 */
-- 分析和存储表的关键字分布
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
-- 检查一个或多个表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
-- 整理数据文件的碎片
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
/* 杂项 */ ------------------
1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
2. 每个库目录存在一个保存当前数据库的选项文件db.opt。
3. 注释:
单行注释 # 注释内容
多行注释 /* 注释内容 */
单行注释 -- 注释内容 (标准SQL注释风格,要求双破折号后加一空格符(空格、TAB、换行等))
4. 模式通配符:
_ 任意单个字符
% 任意多个字符,甚至包括零字符
单引号需要进行转义 \'
5. CMD命令行内的语句结束符可以为 ";", "\G", "\g",仅影响显示结果。其他地方还是用分号结束。delimiter 可修改当前对话的语句结束符。
6. SQL对大小写不敏感
7. 清除已有语句:\c로그인 후 복사
5.5.8、常用的SQL/*==============================================================*/
/* DBMS name: MySQL 5.0 */
/* Created on: 2017/3/5 10:29:05 */
/*==============================================================*/
drop table if exists Address;
drop table if exists ArticleComment;
drop table if exists ArticleType;
drop table if exists Articles;
drop table if exists DictSub;
drop table if exists DictTop;
drop table if exists OrderPdt;
drop table if exists Orders;
drop table if exists ProductComment;
drop table if exists Products;
drop table if exists Users;
/*==============================================================*/
/* Table: Address */
/*==============================================================*/
create table Address
(
`AddressId` int not null auto_increment comment '收货地址编号',
`UserId` int not null comment '用户编号',
`Province` varchar(50) not null comment '省',
`City` varchar(50) not null comment '市',
`County` varchar(50) not null comment '县/区',
`Street` varchar(300) not null comment '详细地址',
`RevName` varchar(30) not null comment '收货人姓名',
`PostCode` varchar(20) comment '邮政编码',
`Mobile` varchar(50) not null comment '手机',
`Phone` varchar(50) comment '电话',
`IsDefault` bool comment '是否为默认地址',
primary key (AddressId)
);
alter table Address comment '收货地址';
/*==============================================================*/
/* Table: ArticleComment */
/*==============================================================*/
create table ArticleComment
(
`ArticleCommentId` int not null auto_increment comment '文章评论编号',
`ArticleId` int not null comment '文章编号',
`UserId` int not null comment '用户编号',
`ArticleCommentContent` varchar(4000) not null comment '文章评论内容',
`ArticleCommentDate` timestamp default CURRENT_TIMESTAMP comment '文章评论时间',
`ArticleCommentState` int default 1 comment '状态',
`ArticleRemark` int comment '打分',
`ArticleCommentReserver1` varchar(4000) comment '备用1',
`ArticleCommentReserver2` varchar(4000) comment '备用2',
primary key (ArticleCommentId)
);
alter table ArticleComment comment '文章评论';
/*==============================================================*/
/* Table: ArticleType */
/*==============================================================*/
create table ArticleType
(
`ArticleTypeId` int not null auto_increment comment '文章栏目编号',
`ArticleTypeName` varchar(200) comment '文章栏目名称',
`ArticleTypeState` int default 1 comment '状态',
`ArticleTypeDesc` varchar(4000) comment '文章栏目描述',
`ArticleTypePicture` varchar(400) comment '文章栏目图片',
`ArticleTypeReserve1` varchar(4000) comment '备用1',
`ArticleTypeReserve2` varchar(4000) comment '备用2',
primary key (ArticleTypeId)
);
alter table ArticleType comment '文章栏目';
/*==============================================================*/
/* Table: Articles */
/*==============================================================*/
create table Articles
(
`ArticleId` int not null auto_increment comment '文章编号',
`ArticleTypeId` int not null comment '文章栏目编号',
`ArticleTitle` varchar(400) not null comment '文章标题',
`ArticleContent` text comment '文章内容',
`ArticleDate` timestamp default CURRENT_TIMESTAMP comment '文章发布时间',
`ArticleAuthor` varchar(200) comment '文章发布者',
`ArticleFileName` varchar(100) comment '静态文件名',
`ArticleThumbNail` varchar(200) comment '缩略图片',
`ArticleAddition` varchar(200) comment '附件名称',
`ArticleLevel` int comment '显示的优先级',
`ArticleIsAllowComment` integer default 1 comment '是否允许评论',
`ArticleState` int default 1 comment '状态',
`ArticleHotCount` int comment '点击次数',
`ArticleReserve1` varchar(4000) comment '备用1',
`ArticleReserve2` varchar(4000) comment '备用2',
`ArticleReserve3` numeric(8,0) comment '备用3',
primary key (ArticleId)
);
alter table Articles comment '文章';
/*==============================================================*/
/* Table: DictSub */
/*==============================================================*/
create table DictSub
(
`SubId` int not null auto_increment comment '子项编号',
`DictId` int not null comment '字典编号',
`SubName` varchar(200) not null comment '子项名称',
`SubDesc` varchar(4000) comment '子项描述',
`SubReserve1` varchar(4000) comment '保留备用1',
primary key (SubId)
);
alter table DictSub comment '字典子项';
/*==============================================================*/
/* Table: DictTop */
/*==============================================================*/
create table DictTop
(
`DictId` int not null auto_increment comment '字典编号',
`DictName` varchar(100) not null comment '字典名称',
`DictDesc` varchar(4000) comment '字典描述',
`DictReserve1` varchar(4000) comment '保留备用',
primary key (DictId)
);
alter table DictTop comment '字典';
/*==============================================================*/
/* Table: OrderPdt */
/*==============================================================*/
create table OrderPdt
(
`OrderPdtId` int not null auto_increment comment '订单商品编号',
`Id` int not null comment '编号',
`UserId` int not null comment '用户编号',
`OrderId` int comment '订单号',
`PdtAmount` int comment '订购数量',
`PdtPrice` decimal comment '单价',
`PdtReserve1` varchar(2000) comment '备用1',
`PdtReserve2` varchar(4000) comment '备用2',
primary key (OrderPdtId)
);
alter table OrderPdt comment '订单商品';
/*==============================================================*/
/* Table: Orders */
/*==============================================================*/
create table Orders
(
`OrderId` int not null auto_increment comment '订单号',
`AddressId` int not null comment '收货地址编号',
`OrderState` int default 1 comment '订单状态',
`ExpressNO` varchar(50) comment '快递编号',
`ExpressName` varchar(50) comment '快递名称',
`PayMoney` decimal comment '应支付',
`PayedMoney` decimal comment '已支付',
`SendInfo` varchar(300) comment '发货人信息',
`BuyDate` timestamp default CURRENT_TIMESTAMP comment '下单时间',
`PayDate` datetime comment '支付时间',
`SendDate` datetime comment '发货时间',
`ReceivDate` datetime comment '收货时间',
`OrderMessage` varchar(4000) comment '附言',
`UserId` integer comment '用户编号',
`OrderReserve1` varchar(4000) comment '备用1',
`OrderReserve2` varchar(4000) comment '备用2',
`OrderReserve3` decimal comment '备用3',
primary key (OrderId)
);
alter table Orders comment '订单';
/*==============================================================*/
/* Table: ProductComment */
/*==============================================================*/
create table ProductComment
(
`ProductCommentId` int not null auto_increment comment '商品评论编号',
`ProductId` int not null comment '商品编号',
`UserId` int not null comment '用户编号',
`ProductCommentContent` varchar(4000) comment '商品评论内容',
`ProductCommentDate` timestamp default CURRENT_TIMESTAMP comment '商品评论时间',
`ProductCommentState` int comment '状态',
`ProductCommentRemark` int comment '打分',
`ProductCommentReserve1` varchar(4000) comment '备用1',
`ProductCommentReserve2` varchar(4000) comment '备用2',
primary key (ProductCommentId)
);
alter table ProductComment comment '商品评论';
/*==============================================================*/
/* Table: Products */
/*==============================================================*/
create table Products
(
`Id` int not null auto_increment comment '编号',
`Name` varchar(200) not null comment '名称',
`SubIdColor` int not null comment '所属颜色',
`SubIdBrand` int not null comment '所属品牌',
`SubIdInlay` int not null comment '所属镶嵌',
`SubIdMoral` int not null comment '所属寓意',
`SubIdMaterial` int not null comment '所属种水',
`SubIdTopLevel` int not null comment '一级分类编号',
`MarketPrice` decimal comment '市场参考价',
`MyPrice` decimal not null comment '玉源直销价',
`Discount` decimal default 1 comment '折扣',
`Picture` varchar(200) comment '图片',
`Amount` int comment '库存量',
`Description` text comment '详细描述',
`State` int default 1 comment '状态',
`AddDate` timestamp default CURRENT_TIMESTAMP comment '上货日期',
`Hang` int comment '挂件',
`RawStone` int comment '赌石',
`Size` varchar(200) comment '尺寸',
`ExpressageName` varchar(100) comment '快递名称',
`Expressage` decimal comment '快递费',
`AllowComment` int default 1 comment '是否允许评论',
`Reserve1` varchar(4000) comment '保留备用1',
`Reserve2` varchar(4000) comment '保留备用2',
`Reserve3` decimal(0) comment '保留备用3',
primary key (Id)
);
alter table Products comment '商品';
/*==============================================================*/
/* Table: Users */
/*==============================================================*/
create table Users
(
`UserId` int not null auto_increment comment '用户编号',
`UserName` varchar(200) not null comment '用户名',
`Password` varchar(512) not null comment '密码',
`Email` varchar(100) not null comment '邮箱',
`Sex` varchar(10) comment '性别',
`State` int default 1 comment '状态',
`RightCode` int comment '权限状态',
`RegDate` timestamp default CURRENT_TIMESTAMP comment '注册时间',
`RegIP` varchar(200) comment '注册IP',
`LastLoginDate` datetime comment '最近登录时间',
`UserReserve1` varchar(4000) comment '保留备用1',
`UserReserve2` varchar(4000) comment '保留备用2',
`UserReserve3` varchar(4000) comment '保留备用3',
primary key (UserId)
);
alter table Users comment '用户';
alter table Address add constraint FK_AddressBelongUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table ArticleComment add constraint FK_ArticleCommentForArticle foreign key (ArticleId)
references Articles (ArticleId) on delete restrict on update restrict;
alter table ArticleComment add constraint FK_ArticleCommentForUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table Articles add constraint FK_ArticleBelongType foreign key (ArticleTypeId)
references ArticleType (ArticleTypeId) on delete restrict on update restrict;
alter table DictSub add constraint FK_BelongDict foreign key (DictId)
references DictTop (DictId) on delete cascade on update cascade;
alter table OrderPdt add constraint FK_BelongOrder foreign key (OrderId)
references Orders (OrderId) on delete cascade on update cascade;
alter table OrderPdt add constraint FK_CartForUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table OrderPdt add constraint FK_OrderDepProduct foreign key (Id)
references Products (Id) on delete restrict on update restrict;
alter table Orders add constraint FK_OrderBelongAddress foreign key (AddressId)
references Address (AddressId) on delete restrict on update restrict;
alter table ProductComment add constraint FK_ProductCommentBelongUsers foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table ProductComment add constraint FK_ProductCommentForProduct foreign key (ProductId)
references Products (Id) on delete restrict on update restrict;
alter table Products add constraint FK_BelongBrand foreign key (SubIdMaterial)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongColor foreign key (SubIdBrand)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongInlay foreign key (SubIdInlay)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongMaterial foreign key (SubIdColor)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongMoral foreign key (SubIdTopLevel)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongTopLevel foreign key (SubIdMoral)
references DictSub (SubId) on delete restrict on update restrict;로그인 후 복사
六、下载程序、帮助、视频
MySQL安装包
1시간 안에 MySQL 데이터베이스 배우기
MySQL视频教程
文档中没有您可以查帮助:
图7:1시간 안에 MySQL 데이터베이스 배우기
|


















 7491
7491
 15
15
 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
 Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
 MariaDB 용 Navicat에서 데이터베이스 비밀번호를 보는 방법은 무엇입니까?
Apr 08, 2025 pm 09:18 PM
MariaDB 용 Navicat에서 데이터베이스 비밀번호를 보는 방법은 무엇입니까?
Apr 08, 2025 pm 09:18 PM
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
 Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
 Navicat에서 SQL을 실행하는 방법
Apr 08, 2025 pm 11:42 PM
Navicat에서 SQL을 실행하는 방법
Apr 08, 2025 pm 11:42 PM